
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We consider a new framework where a continuous, though bounded, random variable has unobserved bounds that vary over time. In the context of univariate time series, we look at the bounds as parameters of the distribution of the bounded random variable. We introduce an extended log-likelihood estimation and design algorithms to track the bound through online maximum likelihood estimation. Since the resulting optimization problem is not convex, we make use of recent theoretical results on stochastic quasiconvex optimization, to eventually derive an Online Normalized Gradient Descent algorithm. We illustrate and discuss the workings of our approach based on both simulation studies and a real-world wind power forecasting problem.
Disclaimer
As a service to authors and researchers we are providing this version of an accepted manuscript (AM). Copyediting, typesetting, and review of the resulting proofs will be undertaken on this manuscript before final publication of the Version of Record (VoR). During production and pre-press, errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal relate to these versions also.1 Introduction
Many statistical applications involve response variables that are both continuous and bounded. This is especially the case when one has to deal with rates, percentages or proportions, for example when interested in the spread of an epidemic (Guolo and Varin, 2014), the unemployment rates in a given country (Wallis, 1987) or the proportion of time spent by animals in a certain activity (Cotgreave and Clayton, 1994). Indeed, proportional data are widely encountered within ecology-related statistical problems, see Warton and Hui (2011) among others. Similarly, when forecasting wind power generation, the response variable is also such a continuous bounded variable. Wind power generation is a stochastic process with continuous state space that is bounded from below by zero when there is no wind, and from above by the nominal capacity of the turbine (or wind farm) for high-enough wind speeds. More generally, renewable energy generation from both wind and solar energy are bounded stochastic processes, with the same lower bound (i.e., zero energy production) and different characteristics of their upper bound (since solar energy generation has a time-varying maximum depending on the time of day and time of year), see for example Pinson (2012) and Bacher et al. (2009).
These continuous bounded random variables call for probability distributions with a bounded support such as the beta distribution, truncated distributions or distributions of transformed normal variables as discussed by Johnson (1949). Often, the response variable is first assumed to lie in the unit interval and is then rescaled to any interval
. For applications involving such response variables, these bounds
are always fixed to the same values over the sample. While this assumption makes sense in some cases, we argue it can be misleading and negatively impacts inference when the bounds
actually vary over time or depending on exogenous variables whilst not being observed. In particular, it is highly relevant for energy applications, such as wind power forecasting, as the upper bound b may change over time, while being unknown, e.g., wind curtailment actions were taken and not (reliably) recorded. Another application is the inventory problem of the retailer (Laderman and Littauer, 1953). Let
be the demand for a certain item at time t:
is double-bounded, from below by zero and from above by the stock available at time t, i.e., by a time-varying upper bound
. To prepare for demand
, the retailer needs to find the quantity they should order in light of the knowledge they have of the past stocks and demands. Similar to the problem of forecasting wind power generation, the inventory problem involves a double-bounded random variable, the demand for a certain item, which can be regarded as a continuous variable at large quantities, with an upper bound that may vary over time whilst not being observed, e.g., in case of supply chain issues, information mismanagement or very large retailers that could not track the evolution of the stocks for each item, or would rather benefit from an automatic data-driven tracking.
In both those applications, if the random variable happens to get very close to the upper bound, it might be the case that a higher upper bound would have resulted in a higher wind power generation or item demand than the one that was observed. Therefore, we do not observe the true response. In that sense one could arguably think of it as being related to censoring and truncation. However, while truncation assumes the value of the response variable to be never seen (or recorded) if above the upper bound, and censoring assumes one does not know the exact value but does know it lies above the upper bound, we assume here that an upper bound lower than the true response results in squeezing the observed value of the variable, and thus in reshaping the probability distribution of the variable.
There are at least two ways of looking at varying bounds that cannot be observed. They can be introduced in the model as latent random variables A and B. Hence, the distribution of the response variable is conditional given A and B. The main advantage of this approach is its generality and flexibility, with A and B being distributed according to a well-specified probability distribution, which might depend on exogenous variables. Suppose we assume a parametric model for both the bounds and the response variable. Since we do not have access to the realizations of the bounds, the maximization of the likelihood might involve complicated high-dimensional integration, possibly computationally infeasible, and would therefore call for algorithms of the Expectation-Maximization kind (Dempster et al., 1977). Moreover, for forecasting applications, one needs to first compute (good enough) forecasts of the bounds in order to be able to forecast the response variable.
In the context of stochastic processes, varying bounds that cannot be observed can alternatively be considered as scaling parameters a and b of the parametric distribution of the bounded variable. Hence, a non-stationary framework is to be used for these additional parameters to be able to evolve over time. We will focus in this paper on discrete-time stochastic processes with a varying upper bound. Among the class of distributions with a bounded support, we choose the generalized logit-normal (GLN) distribution introduced by Mead (1965). The practical use of any family of distributions depends on the possible variation in its shape, and on the ease with which the distribution can be fitted. The GLN distribution is very flexible, and because the transformed variable is normally distributed, the probability density function (pdf) of the bounded variable can be expressed as a function of the standard normal density.
We aim to estimate the parameter vector of the pdf of
that includes a bound parameter b through Maximum Likelihood Estimation (MLE). The first challenge we need to tackle when dealing with the bound as a parameter in a non-stationary setup is how to handle past observations that are out of the support
of the bounded distribution of
and make the log-likelihood infinite. We introduce a new term that relies on the sigmoid function to take into account those observations in a soft, finite way. Another challenge is that when considering the bound as a parameter, we cannot assume convexity anymore as the negative log-likelihood appears not to be convex with respect to (w.r.t.) the new bound parameter. Instead, we propose to assume quasiconvexity and use recent results from Hazan et al. (2015) about local quasiconvexity and Stochastic Normalized Gradient Descent (SNGD) to design an online algorithm. We present the statistical parametric model with a varying upper bound in Section 2 and the corresponding MLE in Section 3. In Section 4, we perform simulations of synthetic data to run the algorithm we proposed in Section 3. First we look at the performance when tracking the parameter vector
over time, then when forecasting the probability distribution of the bounded variable. In Section 5, we provide 10-min-ahead probabilistic forecasts of the wind power generation at Anholt offshore wind farm (Denmark) using this new framework. Finally, we discuss the results, the limitations and some prospects of the methodology in Section 6.
2 Statistical model
2.1 Parametric distribution including the new parameter b
Let be a continuous bounded random variable,
, and
be the corresponding variable rescaled to
by applying the transformation
. The generalized logit transform
of
is given by
where is the shape parameter. When
is distributed according to a Gaussian distribution
, the original variable
is then distributed according to a GLN distribution
, see Frederic and Lad (2008) and Pinson (2012). To handle dependent observations, we assume the expectation of
to be an auto-regressive (AR) process of order p,
. Note that successive time points t are assumed to be spaced at uniform intervals. The pdf of
conditional on the previous information set
(the
-algebra generated by
), with parameter vector
, is then
(1)
(1)
where .
2.2 Extended time-dependent log-likelihood function
We wish to estimate the parameter vector of the pdf
in (1) through MLE. In the case of a stationary time series and constant parameter
, this is equivalent to minimizing the negative log-likelihood objective function
(2)
(2)
w.r.t. , the data sample
being fixed, assuming the random variables
are independent and identically distributed (i.i.d.) conditional on
. Note that we do not take into account the distribution of the first p observed values
and consider instead the likelihood conditional on them. For ease of notation and because the negative log-likelihood is to be minimized w.r.t.
, let
. In a non-stationary framework, an estimate of
at time t can be retrieved by minimizing a time-dependent negative log-likelihood, such as
(3)
(3)
where , is an exponential forgetting factor and
if
,
if
, is used to normalize the weighted negative log-likelihood. From (1) we can see that the negative log-likelihood in (2) we wish to minimize takes the value
as soon as an observation
is greater or equal to b. This is an implicit constraint on b when estimating
. However, in a non-stationary framework we do not want b to be greater than all the observations
as b should be able to vary over time. Let
,
and
, the complement of
in
. The log-likelihood takes finite values only for observations
such that
. Therefore we can informally rewrite
as
, where
is the pdf
restricted to its support
. When estimating the parameter vector at time t, we need to take into account all past observations, including the observations for which the log-likelihood does not take a finite value, i.e., including observations
such that j does not belong to
. Therefore, we propose to replace the value 0 in
, which originally corresponds to the value of the pdf
outside of its support, with a sigmoid function of
,
(4)
(4)
The function is illustrated in Figure 1. It can be seen as the probability of
to be lower or equal than b: we have
when
and
when
. Moreover,
is convex and differentiable in b. Hence, we propose to use
(5)
(5)
which we refer to as the extended time-dependent negative log-likelihood. One can note that does not necessarily mean
as it can happen because a lagged observation
is such that
. In such a case, that is
and
, the observation
will still increase the value of the total log-likelihood compared to the event
, which is also a nice feature of using
.
2.3 (Local-)Quasiconvexity
While convexity, or pseudoconvexity, have proved to be suitable assumptions for estimating the parameter vector of a GLN distribution (Pierrot and Pinson, 2021), this is not the case anymore when introducing the bound parameter b. Various simulations of in (5) show the function not to be convex nor pseudoconvex in b, with plateau areas away from the optimal value
and steep concave cliffs in the neighborhood of
. However, the same simulations also suggest that the function may still have a global minimum. There is a broader class of functions that include convex functions as a subclass and are still unimodal functions: quasiconvex functions. For simplicity, let us assume functions are differentiable. We use
to denote the Euclidean norm. From Boyd and Vandenberghe (2010), a definition of quasiconvexity is
Definition 2.1 (Quasiconvexity)
A function is called quasiconvex (or unimodal) if its domain and all its sublevel sets
for , are convex.
As an illustrative example, Figure 2 shows the negative pdf of a normal variable that is a quasiconvex function but not a convex function. While quasiconvexity is a considerable generalization of convexity, many of the properties of convex functions hold or have analogs for quasiconvex functions. However, quasiconvexity broadens but does not fully capture the notion of unimodality in several dimensions. This is the argument of Hazan et al. (2015) that introduced local-quasiconvexity, a property that extends quasiconvexity and captures unimodal functions that are not quasiconvex. Let denote the d dimensional Euclidean ball of radius r centered around
, and
. The definition of local-quasiconvexity as introduced by Hazan et al. (2015) is the following:
Definition 2.2 (Local-quasiconvexity)
Let ,
.
We say that is
-Strictly-Locally-QuasiConvex (SLQC) in
, if at least one of the following applies:
1. .
2. , and for every
it holds that
.
Hence, we propose to relax the convexity (or pseudoconvexity) assumption and instead rely on local-quasiconvexity when minimizing .
3 Online maximum likelihood estimation
3.1 Quasiconvex optimization
Let f be the quasiconvex objective function we wish to minimize w.r.t parameter . It is well known that quasiconvex problems can be solved through a series of convex feasibility problems (Boyd and Vandenberghe, 2010). However, solving such feasibility problems can be very costly and involves finding a family of convex functions
,
, which satisfy
and whenever
. In the batch setup, a pioneering paper by Nesterov (1984) was the first to propose an efficient algorithm, Normalized Gradient Descent (NGD), and to prove that this algorithm converges to an
-optimal solution within
iterations given a differentiable quasiconvex objective function. Gradient Descent (GD) with fixed step sizes is known to perform poorly when the gradients are too small in a plateau area of the function or explode in cliff areas. Among the deep learning community, there have been several attempts to tackle plateaus and cliffs. However, those works do not provide a theoretical analysis showing better convergence guarantees than NGD. Having introduced SLQC functions, Hazan et al. (2015) prove that NGD also finds an
-optimal minimum for such functions within
iterations.
3.2 Online Normalized Gradient Descent
NGD can be used to minimize w.r.t
. However, this implies to run NGD every time we want to update the parameter vector
. Taking advantage of the SLQC assumption, Hazan et al. (2015) presented SNGD, which is similar to Stochastic Gradient Descent (SGD) except they normalize the gradients, and prove the convergence of SNGD within
iterations to an
-optimal minimum. From the observation that online learning and stochastic optimization are closely related and interchangeable (see, e.g., Cesa-Bianchi et al. (2004) and Duchi et al. (2011)), we use the Stochastic Normalized Gradient Descent (SNGD) introduced by Hazan et al. (2015) and derive the corresponding Online Normalized Gradient Descent (ONGD) for online learning. ONGD is presented in Algorithm 1. To the best of our knowledge, this is the first time SNGD is used in an online learning fashion for Online Quasiconvex Optimization.
Algorithm 1 Online Normalized Gradient Descent (ONGD)
Input: convex set , step size
, minibatch size mfor
do
Play and observe cost
.
Update and project:
end for
Following the framework introduced by Cesa-Bianchi and Lugosi (2006), we define ONGD in terms of a repeated game played between the online players and the environment generating the outcome sequence. At each time t, we play a parameter vector . After we have committed to this choice, a cost function
is revealed and the cost we incur is
, the value of the cost function for the choice
. Similar to Online Gradient Descent (OGD), which is based on standard gradient descent from offline optimization and was introduced in its online form by Zinkevich (2003), we have included in ONGD a projection step
. Indeed, in each iteration, the algorithm takes a step from the previous point in the direction of the normalized gradient of the previous cost. This step may result in a point outside of the underlying convex set
. In such cases the algorithm projects the point back to the convex set
, i.e. finds its closest point in
. SNGD requires the gradient to be estimated using a minibatch of minimal size m. Indeed, Hazan et al. (2015) provide a negative result showing that if the minibatch size is too small then the algorithm might diverge. This is where SNGD differs from SGD as in the latter and for the case of convex functions even a minibatch of size 1 is enough to ensure convergence.
GD methods update the current value of a parameter by taking a step in a descent direction, according to the gradient of the cost function f over a complete set of observations:
(6)
(6)
where i is the current iteration and the step size at iteration i. Online/stochastic GD is obtained by dropping the averaging operation in (6) and updating the parameter
according to
(7)
(7)
where has been chosen randomly for SGD and
are successive observations for OGD. The simplification relies on the hope that the random noise introduced by this procedure will not compromise the average behavior of the algorithm. Let
and
. Hence, ONGD can be applied to our framework by taking
When minimizing w.r.t , we shall recover positive estimates of the scale parameter
and the shape parameter
. This is constrained optimization that can be easily overcome by replacing
with
and
with
. Such a change of variable allows us to avoid the projection step in Algorithm 1.
3.3 Recursive maximum likelihood estimation
A straightforward competitor to ONGD is a (classic) recursive MLE procedure. While suboptimal for non convex problems, such a recursive procedure is a quasi-Newton approach that approximates the Hessian with a positive definite matrix thanks to first-order information. Hence, the algorithm is ensured to run although its performance depends on how close the approximated Hessian is to the true Hessian. Recall that . We can rewrite (5) as
(8)
(8)
Let be the estimate of the parameter vector at time t. The recursive MLE procedure relies on a Newton step for obtaining
as a function of
, see, e.g., Madsen (2007) and Pinson and Madsen (2012). Let
if
,
if
and
. Our two-step recursive scheme at time t is
An algorithm based upon such a scheme might face computational issues as it requires inverting the information matrix , at each iteration. This can be prevented by directly working with the matrix inverse, the covariance matrix
. The resulting algorithm (rMLE.b) is described in Algorithm 2.
Algorithm 2 Recursive Maximum Likelihood Estimation (rMLE.b)
Input: , forgetting factor
,
for
do
Set if
or set
if
.
Update:end for
The technical derivations and detailed computations required for Algorithms 1 and 2 are available in the supplementary material.
4 Simulation study
We perform an empirical study on synthetic data to check on the behaviour of ONGD, in particular in comparison with a classic recursive MLE procedure, i.e., rMLE.b. We run 100 Monte Carlo (MC) simulations with ,
,
,
. Only the bound parameter b is simulated so that it varies over time. Hence, in Section 4.1, while we test the tracking ability of our algorithms regarding b, we also control their ability to retrieve constant parameters, i.e.,
,
and
. Then, in Section 4.2, we introduce the task of issuing predictive distributions using the tracked parameters and evaluate the algorithms depending on the sharpness and calibration of these forecasts.
4.1 Tracking the parameter vector
The lag of the AR process is assumed to be known and the initial values of the parameter vector
are set to
. From a theoretical point of view, these initial values only need to be feasible, i.e.,
,
and
. We (a priori) choose
and
because they are standard values. The values of the hyperparameters m and
for ONGD,
for rMLE.b, are empirically selected. We test a grid of values for each hyperparameter and select the values that achieve the best tracking/accuracy trade-off on the first MC simulation. The same values are then used on the 99 remaining MC simulations. These values are listed in Table 1. ONGD runs as soon as m observations are available, while rMLE.b runs from p observations on but needs a warm-up period
to update the covariance matrix
before starting updating the parameters. Note that the computational complexity is
for ONGD and
for rMLE.b. Running Algorithms 1 and 2 to track the parameter vector over the 100 synthetic time series of our simulation study took about 10 seconds and 4 seconds, respectively. We used a 12-core CPU MacBook M3 Pro Chip with 18GB unified memory and parallel computation over 5 cores.
We provide in Figure 3 the plots of for the first MC simulation,
and
w.r.t. each parameter, the other parameters being fixed to their true values. From the function being not convex in b, it is clear that the optimization problem cannot be assumed to be convex when introducing an upper bound parameter b. The tracked parameters averaged over the simulations are presented in Figure 4 along with corresponding MC intervals. ONGD manages to accurately estimate both time-varying and constant parameters while rMLE.b performs well in tracking a decreasing b, but fails to properly track an increasing b. Moreover, this comes with a cost in accuracy that is very high for constant parameters. The estimation of
and
is also rather unstable. Note that
is already at its true value when the algorithms get started and allows us to control that there is no divergence from the optimal value. As a matter of fact and as stated by Hazan et al. (2015), for ONGD we have observed the divergence of
when the minibatch size m was too small, i.e., for
.
4.2 Forecasting the distribution
As many applications that might benefit from this framework involve forecasting, we are now interested in the performance of the algorithms when forecasting at time t the distribution of the bounded variable . To be able to track the bound parameter b over time, we have introduced in Section 2 the extended time-dependent negative log-likelihood
, which makes sense from an inference point of view. As we are working with series of dependent observations, when moving to forecasting the distribution of
, we need the current value
of b to be greater than all the p former observed values of
for the expected value of
to exist. Therefore, we introduce a projection step as described in Section 1 for ONGD: we project
on the convex set
and we get the projected parameter
where
if
,
if
. Note that we need to introduce a small
as we project
on an open convex set. When looking at the observation
as a coarsened version of
,
can be seen as a coarsening parameter. This coarsened data framework has been formalized by Heitjan and Rubin (1991) and Heitjan (1993). We use
.
We evaluate the predictive distributions through proper scoring rules. Scoring rules are attractive measures of predictive performance as they evaluate calibration and sharpness simultaneously. The paradigm of maximizing the sharpness subject to calibration was proposed in Gneiting et al. (2007) under the conjecture that ideal forecasts and the maximization of sharpness subject to calibration are equivalent. Not only are scoring rules measures of both calibration and sharpness, they also incentivize truthful calibrated and informative forecasts when they are proper for the class of predictive distributions at hand (Holzmann and Eulert, 2014). We use the Continuous Ranked Probability Score (CRPS) that is a proper scoring rule relative to the class of the Borel probability measures on
(Gneiting and Raftery, 2007). Proper scoring rules are often used in negative orientation, e.g., the lower the better. As we work with predictive densities, one could think of using the logarithmic score, which is strictly proper relative to all measures that are absolutely continuous. However, in our framework it can always happen that
falls outside the support of the predictive density
we have issued at time t, when the current estimate
of the upper bound is too low. In such a case, the logarithmic score is equal to
, which is not suitable. In contrast, let us identify a probabilistic forecast with its cumulative distribution function (cdf) F. For continuous variables, the CRPS is defined on
as
(9)
(9)
where x is the evaluation point. Let and
. When
, i.e., the observation
is inside the support of the predictive distribution
, we have
(10)
(10)
Now when , i.e., the observation
is outside the support of the predictive distribution
, we have
(11)
(11)
Note that and
are fixed to the same values in (10) and (11) while only
varies. It is straightforward to see that for a same forecast
, the CRPS increases when
is outside the support of the predictive distribution
, compared to
being inside. However, contrary to the logarithmic score that becomes infinite, the CRPS is only increased to a higher finite value. Lastly, the CRPS allows us to compare discrete and continuous distributions, that is to compare our density-based algorithms to usual benchmarks such as climatology and probabilistic persistence. Indeed, if the predictive distribution takes the form of a sample of size N, then the right side of (9) can be evaluated in
operations (Hersbach, 2000). Climatology is based on all data available at the time of forecasting and probabilistic persistence is the last observed value, which we dress with the past persistence errors. We also evaluate the predictive distributions issued by rMLE.1, i.e., by the usual recursive MLE when the bound is assumed to be fixed and equal to 1 (Pierrot and Pinson, 2021).
We start computing predictive distributions after 2,000 observations. Recall that the hyperparameters were chosen in Section 4.1 upon looking at only the first MC simulation, but the whole simulated time series, i.e., the data we are now computing probabilistic forecasts for. This may be optimistic, even if we only looked at the data from the first MC simulation. In order for our algorithms to not be more optimistic than the benchmarks, we use the hyperparameters for probabilistic persistence and rMLE.1 that give the best CRPS on the first MC simulation. The CRPS are available in Table 2. The average CRPS obtained by the ideal forecaster, i.e., the GLN distribution with the true values ,
,
,
, is 5.782%. Probabilistic persistence performs very well on our synthetic dataset with a CRPS that is already much closer to the ideal forecaster’s than climatology’s. ONGD, which properly handles the varying upper bound, shows a CRPS that is very close to the ideal forecaster’s. Moving from rMLE.1 to ONGD provides a significant improvement, which is similar to moving from probabilistic persistence to rMLE.1. As for ONGD’s natural competitor rMLE.b, it does not manage to improve the results of rMLE.1 significantly.
To specifically check on probabilistic and marginal calibration, Probability Integral Transform (PIT) histograms and marginal calibration plots are available in the supplementary material.
5 Application to wind power forecasting
Accurately forecasting wind power generation is highly important for the integration of wind energy into power systems. We are interested in very short-term forecasting, that is in lead times of a few minutes, which is not only crucial for transmission system operators to keep the system in balance but also very difficult to improve the forecasts for, especially compared to the simple but very efficient persistence.
5.1 Data description
We have historical data from a large offshore wind farm, Anholt in Denmark, from July 1, 2013 to August 31, 2014. The active power is available for 110 wind turbines at a temporal resolution of every 10 minutes. We normalize each time series individually according to the nominal power of the wind turbine, and compute the average generation over the wind farm depending on the number of wind turbines that are available at each time t in order to handle missing values. The response random variable we wish to forecast at time t is , the average active power generated by the wind farm at time
. As stated in Section 4.2, we choose to look at the observation
as a coarsened version of
with
. Hence, an observation
is set to
if
and to
if
and
whereas
.
5.2 Validation setup
We split our dataset into two datasets that we keep separate: a training/cross-validation dataset from July 1, 2013 to March 31, 2014, resulting in 39,450 observations; a test dataset from April 1 to August 31, 2014, resulting in 22,029 observations. As in Section 4.2, we compare Algorithms 1 and 2 to climatology, probabilistic persistence and rMLE.1. For methods involving hyperparameters, namely probabilistic persistence, rMLE.1, ONGD and rMLE.b, we choose the hyperparameters upon CRPS-based cross-validation: we run each competing algorithm from the beginning of the training set, issue the corresponding probabilistic forecasts, and select the hyperparameters that give the lowest CRPS on the cross-validation dataset, i.e., data from November 1, 2013 to March 31, 2014. The subsequent hyperparameter values are available in Table 3.
Running Algorithms 1 and 2 to track the parameter vector over the entire dataset took 0.98 seconds and 0.60 seconds, respectively. We used a 12-core CPU MacBook M3 Pro Chip with 18GB unified memory.
5.3 Assessment of the probabilistic forecasts
The probabilistic forecasts associated with each algorithm are assessed on the test set. The corresponding CRPS are presented in Table 4. Again, probabilistic persistence improves the CRPS of climatology by a large percentage already and both rMLE algorithms perform similarly. As for ONGD, the improvement over both persistence and rMLE.1 is very significant and much larger than the one observed during the simulation study. The parameters tracked by rMLE.1 and Algorithms 1and 2 are plotted for some sub-sample of the test set in Figure 5. We plot the projection of
, see Section 4.2, to display the upper bound that is actually used for prediction. The estimates of the parameter vector
are consistent between ONGD and rMLE.b, while more noisy for ONGD. The parameter estimates from rMLE.1 and rMLE.b are in general very close to one another and show similar patterns. Indeed, rMLE.b does not manage to track a varying upper bound since the estimated
does not vary significantly away from 1. Only ONGD captures variations of the bound parameter b below 1. When selecting the hyperparameters, we observed a significant improvement on the cross-validation set for a minibatch size
only, the values tested for
. By looking at the parameter estimates, we noticed that for
the bound estimate was also varying away from 1, but more slowly and closer to 1. When looking at the power generation itself, the bound tracked by ONGD for
does make sense. This result and the generalization performance of the model are confirmed on the test set, since the CRPS we get is very close to the one we got on the cross-validation set. Therefore, it seems that these data call for a very aggressive choice of m, so that the algorithm can track the bound. In return some noise is introduced into the other parameter estimates.
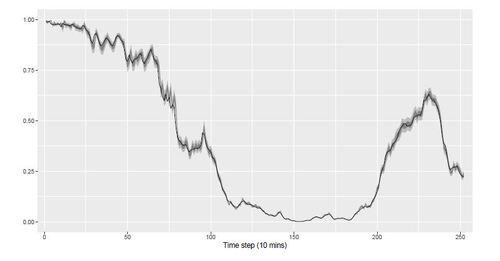
In Figure 6, we provide the probabilistic forecasts of ONGD over a 36-hour period of time on the test set. One can note that the prediction intervals are tight. When looking at probabilistic calibration, the PIT histogram shows a large number of very low and very high PIT values, which suggests that the predictive distributions issued by ONGD are underdispersed. However, when an observation falls outside of the prediction interval, it does not fall far away, which explains the very good CRPS achieved by ONGD overall. PIT histograms and marginal calibration plots for all algorithms are available in the supplementary material.
6 Discussion
We have introduced a framework, where we aim to track varying bounds for bounded time series as well as an extended time-dependent negative log-likelihood to deal with this new framework. As the objective functions at hand are not convex anymore, we have proposed to use the broader local-quasiconvexity assumption through an online algorithm. To compete with this quasiconvexity framework and online algorithm, we have also proposed a more usual recursive MLE procedure. We have run these algorithms on both a synthetic and a real dataset to track the parameters of a time series distribution over time, including the upper bound of the support of the distribution. Then, we have presented how to use such a new framework for forecasting.
The algorithm we propose in this new framework is an online algorithm that is directly derived from SNGD and, similarly to ordinary OGD, only relies on the negative log-likelihood we observe at time t for our current set of parameters. It no longer requires any kind of forgetting action and only asks for the usual step size when updating the parameter vector through the gradient at time t. A new hyperparameter that is related to a specificity of SNGD is the size m of the minibatch, since SNGD is not guaranteed to converge for , unlike SGD. This algorithm performs very well on our simulated examples, with performances very close to the ideal forecaster. When applied to wind power forecasting, it improved the CRPS of probabilistic persistence by more than 30% on the test set. However, the predictive distributions do not achieve probabilistic calibration, as the prediction intervals appear to be too narrow in general. It is worth noting that ONGD required to set the minibatch size m to 1 on the wind power generation dataset in order to be able to track the upper bound. This is quite aggressive and suggests that this kind of data may call for methods that can handle big jumps in the bound values.
We challenged ONGD with two competitors, both of which relying on recursive MLE: rMLE.1 and rMLE.b. The former operates in the usual framework when the upper bound is assumed to be fixed to 1, while the latter is as straightforward adaptation of rMLE.1 in the context of a varying upper bound. These algorithms showed similar performances on both synthetic and real data, with rMLE.b failing to properly track a varying upper bound. Since this is, to the best of our knowledge, the first time such a framework with varying bounds has been studied, further research could explore different assumptions, e.g., on the stochastic process the distribution of the bounded variable, or a lower bound.
Calculation details:
Technical derivations and details that are required by the computations for Algorithms 1 and 2. (.pdf file)
Additional plots:
PIT histograms and marginal calibration plots for all competing algorithms in the simulation study and the application to wind power forecasting. (.pdf file)
R project:
R scripts for the simulation study in Section 4, along with the corresponding synthetic data. All outputs necessary for the study can be reproduced with the corresponding scripts and are also provided. The structure and content of the R project is described in a README file. (.zip file)
Table 1: Hyperparameter values for each algorithm: step size and minibatch size m (Algorithm 1) and forgetting factor
(Algorithm 2)
Table 2: 1-step-ahead CRPS and respective improvement over persistence and rMLE.1. The CRPS is averaged over the MC samples, and the standard deviation is also provided.
Table 3: Hyperparameter values for each algorithm: order p of the AR process, step size , minibatch size m and forgetting factor
.
Table 4: 10-minute-ahead CRPS and respective improvements over probabilistic persistence and rMLE.1.
Figure 1: Sigmoid function on the real line.
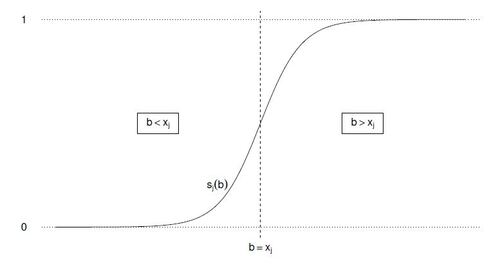
Figure 2: A quasiconvex differentiable function on , the negative density of a normal variable, with plateau areas when going away from the global minimum.
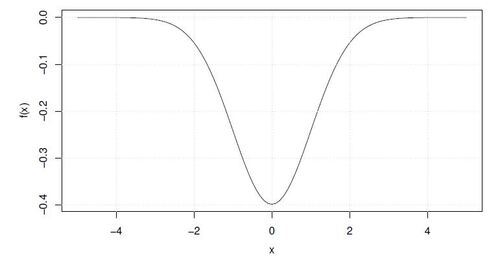
Figure 3: The extended time-dependent negative log-likelihood for the first MC simulation, ,
, w.r.t.
(top left),
(top right),
(bottom left) and b (bottom right). For each plot, the remaining parameters are set to their true values.
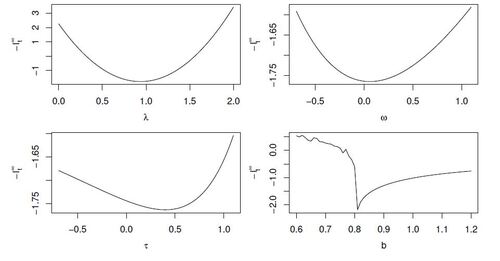
Figure 4: Confidence intervals of the tracked parameters for ONGD (top) and rMLE.b (bottom) with coverage probabilities 0.9 and 0.5, along with the average estimates (solid lines) and the true parameters (dotted lines).
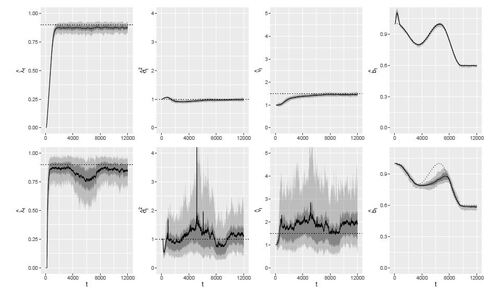
Figure 5: Estimates ,
,
and projected estimate
on a sub-sample of the test set for rMLE.1 (top), ONGD (center) and rMLE.b (bottom).
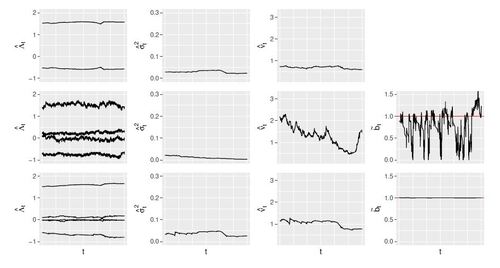
Figure 6: Probabilistic forecasts from ONGD, based on prediction intervals with nominal coverage rates of 95 and 75%, along with power measurements (solid black line).
Supplementary_Materials_for_Review (15).zip
Download Zip (89.9 MB)References
- Bacher, P., Madsen, H., and Nielsen, H. A. (2009), “Online Short-Term Solar Power Forecasting,” Solar Energy, 83, 1772–1783.
- Boyd, S. P. and Vandenberghe, L. (2010), Convex Optimization, Cambridge University Press.
- Cesa-Bianchi, N., Conconi, A., and Gentile, C. (2004), “On the Generalization Ability of On-Line Learning Algorithms,” IEEE Transactions on Information Theory, 50, 2050–2057.
- Cesa-Bianchi, N. and Lugosi, G. (2006), Prediction, Learning, and Games, Cambridge University Press.
- Cotgreave, P. and Clayton, D. H. (1994), “Comparative Analysis of Time Spent Grooming by Birds in Relation to Parasite Load,” Behaviour, 131, 171–187.
- Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977), “Maximum Likelihood from Incomplete Data via the EM Algorithm,” Journal of the Royal Statistical Society. Series B (Methodological), 39, 1–38.
- Duchi, J., Hazan, E., and Singer, Y. (2011), “Adaptive Subgradient Methods for Online Learning and Stochastic Optimization,” Journal of Machine Learning Research, 12, 2121–2159.
- Frederic, P. and Lad, F. (2008), “Two Moments of the Logitnormal Distribution,” Communications in Statistics - Simulation and Computation®, 37, 1263–1269.
- Gneiting, T., Balabdaoui, F., and Raftery, A. E. (2007), “Probabilistic Forecasts, Calibration and Sharpness,” Journal of the Royal Statistical Society. Series B (Methodological), 69, 243–268.
- Gneiting, T. and Raftery, A. E. (2007), “Strictly Proper Scoring Rules, Prediction and Estimation,” Journal of the American Statistical Association, 102, 359–378.
- Guolo, A. and Varin, C. (2014), “Beta Regression for Time Series Analysis of Bounded Data, with Application to Canada Google® Flu Trends,” The Annals of Applied Statistics, 8, 74–88.
- Hazan, E., Levy, K. Y., and Shalev-Shwartz, S. (2015), “Beyond Convexity: Stochastic Quasi-Convex Optimization,” in Advances in Neural Information Processing Systems, volume 28.
- Heitjan, D. F. (1993), “Ignorability and Coarse Data: Some Biomedical Examples,” Biometrics, 49, 1099–1109.
- Heitjan, D. F. and Rubin, D. B. (1991), “Ignorability and Coarse Data,” The Annals of Statistics, 19, 2244–2253.
- Hersbach, H. (2000), “Decomposition of the Continuous Ranked Probability Score for Ensemble Prediction Systems,” Weather and Forecasting, 15, 559–570.
- Holzmann, H. and Eulert, M. (2014), “The role of the information set for forecasting—with applications to risk management,” The Annals of Applied Statistics, 8, 595 – 621.
- Johnson, N. L. (1949), “Systems of Frequency Curves Generated by Methods of Translation,” Biometrika, 36, 149–176.
- Laderman, J. and Littauer, S. B. (1953), “The Inventory Problem,” Journal of the American Statistical Association, 48, 717–732.
- Madsen, H. (2007), Time Series Analysis, Chapman & Hall.
- Mead, R. (1965), “A Generalised Logit-Normal Distribution,” Biometrics, 21, 721–732.
- Nesterov, Y. E. (1984), “Minimization Methods for Nonsmooth Convex and Quasiconvex Functions.” Matekon, 29, 519–531.
- Pierrot, A. and Pinson, P. (2021), “Adaptive Generalized Logit-Normal Distributions for Wind Power Short-Term Forecasting,” in 2021 IEEE Madrid PowerTech, Institute of Electrical and Electronics Engineers Inc.
- Pinson, P. (2012), “Very-Short-Term Probabilistic Forecasting of Wind Power with Generalized Logit-Normal Distributions,” Journal of the Royal Statistical Society. Series C (Applied Statistics), 61, 555–576.
- Pinson, P. and Madsen, H. (2012), “Adaptive Modelling and Forecasting of Offshore Wind Power Fluctuations with Markov-Switching Autoregressive Models,” Journal of Forecasting, 31, 281–313.
- Wallis, K. F. (1987), “Time Series Analysis of Bounded Economic Variables,” Journal of Time Series Analysis, 8, 115–123.
- Warton, D. I. and Hui, F. K. C. (2011), “The arcsine is asinine: the analysis of proportions in ecology,” Ecology, 92, 3–10.
- Zinkevich, M. (2003), “Online Convex Programming and Generalized Infinitesimal Gradient Ascent,” in Proceedings of the 20th International Conference on Machine Learning.