
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We propose the Minimum Regularized Covariance Trace (MRCT) estimator, a novel method for robust covariance estimation and functional outlier detection designed primarily for dense functional data. The MRCT estimator employs a subset-based approach that prioritizes subsets exhibiting greater centrality based on the generalization of the Mahalanobis distance, resulting in a fast-MCD type algorithm. Notably, the MRCT estimator handles high-dimensional datasets without the need for preprocessing or dimension reduction techniques, due to the internal smoothening whose amount is determined by the regularization parameter . The selection of α is automated. An extensive simulation study demonstrates the efficacy of the MRCT estimator in terms of robust covariance estimation and automated outlier detection, emphasizing the balance between noise exclusion and signal preservation achieved through appropriate selection of α. The method converges fast in practice and performs favorably when compared to other functional outlier detection methods.
1 Introduction
The analysis of functional data is becoming increasingly important in many fields, including medicine, biology, finance, and engineering, among others. Functional data are characterized by measurements that are taken over a continuum, such as time or space, and are often modeled as curves or surfaces. One important aspect of functional data analysis is the estimation of the covariance structure, as it holds significance across different tasks like smoothing, regression, and classification. However, the estimation of the covariance structure for functional data is challenging, especially in the presence of outliers or other sources of noise. Traditional covariance estimators, such as for example the sample covariance, are sensitive to outliers and may produce unreliable results. Therefore, the development of robust covariance estimators that can handle outliers and other types of noise is an active area of research in functional data analysis.
Several robust covariance estimators have been proposed for functional data in the literature. These estimators are based on different approaches, such as trimming, shrinkage, or rank-based methods, and they aim to produce estimates that are less sensitive to outliers and can further be combined with outlier detection techniques to identify functional outliers and improve the overall quality of the analysis; see for example Boente and Salibián-Barrera (Citation2021), Locantore et al. (Citation1999), Cuevas, Febrero, and Fraiman (Citation2007), Gervini (Citation2008), and Sawant, Billor, and Shin (Citation2012). In this article, we propose a novel robust covariance estimator based on a trimmed-sample covariance, designed primarily for dense functional data. The approach is motivated by the multivariate trimmed covariance estimator chosen such that it minimizes the Kullback-Leibler divergence between the underlying data distribution and the estimated distribution. The article is structured as follows: Section 2 introduces notation and important properties of the covariance operator in the Hilbert space of square-integrable functions on an interval. Section 3 motivates and introduces the proposed MRCT estimator, followed by a discussion on its algorithmic aspects in Section 4. We evaluate the performance of the estimator through the simulation study detailed in Section 5 for Gaussian random processes, and in supplement Section E for t-distributed processes (see e.g., Bånkestad et al. Citation2020), and white noise. A real-data analysis is given in Section 6. The proofs of technical results are available in supplement Section C.
2 Notation
Let X be a random function on , that is the Hilbert space of square-integrable functions over the interval I. Denote
to be the mean of X, where for the simplicity of the notation, we assume that μ = 0. Let further
be the corresponding covariance operator defined by
, for
,
. In continuation, we will drop the argument t, as the summation and multiplication of functions are naturally defined element-wise.
We denote and
to be the ith eigenfunction and eigenvalue of C, respectively, that is,
for
. Thus, C admits the spectral decomposition
where the convergence of the partial sums is in the operator norm. It can be shown that C is a trace-class operator, implying that
(Ramsay and Silverman Citation1997). Let further
be a functional random sample from
. For the subset
,
we define
to be the trimmed sample mean, covariance, and non-centered covariance operators, respectively, calculated at the subset H. We denote further
to be the i-th eigenfunction of
, with the corresponding eigenvalue
, that is,
,
. It can then also be shown that
is a trace-class operator admitting an eigendecomposition
. For more details on important properties of the covariance operator in the Hilbert space
see Section A in the supplement.
3 Minimum Regularized Covariance Trace Estimator
3.1 Motivation
In the multivariate setting, given the random sample from a distribution with mean
and covariance
, one approach to robustify the estimation of the mean and the covariance is to use the weighted sample estimators, which assign different weights,
, to different data points based on their relative importance. In this approach, outlying or noisy data points ought to be given smaller weights, thus, reducing their impact on the estimated mean and covariance. Especially, choosing weights
, with the constraint
, for some fixed
, yields trimmed mean and covariance estimators. One of the most widely used members of this class of estimators is the so-called Minimum Covariance Determinant (MCD) estimator (Rousseeuw and Driessen Citation1999). For a given fixed number h, which is roughly half of the sample size n, its objective is to select h (out of n) observations for which the calculated sample covariance matrix has the lowest determinant. In the parametric family of distributions parameterized by its mean and covariance, we employ a similar strategy, however, with the objective to minimize the Kullback-Leibler (KL) divergence between the theoretical (underlying data distribution) and the one parameterized by the estimates of mean and the covariance, using corresponding sample estimates calculated at a subset
. The KL divergence between continuous distributions P and Q with densities fP and fQ, respectively, denoted as
, is a measure of how far the probability distribution P is from a second, reference probability distribution Q Kullback and Leibler (Citation1951) and Kullback (Citation1959). Assume now the data
originate from a normal distribution
, and denote
and
to be the mean and the covariance of
. Denote further
to be the “non-centered” covariance of an h-subset H. The KL divergence between
and
is
(1)
(1) see Zhang et al. (Citation2023) for more details. As the calculation of (1) in practice involves the estimation of the density function, direct use of KL divergence is usually mitigated by the use of appropriate approximations; see for example Blei, Kucukelbir, and McAuliffe (Citation2017) for more details. Observe, therefore, that
, where
represents the covariance of standardized observations
. For
we have that
, indicating that any strongly consistent estimator of
admits the representation
, where
is a unit-norm p × p matrix and
. This holds in particular for the consistent estimator
, for some unit-norm p × p matrix
. A slight modification of Jacobi’s formula implies that the directional derivative of the determinant in the direction of
evaluated at the identity equals the trace of
, that is
. Matrix determinant lemma (Lemma 1 in Ding and Zhou (Citation2007)) gives that
, where for a regular square matrix A,
denotes adjugate of A. Furthermore, the normality of the sample y along with the consistency of the sample covariance estimator
ensure that we can bound
, where
, for
. Applying further the first order Taylor expansion of
around the identity yields that
This result implies that for sufficiently large n, the determinant of the consistent estimator of the covariance of the standardized observations is arbitrarily well approximated by its trace. Thus, instead of directly minimizing over all subsets
, we consider the following optimization problem
(2)
(2) where
is a non-centered covariance of standardized observations
. The corresponding estimators
and
of the covariance and the mean are referred to as multivariate Minimum Covariance Trace (MCT) estimator of the mean and the covariance, respectively. It should be noted that the strategy of minimization of an approximation does not necessarily yield a solution close to the target one. Specifically, even though the KL divergence (1) and the appropriate monotonically increasing transformation of an approximated trace loss (2) are arbitrarily close to each other, optimal subsets based on these two losses could be different. However, Section B.1 in the supplement provides reassurance that the likelihood of such an event is negligible.
The optimization problem (2) highlights the need for an appropriate standardization of the data when extending this approach to more general spaces, with the standardization ensuring that the norm of the standardized object reflects a specific dissimilarity measure of the object from its corresponding mean. In the multivariate setting, the norm of the standardized observations corresponds to the Mahalanobis distance of
, while in the functional setting, an appropriate standardization will result in a random function whose norm equals the α-Mahalanobis distance (3.1) introduced in Berrendero, Bueno-Larraz, and Cuevas (Citation2020). Before delving into the functional setting, let us address the limitations of using the trace of raw observations as an objective function.
Remark 3.1.
For non-standardized data, the approach prioritizes observations with the smallest Euclidean distance from the center of the data cloud, introducing a significant bias toward selecting spherical data subsets for covariance estimation. Conversely, when the data originate from a spherical distribution or at least demonstrate an “approximate” spherical behavior, this bias tends to diminish. In such cases, the method naturally aligns with the data’s inherent spherical nature. It should be noted that, in practice, standardization often results in data having heavier tails than the original ones. However, for a large enough sample size, this effect is negligible. For more insights, see the proof of Corollary 3.1.
3.2 Tikhonov Regularization
As indicated in Section 3.1, the extension of the optimization problem (2) involves defining a standardization of a random function . We therefore proceed by finding the standardized
, such that it approximately solves
, where
is a symmetric squared root of the symmetric operator C;
, for all
. In general, the problem has no solution in
as C is not invertible. We thus employ regularization to the corresponding ill-posed linear problem, via classical Tikhonov regularization with a squared L2-norm penalty. In more formal terms, given the regularization parameter
, the α-standardization of the zero-mean random function
, with covariance operator C, is defined as a solution to the optimization problem
(3)
(3)
The Tikhonov regularization problem (3) admits a closed-form solution as see Cucker and Zhou (Citation2007) for more details. By the spectral theorem for compact and self-adjoint operators, we have
further giving
where, λj and ψj,
are the eigenvalues and the eigenfunctions of C, respectively. The covariance operator
of
is then
, and due to the considerations above it allows the representation
, where
; for illustration of the relation between α and
see , supplement. Furthermore, Parseval’s identity implies
3.3 Connection to the Reproducing Kernel Hilbert Space
In an attempt to generalize the concept of the Mahalanobis distance for the functional data in , Berrendero, Bueno-Larraz, and Cuevas (Citation2020) proposed to first approximate the random function
with the one in the RKHS
such that the approximation is “smooth enough”. More precisely, for
and a regularization parameter
, define
admitting a closed-form solution
, where
Berrendero, Bueno-Larraz, and Cuevas (Citation2020) then define the α-Mahalanobis distance between
as in Definition 3.1.
Definition 3.1.
Given a constant , the α-Mahalanobis distance (w.r.t. covariance C) between X and Y in
is defined by
where
and
are as defined above.
The C-norm of a regularized RKHS approximation of X has the form
. Combining this with the fact that
yields
where, without loss of generality, we assume
.
Adopting the notion of α-Mahalanobis distance as a meaningful dissimilarity measure in this concept, the α-standardization process produces a function in whose L2-norm is indeed equal to such dissimilarity between X and its mean. Thus, for solution
of (3), the generalization of the optimization problem (2) is given by
(4)
(4) where
is the non-centered, trimmed sample covariance of the α-standardized observations
. For simplicity of the notation, we will drop the argument X if the (non-centered) covariance is calculated at the original sample.
In practice, in the α-standardization process, the true mean and the covariance operator are unknown. Therefore, we tackle the problem by iteratively replacing them with their current robust estimates, thus, yielding an implicit equation for obtaining the optimal subset
(5)
(5) where
for
. The corresponding estimators
and
are referred to as Minimum Regularized Covariance Trace (MRCT) estimators of the mean and the covariance, respectively.
is the corresponding scaling factor calculated under the assumption of the Gaussianity. In continuation, in order to emphasize the dependency of
on k, we write
. EquationEquation (5)
(5)
(5) implies that we search for the h-subset H0 used in the estimation of the covariance operator in the set of fixed points of a function
Lemma 3.1 states that f indeed has at least one fixed point.
Lemma 3.1.
Let be the set containing all h-subsets of
and define
with
. Then f has at least one fixed point.
To estimate the scaling factor of
, we employ the strategy used in Rousseeuw (Citation1984), thus, matching the median of the obtained squared α-Mahalanobis distances with the median of the corresponding limiting distribution, under the assumption of Gaussianity, noting that the assumption of Gaussianity of an underlying process is not a requirement, yet simply a convenience that allows us to estimate the scale of the estimated covariance as well as the cutoff value for the outlier detection; a similar approach is used for example in Rousseeuw and Driessen (Citation1999). For that purpose, we use the following result.
Corollary 3.1.
Let be a Gaussian random process and let
and
, as
be strongly consistent estimators of the covariance operator C and the mean μ = 0, respectively. Then, for
converges in distribution to
, where Yi,
are independent
random variables and λi,
are eigenvalues of C.
Corollary 3.1 implies that can be estimated by matching the sample median of the squared α-Mahalanobis distances (i.e.,
) with the estimate of the theoretical median of the weighted sum of independent
random variables, as described in the result. As the eigenvalues
, of the true covariance are unknown, we instead use the eigenvalues
of the current robust estimate
of the covariance operator and choose the scaling parameter k such that
(6)
(6) where
, are mutually independent.
4 Algorithm
In practice, one does not observe smooth functions, but rather discrete sets of the underlying function values . If
and
for all
, and
, we say that the data is observed on a regular grid. Although there is no precise definition for “dense” functional data, it is conventionally understood that functional data are considered densely sampled when the quantity pi,
tends to infinity rapidly enough. If that is the case, then the functional inner products can be approximated by the corresponding integral sums, where the accuracy of the approximation depends on p; see for example, Ostebee and Zorn (Citation2002) for more details on integral approximations. Given that the data are densely observed, robust estimates of mean and covariance can be approximated empirically at the observed times ti,
. Given
, the strategy for finding the solution to (5) is presented in Algorithm 1. Robust estimates of the mean and covariance operator on the entire interval I can then for example be obtained by smooth interpolation of the corresponding robust sample estimates (Wang, Chiou, and Mueller Citation2015). A smooth interpolation of the obtained robust estimates is beyond the scope of this article; see for example Berkey et al. (Citation1991) and Castro, Lawton, and Sylvestre (Citation1986) for more insight on FDA for regularly sampled data on a dense grid.
Algorithm 1:
MRCT algorithm
Input: Sample observed at p time points, an initial subset
with
, regularization parameter
, and the tolerance level
;
1 do
2 ;
3 ;
4 ;
5 do
6 ;
7 Calculate H0--standardized observations
;
8 Calculate ;
9 ;
10 while ;
11 Order ;
12 Set ;
13 while ;
Output: Subset H1, robust squared α-Mahalanobis distances
4.1 MRCT for Data Expressed in a Fixed Basis
On the other hand, as argued in Basna, Nassar, and Podgórski (Citation2022), often the fundamental step in FDA is to convert this discretely recorded data to a functional form, allowing for each observed function to be evaluated at any value of its continuous argument . Typically, a functional object is approximately represented as a linear combination of a finite number of suitable basis functions, where the appropriate representation is exact only for the finite-rank functions. Such an approach is especially needed in cases when the integral-sum approximation of the inner and outer products in Algorithm 1 yield estimates with large approximation error, as is the case when the data are not very densely sampled. Assuming the data are sampled on a regular grid, we approximate each observed datum
, by its rank-M approximation
expressed in a fixed, common basis
, as
(7)
(7) where C is a matrix of coefficients in the expansion. For simplicity of the notation, in continuation, we drop the superscript M, and write
. Then,
, where
is a vector of ones. The number of basis functions M is chosen individually for a given dataset, however, usually in a way that the functional approximations are close to the original observations, with some smoothing that eliminates most of the noise. The choice of the basis is important, and common choices include polynomials, wavelets, spline, and Fourier bases, among others; for an overview, see for example Ramsay and Silverman (Citation1997), Kokoszka and Reimherr (Citation2017). Note that
is not necessarily an orthonormal basis, for example B-splines (see e.g., Eilers and Marx Citation1996; Ferraty and Vieu Citation2007) is a common choice.
Denote , where
, to be a regular, symmetric matrix, due to the linear independence of
. For
, making
well-defined and orthonormal. EquationEquation (7)
(7)
(7) can then be rewritten as
(8)
(8) where
is the matrix of coefficients in the expansion using new, orthonormal bases
. This indicates that we can, without loss of generality, assume that the basis is orthonormal, that is
, and in the continuation, we proceed by assuming so. Once the data is represented as in (8), one might sample the smoothened functions on an arbitrarily dense grid and proceed with an algorithm as in the case where the underlying functions are observed on a regular, dense grid. However, the following proposition indicates that it is not necessary and that we can proceed to work solely with the matrix of coefficients C, thus, lowering the computational cost and minimizing the approximation error.
Proposition 4.1.
Let be an orthonormal basis, and let Xi,
admit a representation as in (7), with
being the matrix of coefficients. Then, for any subset
the following is true:
Let
be the ith eigenfunction of
The ith eigenvalue
The squared α-Mahalanobis distance of Xi allows for a representation
where
When the number of basis functions exceeds h, the becomes singular (
). However, augmenting
with
(
) as
ensures its regularity. This permits the use of a large number of basis functions, thereby reducing the impact of the specific choice of the basis. An adaptation of Algorithm 1 for the case where the data are represented in a finite orthonormal basis is given in Algorithm 1 in the supplement, while the approach is demonstrated in Example 6.2.
4.2 Initialization and Selection of the Optimal Subset
4.2.1 Random Initialization
The output of the MRCT algorithm is a (possibly not unique) solution to the implicit Equationequation (5)(5)
(5) , which further provides a range of options for selecting the optimal robust covariance and α-Mahalanobis distance estimators. Denoting
, to be the set of all such solutions, we define the optimal subset
as the member of
having the smallest total variation, that is
(9)
(9)
This strategy is by no means the only one, and in the supplement Section B.3 we provide an alternative, data-driven approach for choosing the optimal subset.
Supplement Figure 3 indicates that the proposed method is rather robust to the initial approximation. Consequently, the choice of an optimality criterion for has little influence on the final outcome, including the covariance estimate and outlier detection.
4.2.2 Fixed Initialization
In order to eliminate the randomness caused by the random initialization of the MRCT algorithm, we propose an alternative, deterministic initialization. First, one centers the data sample using the point-wise median function. Then, the functions used in the initial subset are those that have the smallest integrated square distance from the point-wise median. A similar approach was used by Hubert, Rousseeuw, and Verdonck (Citation2012) and Billor, Hadi, and Velleman (Citation2000). in the supplement indicates that the approach gives similar results when compared to the multiple random initializations, while at the same time lowering the computational cost. Thus, in the simulation study in Section 5 and in the numeric examples, we use this initialization strategy. Finally, Lemma 4.1 provides the computational complexity of one iteration of the MRCT Algorithm 1 using the fixed initialization.
Lemma 4.1.
For the random sample the following claims hold:
The computational complexity of finding the median-ISE optimal initial approximation is
Given the fixed initialization, the computational complexity of one iteration of Algorithm 1 is
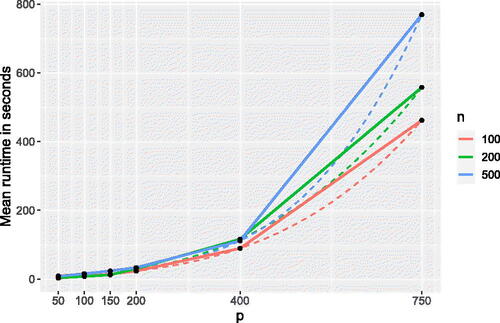
Although Lemma 4.1 gives the computational complexity of one iteration of the algorithm, numerical experiments indicate that the method converges in small number of steps, indicating that the complexity of Algorithm 1 is approximately the same; see .
Fig. 1 Mean runtime (in seconds) over 50-runs of MRCT algorithm for Model 2 in simulation study 5, for the sample size , as a function of a number of the observed time points
. Dotted lines represent the fitted cubic curve to the mean runtime as a function of p.
4.3 Selection of the Regularization Parameter α and the Subset Size h
Remark 3.1 argues that the use of the trace of the covariance of non-standardized observations as an objective results in spherically-biased subsets, where such an obstacle is mitigated by first standardizing the multivariate data so that the obtained covariance is proportional to the identity. As no random function in has an identity covariance, the approach is to choose α such that the eigenvalues of
are either as close to 0 (for the lower part of the spectrum), or as close to some nonzero value, making them also mutually as close together as possible (for the upper part of the spectrum). The approach amounts to minimizing the noise in the data, while at the same time making all the signal components “equally important”; for an illustration see in the supplement. On the sample level, for fixed
and the robust estimate of the covariance
, we first calculate
, where
is the ith eigenvalue of
,
. Next, we search for a partition
, such that
where
. Observe first that as
, and due to the monotonicity of
, ordering is preserved for the standardized eigenvalues.
, giving
, and further implying
and
. Thus, for any
, there exists
, such that
, implying that the set S1 is finite, and the problem of finding an optimal partition amounts to finding
such that
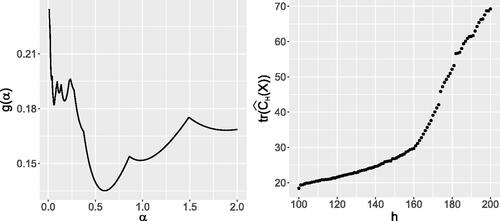
Fig. 2 A typical trajectory of the objective for selecting α for Model 1 in the simulation study in Section 5 (left). The objective in (9) as a function of subset size
, corresponding to the setting on the left and
. A sudden increase around h = 160, caused by the first outliers being included in the subset.
Finally, we search for , where
(10)
(10) see left plot of for illustration.
The approach is to optimize g iteratively starting with an initial value of α0. For an initial α0, robust estimates of eigenvalues of C are calculated and the value of the objective function g is approximated for each α considered in the optimization. The optimal α found that way is then used for re-estimation of the robust eigenvalues of C. The following proposition establishes continuity of the Algorithm 1 w.r.t. α, reassuring that the optimization of (10) over the discrete grid yields notably effective results. More specifically, for close enough (so that the ordering of the Mahalanobis distances in STEP 8 of Algorithm 1 is preserved), given the same initial estimate H0, using either α1 or α2 produces the same updated subset H1.
Proposition 4.2.
Let , and let
and
be the H0-subset sample estimators of the covariance operator C and mean μ = 0, respectively. Then, for every
, there exists
, such that for
.
The process is repeated until convergence; for more technical details see Algorithm 2 in the supplement. In the simulation study (Section 5) we use the initial for p < n (see simulation study in Berrendero, Bueno-Larraz, and Cuevas (Citation2020) for more insight), and
, for p > n, emphasizing that we noticed how the initial value of α0 has little to no effect on the output of Algorithm 2. For the sake of the numerical stability of the procedure, the additional constraint is posed on α, ensuring that the condition number of
is smaller than 100; for more insight see Boudt et al. (Citation2020).
Finally, we provide some thoughts about the choice of the subset size h. It is clear that the number of contaminated samples should be smaller than n–h, and that h should at least be to obtain a fit to the data majority. Therefore, the choice of h is a tradeoff between the robustness and efficiency of the estimator; see discussion in Rousseeuw (Citation1984) for more details. In practice, the proportion of outliers is, in general, not known in advance, and thus we consider a data-driven approach for the choice of h, as suggested by Boudt et al. (Citation2020): one considers a range of possible values for h to search for significant changes of the computed value of the objective function or the estimate. Big shifts in the norm of the difference between the subsequent covariance estimates, as well as those in the value of the trace of the corresponding covariance based on the consecutive subset sizes, can imply the presence of outliers; see the right plot of for illustration.
5 Simulation Study
This section evaluates the MRCT Algorithm 1 through a simulation study similar to those in Berrendero, Bueno-Larraz, and Cuevas (Citation2020) and Arribas-Gil and Romo (Citation2014). The methods compared to MRCT fall into three categories: those relying on functional depths, employing functional principal components, and based on the Mahalanobis distance and its functional extension. Supplementary materials and referenced works provide a detailed explanation.
In the simulation, we generate the contaminated data Y(t), using Huber’s ε-contamination model Huber (Citation1964) as
, where
, and contamination rate
. As we observe no significant difference in the results with respect to c, due to the page limit, we present the results only for c = 0.2. The main process X1 and the contamination X2 are random processes chosen according to three different models to accommodate various outlier settings:
where
, ϵi, i = 1, 2 are mutually independent Gaussian random processes with zero mean and covariance functions
and
, respectively, and
are mutually independent, and independent of
. For each model, we generate a random sample of n = 200 observations, with the observations recorded at an equidistant grid on the interval
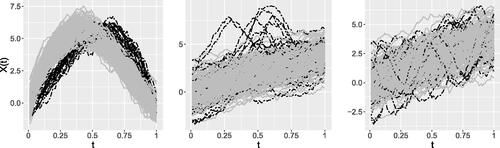
, at p = 100 and p = 500 time points. In the context of multivariate statistics, these are referred to as low- and high-dimensional settings, respectively. provides a visual representation of the simulated data.
Fig. 3 Left to right, samples from Model 1,2, and 3. Solid curves represent the main processes, while the dashed ones indicate the outliers. The contamination rate is c = 0.1, sample size n = 200, and p = 100 time points.
An observation is considered an outlier if its robust α-Mahalanobis distance exceeds the cutoff value derived from the 97.5% quantile of the limiting distribution of these distances, assuming Gaussianity (Corollary 3.1). To estimate this quantile, we conduct a Monte Carlo simulation with 2000 repetitions. To measure the accuracy of the robust covariance estimator, we use the approximation of integrated square error (ISE) and the average cosine of an angle between the first 5 corresponding eigenfunctions of the estimates and true covariances (COS ). More specifically, given the sample estimate
of the covariance function γ of the non-contaminated process
. For each method,
is a sample covariance estimator calculated at the identified non-outliers. Denoting ψi,
, to be the ith eigenfunction of the population covariance C and the estimated covariance
, respectively, where the estimated covariance is based on the identified regular observations, COS
, where COS
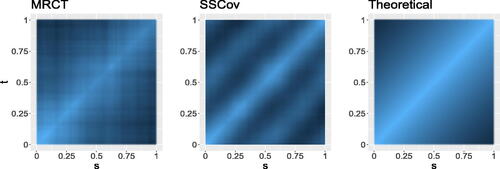
. showcases heatmaps of the estimated covariances based on MRCT and SSCov, as well as the true covariance.
Fig. 4 Left to right: heatmaps of the covariance based on the MRCT estimator, the spatial sign covariance matrix, and the true (theoretical) covariance for n = 200 observations on p = 500 time points for Model 3 with a contamination rate of 20%.
The results for the Gaussian process are depicted in , while the analogous results for the white noise, t3, and t5 distributed processes (for more details see e.g., Bånkestad et al. Citation2020) are shown in supplement Figures 6–8. Classification rates for the outlier detection for all settings can be found in Figures 9–12 in the supplement. Additionally, we conducted a simulation study to assess computation times for the considered methods. Results are depicted in supplement Figure 13.
Fig. 5 ISE on a log-scale (top) and COS (bottom). The estimates of covariance are based on identified regular observations for
, and c = 0.2. A solid horizontal line indicates the mean ISE for the sample covariance based on known regular observations as a reference.
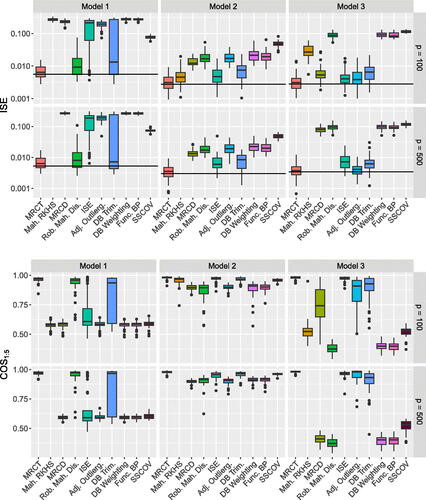
Fig. 6 SST of the Niño 1 + 2 region in the Pacific Ocean. Smoothened regular observations are depicted in gray, while outliers are represented by colored markers. The black dots in the right figure indicate the specific points in time when El Niño events were detected solely using past information, excluding 1982–1984 for the lack of past information.
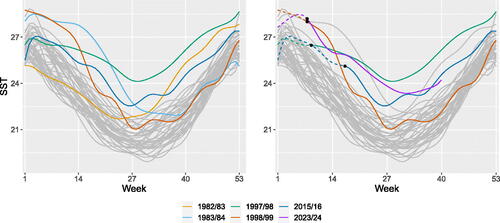
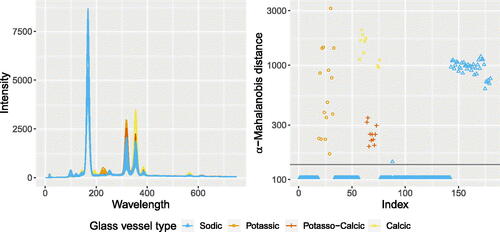
Fig. 7 Left: Spectrum of different glass vessel types. Right: Robust α-Mahalanobis distance on a log-scale. The horizontal line indicates the theoretical cutoff value.
6 Real Data Examples
6.1 Sea Surface Temperatures
The algorithm is applied to two real-world datasets, starting with an example of the El Niño-Southern Oscillation (ENSO) phenomenon in the equatorial Pacific Ocean. ENSO involves ocean surface warming known as El Niño and cooling known as La Niña, impacting global weather (Trenberth Citation1997). The Oceanic El Niño Index (ONI) identifies ENSO events using 3-month sea surface temperature means. For analysis, the Niño 1 + 2 region near South America is considered, using weekly sea surface temperature (SST) data from March 1982 to February 2023, resulting in a 41 × 53 data matrix sourced from https://www.cpc.ncep.noaa.gov/data/indices/. The objective is to identify atypical behavior in the yearly sea surface temperature, indicating the presence of an El Niño event. The regularization parameter is selected using Algorithm 2 in the supplement. The subset size h is fixed at
. The identified outliers are depicted in , and correspond to the seasons of 1982/83, 1983/84, 1997/98, 1998/99, and 2015/16. These seasons are associated with some of the strongest El Niño events, and align with findings from referenced methods such as Huang and Sun (Citation2019) and Suhaila (Citation2021).
The dataset was additionally supplied to the other methods from Section 5. Depth-based trimming and weighting, and the robust Mahalanobis distance find the same periods to be outlying as the MRCT. The functional boxplot and the MRCD detect 1983/84 and 1997/98, the integrated square error detects 1983/84 and 1998/99, while the adjusted outliergram only detects 1983/84 to be outlying.
We examine the possibility of forecasting them using past-year data. Our analysis involves 46 datasets: first, focusing on the initial 8 weeks (March–April), and then expanding to include additional weeks. Specifically concentrating on post 1982 episodes: 1997/98, 1998/99, and 2015/16, we handle limited data by employing smoothing techniques; see Section 4.1, using up to 15 B-spline basis functions, adjusted according to available weeks.
The findings in display results obtained from analyzing smoothed data. For the 1997/98 episode, the outlying behavior emerges in early May, marked by a black dot and leading to a change in curve style. Analyzing the initial 8 weeks’ temperatures promptly identifies 1998/99 observations as outliers due to sustained above-average sea surface temperatures. The 2015/16 El Niño exhibits distinct patterns, thus, being identified as an outlier by the end of June. Additionally, an investigation of the current season, 2023/24, was conducted. Using the first three quarters of data available for all years, indications point to an impending El Niño event. This is represented by the purple curve in .
6.2 EPXMA Spectra
The dataset comprises electron probe X-ray microanalysis (EPXMA) spectra of various glass vessel types, with the objective of studying the production and trade relationships among different glass manufacturers (Janssens et al. Citation1998). A total of 180 observations were recorded for 1920 wavelengths. Our focus is on the first 750 time points, as they encapsulate the primary variability within the data. The data comprises four distinct types of glass vessels. The primary group, referred to as the “sodic” group, encompasses 145 observations. The remaining three groups are denoted as “potassic,” “potasso-calcic,” and “calcic,” consisting of 15, 10, and 10 measurements, respectively. Further investigation revealed that some of the spectra within the sodic glass vessels were recorded under different experimental conditions. More details regarding the different glass types can be found in Lemberge et al. (Citation2000). The corresponding curves are depicted in the left plot of .
For this analysis, we consider the sodic group (excluding the last 38 deviating trajectories) as the reference, and consider the remaining curves outliers. The subset size h is set to and the regularization parameter α is chosen using Algorithm 2, resulting in
. In (right), robust α-Mahalanobis distances are visualized, with color indicating the data’s group structure. The vertical black line represents the theoretical cutoff Corollary 3.1. This analysis successfully pinpointed outliers in the second, third, and fourth group, as well as in the curves from the reference group following the measuring device change.
presents outlier detection results for the methods in the simulation study, excluding Adjusted Outliergram and MRCD due to numerical issues. Integrated square error closely aligns with MRCT’s performance, while robust Mahalanobis distance and depth-based weighting seem overly conservative, leading to missed outliers as observed in the simulation study. The table also shows counts of outlying observations per group, highlighting instances where methods miss-classified observations due to cutoff extremes.
Table 1 True positive and true negative rates for different methods as well as the number of observations considered outlying within the each group.
7 Summary and Conclusions
In this article, we presented the minimum regularized covariance trace (MRCT) estimator, a novel method for robust covariance estimation and functional outlier detection. To handle outlying observations, we adopted a subset-based approach that favors the subsets that are the most central w.r.t the corresponding covariance, and where the centrality of the point is measured by the α-Mahalanobis distance (3.1) Berrendero, Bueno-Larraz, and Cuevas (Citation2020). The approach results with the fast-MCD Rousseeuw and Driessen (Citation1999) type algorithm, in which the notion of standard Mahalanobis distance is replaced by α-Mahalanobis distance. Consequentially, the robust estimator of the α-Mahalanobis distance is obtained, thus, further allowing for robust outlier detection. The method automates outlier detection by providing theoretical cutoff values based on additional distributional assumptions. An additional advantage of our approach is its ability to handle datasets with a high number of observed time points () without requiring preprocessing or dimension reduction techniques such as smoothing. This is a consequence of the fact that the
is a smooth approximation (obtained via the Tikhonov regularization) of the solution Y of the ill-posed linear problem
, where the amount of smoothening is determined by a (univariate) regularization parameter
. Therefore, a certain amount of smoothening is in fact done within the procedure itself. Additionally, the selection of the regularization parameter α is automated to obtain a balance between noise exclusion and preservation of signal components.
As a part of future research, we will study the behavior and efficacy of different variants of Tikhonov regularization. While our article focused on the “standard form” with a simple smoothness penalty of , future investigations could encompass a broader scope of penalizations of the form
, where L represents a suitable regularization operator; see for example Golub, Hansen, and O’Leary (Citation1999). Another avenue for exploration lies in extending the approach to accommodate the case of multivariate functional data.
Supplementary Materials
The supplementary materials consist of five sections. Sections A and B cover preliminary results in Functional Data Analysis (FDA), and additional findings not presented in the main text. Section C and D provide extra simulation results and algorithmic routines, respectively. Section E comprises the proofs. The R-code for reproducing the shown results is also available in the supplementary materials.
Disclosure Statement
The authors report there are no competing interests to declare.
Additional information
Funding
References
- Arribas-Gil, A., and Romo, J. (2014), “Shape Outlier Detection and Visualization for Functional Data: The Outliergram,” Biostatistics, 15, 603–619. DOI: 10.1093/biostatistics/kxu006.
- Basna, R., Nassar, H., and Podgórski, K. (2022), “Data Driven Orthogonal Basis Selection for Functional Data Analysis,” Journal of Multivariate Analysis, 189, 104868. DOI: 10.1016/j.jmva.2021.104868.
- Berkey, C. S., Laird, N. M., Valadian, I., and Gardner, J. (1991), “Modelling Adolescent Blood Pressure Patterns and their Prediction of Adult Pressures,” Biometrics, 47, 1005–1018.
- Berrendero, J. R., Bueno-Larraz, B., and Cuevas, A. (2020), “On Mahalanobis Distance in Functional Settings,” Journal of Machine Learning Research, 21, 1–33.
- Billor, N., Hadi, A., and Velleman, P. (2000), “Bacon: Blocked Adaptive Computationally Efficient Outlier Nominators,” Computational Statistics and Data Analysis, 34, 279–298. DOI: 10.1016/S0167-9473(99)00101-2.
- Blei, D. M., Kucukelbir, A., and McAuliffe, J. D. (2017), “Variational Inference: A Review for Statisticians,” Journal of the American Statistical Association, 112, 859–877. DOI: 10.1080/01621459.2017.1285773.
- Bånkestad, M., Sjölund, J., Taghia, J., and Schön, T. (2020), “The Elliptical Processes: A Family of Fat-Tailed Stochastic Processes,” arXiv preprint arXiv:2003.07201.
- Boente, G., and Salibián-Barrera, M. (2021), “Robust Functional Principal Components for Sparse Longitudinal Data,” METRON, 79, 159–188. DOI: 10.1007/s40300-020-00193-3.
- Boudt, K., Rousseeuw, P. J., Vanduffel, S., and Verdonck, T. (2020), “The Minimum Regularized Covariance Determinant Estimator,” Statistics and Computing, 30, 113–128. DOI: 10.1007/s11222-019-09869-x.
- Castro, P. E., Lawton, W. H., and Sylvestre, E. A. (1986), “Principal Modes of Variation for Processes with Continuous Sample Curves,” Technometrics, 28, 329–337. DOI: 10.2307/1268982.
- Cucker, F., and Zhou, D. X. (2007), Learning Theory: An Approximation Theory Viewpoint, Cambridge Monographs on Applied and Computational Mathematics, Cambridge: Cambridge University Press.
- Cuevas, A., Febrero, M., and Fraiman, R. (2007), “Robust Estimation and Classification for Functional Data via Projection-based Depth Notions,” Computational Statistics, 22, 481–496. DOI: 10.1007/s00180-007-0053-0.
- Ding, J., and Zhou, A. (2007), “Eigenvalues of Rank-One Updated Matrices with Some Applications,” Applied Mathematics Letters, 20, 1223–1226. DOI: 10.1016/j.aml.2006.11.016.
- Eilers, P. H. C., and Marx, B. D. (1996), “Flexible Smoothing with B-splines and Penalties,” Statistical Science, 11, 89–121. DOI: 10.1214/ss/1038425655.
- Ferraty, F., and Vieu, P. (2007), “Nonparametric Functional Data Analysis: Theory and Practice,” Computational Statistics & Data Analysis, 51, 4751–4752.
- Gervini, D. (2008), “Robust Functional Estimation Using the Median and Spherical Principal Components,” Biometrika, 95, 587–600. DOI: 10.1093/biomet/asn031.
- Golub, G. H., Hansen, P. C., and O’Leary, D. P. (1999), “Tikhonov Regularization and Total Least Squares,” SIAM Journal on Matrix Analysis and Applications, 21, 185–194. DOI: 10.1137/S0895479897326432.
- Huang, H., and Sun, Y. (2019), “A Decomposition of Total Variation Depth for Understanding Functional Outliers,” Technometrics, 61, 445–458. DOI: 10.1080/00401706.2019.1574241.
- Huber, P. J. (1964), “Robust Estimation of a Location Parameter,” The Annals of Mathematical Statistics, 35, 73–101. DOI: 10.1214/aoms/1177703732.
- Hubert, M., Rousseeuw, P. J., and Verdonck, T. (2012), “A Deterministic Algorithm for Robust Location and Scatter,” Journal of Computational and Graphical Statistics, 21, 618–637. DOI: 10.1080/10618600.2012.672100.
- Janssens, K. H., Deraedt, I., Schalm, O., and Veeckman, J. (1998), “Composition of 15–17th Century Archaeological Glass Vessels Excavated in Antwerp, Belgium,” in Modern evelopments and Applications in Microbeam Analysis, eds. G. Love, W. A. P. Nicholson, and A. Armigliato, pp. 253–267, Vienna: Springer.
- Kokoszka, P., and Reimherr, M. (2017), Introduction to Functional Data Analysis, Chapman & Hall/CRC Numerical Analysis and Scientific Computing, Boca Raton, FL: CRC Press.
- Kullback, S. (1959), Information Theory and Statistics, New York: Wiley.
- Kullback, S., and Leibler, R. A. (1951), “On Information and Sufficiency,” The Annals of Mathematical Statistics, 22, 79–86. DOI: 10.1214/aoms/1177729694.
- Lemberge, P., Raedt, I., Janssens, K., Wei, F., and Van Espen, P. (2000), “Quantitative Analysis of 16-17th Century Archaeological Glass Vessels Using PLS Regression of epxma and μ-xrf data,” Journal of Chemometrics, 14, 751–763. DOI: 10.1002/1099-128X(200009/12)14:5/6<751::AID-CEM622>3.0.CO;2-D.
- Locantore, N., Marron, J. S., Simpson, D. G., Tripoli, N., Zhang, J. T., Cohen, K. L., Boente, G., Fraiman, R., Brumback, B., Croux, C., Fan, J., Kneip, A., Marden, J. I., Peña, D., Prieto, J., Ramsay, J. O., Valderrama, M. J., and Aguilera, A. M. (1999), “Robust Principal Component Analysis for Functional Data,” Test, 8, 1–73. DOI: 10.1007/BF02595862.
- Ostebee, A., and Zorn, P. (2002), Calculus from Graphical, Numerical, and Symbolic Points of View. Number Bd. 2 in Calculus from Graphical, Numerical, and Symbolic Points of View. San Diego, CA: Harcourt College Publishers.
- Ramsay, J. O., and Silverman, B. W. (1997), Principal Components Analysis for Functional Data, New York: Springer.
- Rousseeuw, P. J. (1984), “Least Median of Squares Regression,” Journal of the American Statistical Association, 79, 871–880. DOI: 10.1080/01621459.1984.10477105.
- Rousseeuw, P. J., and Driessen, K. V. (1999), “A Fast Algorithm for the Minimum Covariance Determinant Estimator,” Technometrics, 41, 212–223. DOI: 10.1080/00401706.1999.10485670.
- Sawant, P., Billor, N., and Shin, H. (2012), “Functional Outlier Detection with Robust Functional Principal Component Analysis,” Computational Statistics, 27, 83–102. DOI: 10.1007/s00180-011-0239-3.
- Suhaila, J. (2021), “Functional Data Visualization and Outlier Detection on the Anomaly of el Niño Southern Oscillation,” Climate, 9, 118. DOI: 10.3390/cli9070118.
- Trenberth, K. E. (1997), “The Definition of el Niño,” Bulletin of the American Meteorological Society, 78, 2771–2778. DOI: 10.1175/1520-0477(1997)078<2771:TDOENO>2.0.CO;2.
- Wang, J.-L., Chiou, J.-M., and Mueller, H.-G. (2015), “Review of Functional Data Analysis,” arXiv preprint arXiv:1507.05135.
- Zhang, Y., Liu, W., Chen, Z., Wang, J., and Li, K. (2023), “On the Properties of Kullback-Leibler Divergence between Multivariate Gaussian Distributions,” arXiv preprint arXiv:2102.05485.