?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The canonical video action recognition methods usually label categories with numbers or one-hot vectors and train neural networks to classify a fixed set of predefined categories, thereby constraining their ability to recognise complex actions and transferable ability to unseen concepts. In contrast, cross-modal learning can improve the performance of individual modalities. Based on the facts that a better action recogniser can be built by reading the statements used to describe actions, we exploited the recent multimodal foundation model CLIP for action recognition. In this study, an effective Vision-Language action recognition adaptation was implemented based on few-shot examples spanning different modalities. We added semantic information to action categories by treating textual and visual label as training examples for action classifier construction rather than simply labelling them with numbers. Due to the different importance of words in text and video frames, simply averaging all sequential features may result in ignoring keywords or key video frames. To capture sequential and hierarchical representation, a weighted token-wise interaction mechanism was employed to exploit the pair-wise correlations adaptively. Extensive experiments with public datasets show that cross-modal action recognition learning helps for downstream action images classification, in other words, the proposed method can train better action classifiers by reading the sentences describing action itself. The method proposed in this study not only reaches good generalisation and zero-shot/few-shot transfer ability on Out of Distribution (OOD) test sets, but also performs lower computational complexity due to the lightweight interaction mechanism with 84.15% Top-1 accuracy on the Kinetics-400.
1. Introduction
Action recognition task in the field of Computer Vision (CV) is essentially a classification task in which models usually predict the actions by given video segments (Ma et al., Citation2022). In unimodal action recognition methods, the whole process is similar to the image classification task. Firstly, the model extracts features from the video data, then gets the prediction results through the linear classifier, and calculates the cross-entropy loss label. The only difference between the action recognition and image classification process is that the video data has a one-dimensional time dimension more than image data, while multi-frame video features need to be fused (Tian et al., Citation2020). As shown in Figure (a), most of traditional methods of action recognition are interpreted as unimodal foundation, treating various classes of videos as predetermined labels without semantic meaning. When new labels need to be added, additional retraining must be fulfilled, which results in limitation on transferability of model in other new and unseen concepts.
Figure 1. Comparision of multimodal framework (b) and the existing unimodality approaches (a), a notable distinction lies in their treatment of labels. In the case of (a), labels are typically encoded into numerical values or one-hot vectors. However, multimodal framework in (b) leverages the inherent semantic information within the label text itself. The goal of the multimodal framework is to bring video representations corresponding to the labels closer together, driven by the underlying semantics of the label text.
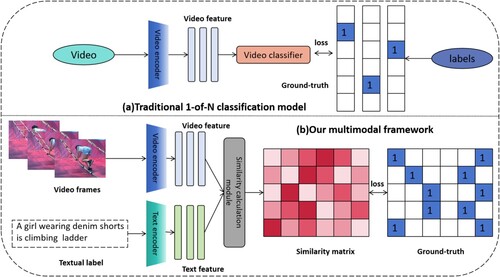
Vision-text multi-modality is a top topic spawning some interesting research fields such as image captioning, video understanding, and visual question answering (Iashin & Rahtu, Citation2020; Yamazaki et al., Citation2023). These tasks have achieved state-of-the-art (SOTA) performance because multimodal video-texts pairs are complementary, which strengthen representation with semantic language supervision and capture different aspects of the underlying concepts (Xia et al., Citation2020). The recognition of visual targets by the brain is divided into two parts: visual attributes and semantic attributes, which are what the target looks like and what it is, respectively. From the perspective of neuroscience, cognitive representations encompass multimodal aspects (Nanay, Citation2018). For example, the neural response to video frames depicting action corresponds to the activation observed when presented with textual descriptions of the same action. Humans are born to understand concepts from semantic representations. Description can help people better learn and recognise visual objects with just few given examples. Cross-modal representations constitute a fundamental aspect of the human perceptual-cognitive system. Compared with the traditional 1-of-N majority vote task, semantic language supervision in a multimodal model enables model to achieve zero-shot transfer without requiring additional labelled data. Given the aforementioned considerations, in this paper, we introduce a solution as shown in Figure (b) for cross-modal few shot action recognition. To be specific, our method use semantic and visual representations as training examples (Bao et al., Citation2022). For example, in the task of learning a dancing classifier, we treat both textual description and visual representations of dancing as training examples. In summary, one can train better dancing action classifier by learning textual strings describing dancing. We exploit the existing pre-trained model CLIP (Radford et al., Citation2021), mapping semantic information and action vision to the same representation space. Then, it becomes a visual-language matching problem. In essence, our work is an original pre-training procedure via prompt engineering. Finally, we finetune the model on target datasets. We demonstrate that the video-text multimodal learning framework is capable of zero-shot/few-shot prediction and obtains better performance on several public benchmark datasets.
Using multi-modal learning framework to implement video action recognition, cross-modality intersection mechanism must be considered because of its significant effects on the overall performance of model. Cross-modality intersection mechanism makes correlations among multi-modality features and aggregates information from pre-trained models to enhance performance. In this study, we highlight the following common underlying assumptions: (1) only a few words and video frames determine the type of the video; (2) action recognition tasks require high real-time performance in industry. Single-vector intersection is widely used in field of cross-modality interaction. It compresses long sequences into a single vector which leads to pushing the network to learn complex abstractions so that fine-grained clues are easily missed out (Luo et al., Citation2022). In contrast to parameter-free single-vector intersection, cross-transformer intersection has emerged which learns the inter-modal relations among videos and textual label by exchanging key-value pairs in the multi-headed attention module. However multi-head attention usually suffers from optimisation difficulty and generally requires prohibitively computational cost to finetune Vision-Language model (Duan et al., Citation2022). Hence, a token-wise interaction mechanism is needed to balance similarity retrieval performance and computer complexity. In this paper, we introduce a lightweight weighted token-wise interaction (WTI) to solve the sequential matching problem. WTI is a disentangled representation method that separates different factors of variation in data into distinct dimensions, allowing for more transparent and explainable representation of the data. This interaction mechanism fully interacts with all video frame tokens and sentence tokens, and adaptively adjusts the weight magnitude for each token. Such intersection mechanism can preserve more fine-grained information and reduce computation complexity.
In summary, our contributions are three-fold.
Different from most traditional unimodal video classification methods. We formulate the video action recognition task as a multimodal learning problem. By incorporating semantic language supervision, it strengthens the representations of videos, thereby broadening model's versatility and adaptability in zero-shot/few-shot settings.
Employing average pooling may lead to a reduction in overall similarity due to the inclusion of irrelevant segments. Instead, this paper introduces a new cross-modality interaction mechanism for video action recognition, WTI, which learns adaptive weights. WTI can select relevant segments by adjusting the weight magnitude for each token so that fine-grained clues of video clips can be easily found.
Our model outperforms existing unimodal and multimodal learning methods for video action recognition on widely-used action recognition benchmarks.
The rest of this paper is structured as follows. Section Equation2(2)
(2) conducts an analysis of related work. Next, Section Equation3
(3)
(3) details the proposed Vision-Language adaptation. Then, Sections 4 and 5 introduce implementation details of experiments, making comparisons with state-of-the-art methods and providing ablation results for benchmark datasets. Finally, Section 6 wraps up the paper with its conclusions.
2. Related work
This section briefly reviews previous studies on unimodal learning and cross-modal learning for video action recognition.
2.1. Video action recognition via unimodal learning
We have observed that there are two basic approaches for video action recognition, one is based on single stream network, the other is based on two-stream network. Single stream networks, such as 3D-HOG (Klaser et al., Citation2008), 3D-CNN (Feichtenhofer et al., Citation2019), Dense Trajectories (Wang et al., Citation2013), are designed for spatiotemporal representations. This means that the network takes both spatial and temporal information into account simultaneously in a unified model. The convolutional layers analyse the spatiotemporal patterns together, and the model learns to extract relevant features for the task at hand. Researchers have explored various methods to integrate temporal information from consecutive frames through the use of 2D convolutions. However, some issues may cause these approaches to fail:
The deficiency in model generalisation stems from the absence of end-to-end learning on large-scale datasets.
The learnt spatiotemporal feature does not capture motion features.
In two-stream networks, the network is separated into two parts: a pre-trained network for spatial context, and a network for motion context. The two streams are fused through the middle or at last (Feichtenhofer et al., Citation2016; Simonyan & Zisserman, Citation2014; Wang et al., Citation2016). Such methods capture the local temporal movement to improve the performance of the Single Stream method. However, there are still some issues:
The long range temporal information missed in learned features.
The assumption that the ground truth for each clip aligns with the ground truth of the entire video may be inaccurate, particularly when an event of interest occurs for a brief duration within the overall video.
Besides, unsupervised learning is also applied in video classification, such as clustering analysis-based methods and self-encoder-based methods. Clustering analysis-based method groups samples in video data according to their feature similarity through clustering algorithms, thereby achieving video classification. Meanwhile, autoencoder-based methods learn the feature representation of video data by training an autoencoder model (Hajati & Tavakolian, Citation2020).
Building on the natural language processing breakthroughs, Transformer (Vaswani et al., Citation2017) has found tremendous success in computer vision scenarios. Transformer-based networks for video classification modify the Vision Transformer(ViT) to spatial and temporal features jointly, having better performance on several datasets. Yet, most prior models are unimodal without natural language supervision, which lack zero-shot transfer capability. Unlike most prior approaches, we study on vision-text multi-modality learning and extend work to zero-shot/few-shot video action recognition. The proposed approach mainly designs appropriate prompting methods which finetune CLIP-based frameworks by giving each class semantic information and inserting lightweight MLPs. Our model can offer richer semantics, enabling it to learn a wider range of feature representations.
2.2. Cross-modal learning for video action recognition
Cross-modal learning in video action recognition refers to the use of information from multiple modalities to improve the accuracy and robustness of action recognition in video data. We do find several recent works applying cross-modal learning in video action recognition task (Bruce et al., Citation2022; Kim et al., Citation2023; Song et al., Citation2020). Experimental results reveal that these methods outperform state-of-the-art unimodal learning approaches for this task. These methods extract discriminative features from different modalities such as RGB features, pose tokens, skeleton-based features and so on, aiming to explore the relationships of different modalities and improve the recognition performance. Yet, the former is prone to just extract modalities information from videos and ignores the semantic supervision when training classifiers.
Vision-Linguistic models have achieved SOTA performance at classic vision tasks (Baldrati et al., Citation2022; Lei et al., Citation2021; Lin et al., Citation2023). In these studies, video representation learning was interpreted as video-to-text or text-to-video matching problem. Prior method ActionCLIP (Wang et al., Citation2023), explores natural language supervision in a cross-modal architecture and makes use of textual labels as classifier weights, and it deploys unimodal loss function on visual and textual representations separately. When measuring feature similarity, it uses a Single Vector Dot-product Interaction:Cosine similarity, which pulls pairwise visual and textual representation close to each other:
(1)
(1) Cosine similarity compresses long sequences into a single vector, which pushes network to learn complicated abstractions and misses out fine-gained clues. We instead deploy another disentangled interaction mechanism to capture sequential and hierarchical representation. Keeping the sequential structure can preserve more fine-grained clues and reduce information loss. This work targets a deeper understanding of the interaction mechanism for action recognition in a new perspective. The experiments indicate that our model not only enhances generalisability but also has high efficiency.
3. Vision-Language adaptation
This section defines the research problem and mathematically formalise our approach to cross-modal learning. Next, we present framework of the model, comprising four modules:a feature extractor module,a textual string prompt module,a data augmentation module,and cross-modal linear probing module(CMLP) in which we define WTI cross-modality interaction mechanism. Finally, the model algorithm is presented.
3.1. Problem definition
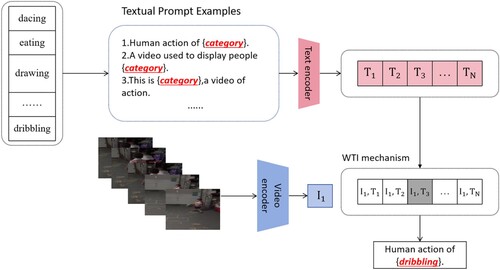
For most recognition approaches mentioned in the previous section, the input video is processed by classic encoders, then the loss is calculated with labelled ground-truth. There are limitations of supervised learning that labelling is required, and labels will be limited by the size of the dataset. How to define labelling is a crucial issue. For example, a video like "open the door" corresponds to a phrase that has three words. The word open can also describe many actions. There is a trade-off, if we label many classes, loss function may perform poorly. Meanwhile, if only large classes are labelled, it is impossible to predict small classes at fine granularity. The feasible method is to eliminate the limitations of labels by strengthening the representations from video data with more semantic supervision, which could enable the model to make predictions in zero-shot/few-shot situations without any further labelled data,as shown in Figure .
Figure 2. Our approach involves joint training of a video encoder and a text encoder to estimate the correct pairings for a set of training examples that consist of video frames and corresponding texts. During the testing process, the zero shot/few shot classifier calculates similarity scores of video frames and descriptions of the target actions' classes.
3.1.1. Unimodal learning
Firstly, we examine the standard unimodal few-shot learning classification. Given an input video and label
from a predefined label set γ, the vanilla methods usually learn classifiers to estimate the probability:
(2)
(2) where
is pre-trained feature encoder and
is a typical loss function:
(3)
(3) where y is turned into a number or a one-hot vector to indicate the index of the entire label set
. In the last phase of the calculation, the highest score of the index is considered as the corresponding category. The class weights
and feature encoder
are in the same N-dimensional space in order to calculate similarity:
(4)
(4)
3.1.2. Cross-modal learning
We aim to break the routine and define the problem as:
(5)
(5) where
is not a simple label, instead, it is original words of the label. In this equation, each training sample pair
is accompanied by a discrete label indicating its modality:
(6)
(6) The definition of modalities is
. The modality-specific feature encoder
is supposed to map all modalities to the same dimensional space to calculate similarity of pair
:
(7)
(7) Then, the learned classifier produces the label with highest similarity score:
(8)
(8) Based on the multimodal framework, it is possible to carry out few-shot/zero-shot prediction as normal testing process. Ensembles of modality-specific classifiers are regarded as linear combinations of training samples. In this cross-modal linear probe, the weights of class y are a weighted combination of all i training features:
(9)
(9) This equation indicates a linear classification which is a cross-modal adaptation in our model, solving for learnable weights
jointly.
3.2. The new paradigm
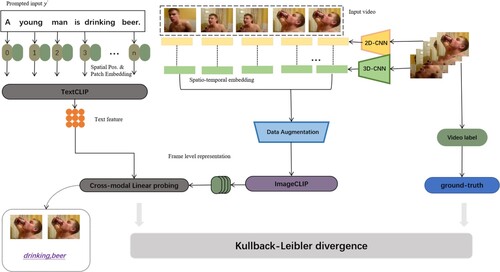
As presented in Figure , when considering the multimodal learning framework mentioned above, we propose a new Vision-Language adaptation for action recognition. To specific, Vision-Language adaptation is composed of pre-trained model, data augmentation, prompt engineering,CMLP, loss function, respectively (Gao et al., Citation2023; Zhang et al., Citation2022; Zhou et al., Citation2022a). Our model operates as follows. First, taking a video as input, the pre-visual extractor module outputs the concatenated visual representations. The the label words of all categories are fed into textual template to get prompted . Next, the pre-trained model CLIP encodes the entire video features and prompted
, respectively. Finally, the proposed cross-modality interaction WTI calculates similarity scores among video frames and textual label representations, in which the highest similarity score is regarded as the classification result.
Figure 3. Overview of proposed Vision-Language adaptation. Two single-modal encoders initialise parameters from pre-trained CLIP-based model. A cross-modal linear probing(CMLP) which refers to WTI is designed to calculate similarity among visual and textual tokens. CMLP performs hierarchical cross-modality matching at both semantic-level and feature-level, and chooses key words and relevant frames instead of using average pooling. Kullback–Leibler divergence is defined as the text-video contrastive loss function used to optimise the parameters.
3.2.1. Pre-visual extractor
Video action recognition also involves handling temporal information. Therefore, we need to consider how actions evolve over time. Pre-visual extractor is expected to empower the model to learn spatial and temporal relationships of video frames. For input video frames x,we introduce formulation , where
is visual encoder of pre-trained model. In addition,
is a so called pre-visual extractor which operates on inputs before being processed by CLIP. We send RGB frames extracted from the video to pre-trained 2D-ResNet and 3D-ResNet encoder (Hara et al., Citation2018; He et al., Citation2016; Ji et al., Citation2012; Xia et al., Citation2024). A pre-trained 2D-CNN extracts appearance representations
and 3D-CNN extracts motion representations
. The two types of visual representations are then concatenated frame by frame as follows:
(10)
(10) where
denotes concatenation. Then, not only common spatial positional embeddings are learned, but also learnable temporal embeddings are added to token embeddings to indicate index of a certain frame (Tran et al., Citation2018; Xia et al., Citation2020).
3.2.2. Pre-trained model
Previous studies have proven that pre-training plays a vital role in enhancing the effectiveness of vision- language learning (Kim et al., Citation2021; Lei et al., Citation2021; Li et al., Citation2021). In our model we employ an efficient pre-trained CLIP model so that enormous computation is avoided at during the process of pre-training. CLIP is an image-text representations with the multimodal contrastive learning (MCL) task. MCL is a matching process that brings pairwise unimodal representations into close proximity. The original CLIP model consists of two main components: a CNN (visual encoder) for image processing and a Transformer model (image encoder) for text processing. Both components are trained to map the input information into the same embedding space. The pre-training of the CLIP model is divided into two stages: the first stage is to train the Transformer model through a large-scale text dataset, enabling the model to understand the relationships between texts; The second stage is to use a large-scale image and text dataset to train the entire CLIP model, enabling it to match the connections between text and images. The biggest contribution of CLIP lies in breaking the shackles of fixed type labels and making the reasoning of downstream tasks more flexible. And in the case of few shot, its effect performs well (Baldrati et al., Citation2022).
We define Z to be K discrete manual sentences with semantic meaning. The prompted input is then processed by the aforementioned text encoder
mentioned above. For vision model, the input video frames
are firstly processed by a Data Augmentation which we will discuss later. Then the representations are fed into pre-trained image encoder
based on CLIP.
3.2.3. Prompt engineering  textual string prompt
textual string prompt
It is not easy to achieve accurate and ideal results using generative AI. This requires a deep understanding of AI's operating logic and the ability to ‘talk’ with Chatbot, just like training a babbling child. Prompt engineering aims to guide AI to think step by step to obtain the expected results (Liu et al., Citation2023).
To be specific, prompt engineering means the original training samples are modified to make pre-trained model adapt to downstream classification task. Most prior prompts reformulate or adjust tasks by adding a linear layer to pre-trained features extractor. Textual prompt means textual string is used, which has unfilled slots to fill with expected content. For example, if we want a model to classify a panda, we could add content like panda is cute, ink style. If we are not satisfied with results, new content could be added for adjustment, such as fat panda eating bamboo. Given a label y, we define permissible values Z. Then a label text extension called prompted textual is generated by formulation
where
. We define fixed templates and use original hand-crafted templates (Zhou et al., Citation2022b).
3.2.4. Data augmentation
Data augmentation is a method to expand the training data set by using a small amount of data to generate more similarly generated data through prior knowledge.
Recent research has shown that data augmentation could improve generalisation of deep learning model significantly in some cases. We explore data augmentation technique for input video frames. We employ a classic data augmentation method called RandAugment which is proposed by Google Research in 2019 to solve the problem of small samples (Cubuk et al., Citation2020). The traditional strategy of automatic data augmentation is usually based on training small datasets on lightweight models before applying them to larger models, which causes obstacle on choice of strategy. The process of data augmentation is a task in the preprocessing stage, which may substantially increase the computational cost. Moreover, these approaches are unable to modify the regularisation strength based on model or dataset size due to separate search phase. RandAugment addresses these limitations. RandAugment can greatly reduce the incremental sample space generated by data augmentation, so that it can be completed together with the model training process, avoiding completion as an independent preprocessing task. RandAugment sets regularisation parameters for augmentation strength, which can be adjusted according to different models and dataset sizes. Before forwarding video tokens to the visual prompt, we use a RandAugment model to extend training datasets and increasediversity of datasets. The specific operation is follow:
(11)
(11) where
denotes data augmentation operation.
3.2.5. Cross-modal linear probing
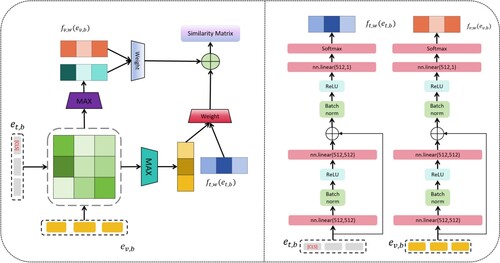
We design a cross-modal linear probing(CMLP) to calculate similarity among textual and visual representations. CMLP generates Logits, which refers to a method of representing model outputs in deep learning. In the training process, our model uses Logits as the input of the loss function, and then converts it into a probability distribution through the loss function. Inspired by recent work ColBERT (Khattab & Zaharia, Citation2020), which design token-wise intersection for text-video retrieval (TVR), we propose an adaptive approach to solve the context matching problem by adjusting the weight magnitude of each token as follows:
(12)
(12) where
and
are encoded features. The channel-wise normalisation operation is defined as:
(13)
(13) where
and
are composed of MLPs and a SoftMax function, which generate the fusion weight. We assume that part of the words and video frames are decisive. Instead of simply performing mean-pooling over the visual features of each frame, the Max operation can select matching video clips, which means the model pays more attention on main actions and ignores irrelevant frames. The details of the WTI are depicted in Figure .
Figure 4. Overview of the proposed disentangled representation learning design for video action recognition. The left part shows the Weighted Token-wise Interaction(WTI) block. The right part shows the details of the network for learning weight, which is composed of typical ResNet architectures.
3.2.6. Loss function
Given a batch consisting of B text-video pairs, WTI generates a similarity matrix. The normalised similarity scores between labelled video-text pairs can be calculated as follows:
(14)
(14) where τ is temperature hyper-parameter. Unlike the straightforward one-to-one comparison between image-text pairs in CLIP, video-text pairs can involve multiple segments of text associated with various videos. Consequently, in the target similarity matrix, positive samples are not limited to diagonal elements. To address this challenge, our solution replaces the cross-entropy loss with Kullback–Leibler(KL) divergence, utilising the similarity between the two distributions to calculate the loss (Langley et al., Citation1997; Park et al., Citation2022). We use KL divergence as the video-text contrastive loss to optimise the framework by comparing the similarity between the predicted probability distribution and the target probability distribution (Wang et al., Citation2019). Let
and
indicate ground-truth similarity scores of video-to-text and text-to-video respectively. The loss function is presented as follows:
(15)
(15) where D is the whole training dataset.
3.2.7. Vision-Language adaptation in algorithm
During the training process, image-text training samples are randomly selected. After RandAugment operation, the initialised ImageCLIP and TextCLIP
extract visual and prompted textual representations, respectively. Next, video and label features are concatenated for cmlp operation which is WTI mechanism detailed in Equation (Equation12
(12)
(12) ). The softmax-normalised similarity scores among texts and video frame are calculated. Finally, the KL divergence is used as contrastive loss to optimise the Vision-Language adaptation. The loss functions are outlined in Equations (Equation14
(14)
(14) ) and (Equation15
(15)
(15) ).
The overall PyTorch-style pseudocode for the proposed Vision-Language adaptation training steps are delineated in algorithm 1 for clarity.

4. Experiments
This section describes the experiments conducted on our Vision-Language adaptation and other methods for video action recognition. This section is composed of three parts: implementation details, quantitative results and few-shot/zero-shot recognition capability analysis.
4.1. Implementation details
We use ViT-B/16 of CLIP's visual encoder which is a 12-layer transformer with 8 attention heads. The textual encoder
is also based on CLIP, which utilises a 12-layer transformer. The
tokens at the highest layer of textual encoder are used as feature representation w.
AdamW is utilised as the optimiser. The base learning rate for pre-trained parameters is set to . We train the model for 50 epochs and set the weight decay of 0.2. The spatial resolution of the input frames is set to 224×224. TOP-1 accuracy and TOP-5 accuracy (Ravuri & Vinyals, Citation2019) are used for evaluation and scores are computed using the official codes. The model was trained with 4 NVIDIA V100 GPUS on three datasets: Kinetics-400, UCF-101, and HMDB-51. The batch size is set to 8. Training process takes about 2 days.
4.2. Quantitative results
A series of experiments have been conducted to assess the effectiveness of our multi-modal framework. Table compares to most SOTA methods on three popular action recognition datasets with different input frames: Kinetics-400, UCF-101, and HMDB-51. There are three parts in this table, corresponding to traditional video-unimodal 1-of-N classification models, cross-modal learning approaches, and our method. ViT-B/16 is used as backbone on ActionCLIP and our method. Referring to the table, our method achieves 84.15% top-1 accuracy with 32-frame input on Kinetics-400, which outperforms all methods in the first part, indicating that exploiting semantic information of text labels and using cross-modal learning framework can dramatically improve the performance. It is also noticed that most of our top-1 and top-5 accuracy are higher than that of ActionCLIP. We believe this benefits from the weighted token-wise intersection, which adaptively adjusts weight magnitude for each token so that key words and key frames can be more easily selected as signal. Our method has leading accuracy on all datasets with 32-input frame. We believe that our model can yield better results with more input frames.
Table 1. Quantitative results on Kinetics-400,UCF-101 and HMDB-51 datasets.
4.3. Few-shot/zero-shot recognition capability analysis
We validated effectiveness of zero-shot/few-shot action recognition ability of our method. We provide two representative methods for comparison, ActionCLIP and STM. For all three methods, we aim to utilise configurations that maximise accuracy to the greatest extent possible. Our method uses ViT/B-16 as backbone and 32-input frame. We conduct experiments on Kinetics-400 (Carreira et al., Citation2018), UCF-101 (Ramesh & Mahesh, Citation2019) and HMDB-51 (Kuehne et al., Citation2011), respectively. As shown in Figure . The results unequivocally highlight the remarkable transferability of our method in situations characterised by limited data availability. In contrast, traditional unimodality methods not only fall short in achieving zero-shot recognition but also show ineffective performance in few-shot scenarios. Furthermore, our method outperforms another multimodal approach in terms of zero-shot and few-shot action recognition capability. We believe the main reason is that WTI mechanism helps the network converge faster, escape local minima, and achieve better generalisation on unseen data.
Figure 5. Zero-shot/few-shot results on Kinetics-400 (left), HMDB-51 (middle) and UCF-101 (right). Our approach leads in delivering superior performance in these challenging, data-scarce conditions. It has the capability to achieve zero-shot recognition across all 3 datasets. A capability that STM lacks under the same condition. Additionally, our method excels at few-shot classification.

5. Ablation experiments
In this section, we conduct carefully chosen ablation experiments to showcase the effectiveness of our method through practical instantiation. We use ViT-B/32 as backbone and 8-frame input, unless there exists exception. All results are tested on dataset Kinetics-400 with single NVIDIA V100 GPU.
5.1. The influence of pre-trained models
In Table , we test validness of pre-trained models by experimenting with random initialised or CLIP pre-trained vision and language encoders. We made the conclusion that proper initialisation of encoders can notably impact accuracy of models. The visual encoder has relatively smaller influence. If both textual and visual encoders are not initialised properly, model 1 can hardly learn good features and dramatically drops accuracy by (41.31%) compared with model 4 on TOP-1 accuracy. Therefore, correct implementation of pre-trained models provide sizable performance.
Table 2. Ablation of the ‘pre-train’ step.
5.2. Textual prompt and image augmentation
Table shows the performance of all combinations of textual prompt and image augmentation techniques. For textual prompt, we try different templates and make comparisons among them. It is noticed that using only label words drops at least (0.48%) compared with exploiting the semantic information of label texts on TOP-1 accuracy. For visual augmentation, we perform standard AutoAugment, Fast AutoAugment (Hataya et al., Citation2020) and RandAugment. The results demonstrate that RandAugment outperforms other methods on test dataset. We believe the main reason is that RandAugment has a less reduced search space that allows it to be trained on the target task and a separate proxy task is not needed anymore. We also find AutoAugment, Fast AutoAugment and RandAugment increase the accuracy with HandEngineered textual prompt (Zhou et al., Citation2022b).
Table 3. We adopt the HandEngineered templates selected by Tip-Adapter and CoOp codebase, unless otherwise stated.
5.3. Backbones and input frames
In Table , we test our method with different backbones and input frames. We use three backbones, ResNet-50, ViT-B/16 and ViT-B/32 (Dosovitskiy et al., Citation2020). Input frames vary from 8, 16 and 32. It is found that transformer-based architectures and more input frames lead to improved performance.
Table 4. Influence of backbones and input frames.
5.4. Runtime analysis
For different methods, we present their GFLOPs(floating point of operations) and inference speed(Runtime) in Table . The textual encoders of all models have the same structure. We implement five methods for comparison. ViViT (Arnab et al., Citation2021), ViT-B-VTN (Neimark et al., Citation2021) and TimesSformer-L (Bertasius et al., Citation2021) are recent pure-transformer models for video classification. STM (Jiang et al., Citation2019) uses 2D ConvNet to extract temporal features. STM has faster inference speed and lower computational GFLOPs, but our method surpasses STM with 5.35% TOP-1 accuracy gap. Similarly, ActionCLIP has a little bit faster inference speed and less computational GFLOPs, while our method has higher accuracy on different backbones and input frames. Compared with the best accuracy of our method, ViViT requires much more GFLOPs(5.6×) and triple runtime to obtain its best results (82.5% vs 84.15%), which is still worse than ours. Our approach is cost-effective and more lightweight because the model doesn't rely on deep finetuning or complicated modality concatenation. WTI mechanism module dynamically reduces weighting operations, and matches key words and key frames, resulting in faster runtime and better performance.
Table 5. GFLOPs and inference speed comparison.
6. Conclusions and future work
Unlike traditional approaches which consider action recognition as a video unimodality classification problem, we present a novel idea for the task by considering it as a vision-language cross-modal matching problem. We proposed a Vision-Language adaptation by using hand-crafted textual labels as additional free training samples. Learning from raw texts is aligned with human cognitive processes and provides more semantic information to learned representations. Instead of simply averaging sequential features, we propose WTI to adaptively generate weights so that keywords and keyframes can be easily matched. The proposed Vision-Language adaptation achieved competitive performance on 3 representative large datasets (Kinetics-400, UCF-101 and HMDB-51). Experimental results also demonstrate that the proposed framework exhibits superior performance across general and few-shot/zero-shot action recognition evaluation metrics. We hope that our crossmodal adaptation will spur further research on downstream video action recognition tasks.
Nevertheless, there are some limitations to the current study. Vision-Language adaptation becomes less effective when representations from different modalities are not well-aligned (Qin et al., Citation2022). In this work, we did not incorporate multi-modality information derived from depth data, skeleton or audio features into our analysis. Rationally harnessing the interplay among depth maps, skeleton, audio features and semantic information holds the potential to augment the performance of the model (Xia et al., Citation2022). Further, the era of Large Language Model(LLM) has come. LLMs such as GPT-4 have been used for downstream tasks fine-tuning. Therefore, in the future work, more fine-tuning strategies based on large model will be used in cross-modal learning tasks to address existing issues of current modality fusion and similarity calculation.
Acknowledgments
This work was partially supported by National Key R&D Program of China under Grant No. 2020YFC0832500 and 2023YFB4503903, National Natural Science Foundation of China under Grant No. U22A20261, Gansu Province Science and Technology Major Project - Industrial Project under Grant No. 22ZD6GA048, Gansu Province Key Research and Development Plan - Industrial Project under Grant No. 22YF7GA004, Gansu Provincial Science and Technology Major Special Innovation Consortium Project under Grant No. 21ZD3GA002, the Fundamental Research Funds for the Central Universities under Grant No. lzujbky-2022-kb12, and Supercomputing Center of Lanzhou University.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., & Schmid, C. (2021). ViViT: A Video Vision Transformer. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 6836–6846). IEEE.
- Baldrati, A., Bertini, M., Uricchio, T., & Del Bimbo, A. (2022). Effective conditioned and composed image retrieval combining clip-based features. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 21466–21474). IEEE COMPUER SOC.
- Bao, H., Wang, W., Dong, L., Liu, Q., Mohammed, O. K., Aggarwal, K., Som, S., Piao, S., & Wei, F. (2022). Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. Advances in Neural Information Processing Systems, 35, 32897–32912.
- Bertasius, G., Wang, H., & Torresani, L. (2021). Is space-time attention all you need for video understanding?. In ICML (Vol. 2, pp. 4). ICML.
- Bruce, X., Liu, Y., Zhang, X., Zhong, S.-h., & Chan, K. C. (2022). Mmnet: A model-based multimodal network for human action recognition in rgb-d videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3), 3522–3538.
- Carreira, J., Noland, E., Banki-Horvath, A., Hillier, C., & Zisserman, A. (2018). A short note about kinetics-600. abs/1808.01340.
- Cubuk, E. D., Zoph, B., Shlens, J., & Le, Q. V. (2020). Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (pp. 702–703). IEEE.
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. volume abs/2010.11929.
- Duan, S., Xia, C., Gao, X., Ge, B., Zhang, H., & Li, K.-C. (2022). Multi-modality diversity fusion network with swintransformer for rgb-d salient object detection. In 2022 IEEE international conference on image processing (ICIP) (pp. 1076–1080). IEEE.
- Feichtenhofer, C. (2020). X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 203–213). IEEE COMPUTER SOC.
- Feichtenhofer, C., Fan, H., Malik, J., & He, K. (2019). Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 6202–6211). IEEE COMPUTER SOC.
- Feichtenhofer, C., Pinz, A., & Zisserman, A. (2016). Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1933–1941). IEEE COMPUTER SOC.
- Gao, P., Geng, S., Zhang, R., Ma, T., Fang, R., Zhang, Y., Li, H., & Qiao, Y. (2023). Clip-adapter: Better vision-language models with feature adapters. International journal of computer vision, 1–15. Springer.
- Hajati, F., & Tavakolian, M. (2020). Video classification using deep autoencoder network. In Complex, intelligent, and software intensive systems: Proceedings of the 13th international conference on complex, intelligent, and software intensive systems (CISIS-2019) (pp. 508–518). Springer.
- Hara, K., Kataoka, H., & Satoh, Y. (2018). Can spatiotemporal 3D cnns retrace the history of 2D cnns and imagenet?. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6546–6555). IEEE COMPUTER SOC.
- Hataya, R., Zdenek, J., Yoshizoe, K., & Nakayama, H. (2020). Faster autoaugment: Learning augmentation strategies using backpropagation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV 16 (pp. 1–16). Springer.
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778). IEEE COMPUTER SOC.
- Iashin, V., & Rahtu, E. (2020). Multi-modal dense video captioning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops (pp. 958–959). IEEE.
- Ji, S., Xu, W., Yang, M., & Yu, K. (2012). 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1), 221–231. https://doi.org/10.1109/TPAMI.2012.59
- Jiang, B., Wang, M., Gan, W., Wu, W., & Yan, J. (2019). Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 2000–2009). IEEE COMPUTER SOC.
- Khattab, O., & Zaharia, M. (2020). Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval (pp. 39–48). ASSOC COMPUTING MACHINERY.
- Kim, S., Ahn, D., & Ko, B. C. (2023). Cross-modal learning with 3D deformable attention for action recognition. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 10265–10275). IEEE COMPUTER SOC.
- Kim, W., Son, B., & Kim, I. (2021). Vilt: Vision-and-language transformer without convolution or region supervision. In International conference on machine learning (pp. 5583–5594). PMLR.
- Klaser, A., Marszałek, M., & Schmid, C. (2008). A spatio-temporal descriptor based on 3D-gradients. In BMVC 2008-19th british machine vision conference (pp. 275–1). British Machine Vision Association.
- Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., & Serre, T. (2011). Hmdb: A large video database for human motion recognition. In 2011 International conference on computer vision (pp. 2556–2563). IEEE.
- Langley, P., Provan, G. M., & Smyth, P. (1997). Learning with probabilistic representations. Machine Learning, 29, 2/391–101. https://doi.org/10.1023/A:1007467927290
- Lei, J., Li, L., Zhou, L., Gan, Z., Berg, T. L., Bansal, M., & Liu, J. (2021). Less is more: Clipbert for video-and-language learning via sparse sampling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 7331–7341). IEEE COMPUTER SOC.
- Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., & Hoi, S. C. H (2021). Align before fuse: Vision and language representation learning with momentum distillation. Advances in Neural Information Processing Systems, 34, 9694–9705.
- Li, X., Wang, Y., Zhou, Z., & Qiao, Y. (2020). Smallbignet: Integrating core and contextual views for video classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 1092–1101). IEEE COMPUTER SOC.
- Li, Y., Ji, B., Shi, X., Zhang, J., Kang, B., & Wang, L. (2020). Tea: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 909–918). IEEE COMPUTER SOC.
- Lin, J., Gan, C., & Han, S. (2019). Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 7083–7093). IEEE.
- Lin, Z., Yu, S., Kuang, Z., Pathak, D., & Ramanan, D. (2023). Multimodality helps unimodality: Cross-modal few-shot learning with multimodal models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 19325–19337). IEEE COMPUTER SOC.
- Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2023). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9), 1–35.
- Luo, H., Ji, L., Zhong, M., Chen, Y., Lei, W., Duan, N., & Li, T. (2022). Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 508, 293–304. https://doi.org/10.1016/j.neucom.2022.07.028
- Ma, N., Wu, Z., Cheung, Y.-M., Guo, Y., Gao, Y., Li, J., & Jiang, B (2022). A survey of human action recognition and posture prediction. Tsinghua Science and Technology, 27(6), 973–1001. https://doi.org/10.26599/TST.2021.9010068
- Nanay, B. (2018). Multimodal mental imagery. Cortex; A Journal Devoted to the Study of the Nervous System and Behavior, 105, 125–134. https://doi.org/10.1016/j.cortex.2017.07.006
- Neimark, D., Bar, O., Zohar, M., & Asselmann, D. (2021). Video transformer network. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 3163–3172). IEEE.
- Park, J., Lee, J., Kim, I.-J., & Sohn, K. (2022). Probabilistic representations for video contrastive learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 14711–14721). IEEE COMPUTER SOC.
- Qin, J., Zeng, X., Wu, S., & Zou, Y. (2022). Multi-semantic alignment graph convolutional network. Connection Science, 34(1), 2313–2331. https://doi.org/10.1080/09540091.2022.2115010
- Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., & Krueger, G. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748–8763). PMLR.
- Ramesh, M., & Mahesh, K. (2019). Sports video classification with deep convolution neural network: A test on ucf101 dataset. International Journal of Engineering and Advanced Technology, 8(4S2), 2249–8958.
- Ravuri, S., & Vinyals, O. (2019). Classification accuracy score for conditional generative models. 33rd Conference on Neural Information Processing Systems (NeurIPS)(Vol 32). NEURAL INFORMATION PROCESSING SYSTEMS (NIPS).
- Simonyan, K., & Zisserman, A. (2014). Two-stream convolutional networks for action recognition in videos. 28th Conference on Neural Information Processing Systems (NIPS)(Vol 27). NEURAL INFORMATION PROCESSING SYSTEMS (NIPS).
- Song, S., Liu, J., Li, Y., & Guo, Z. (2020). Modality compensation network: Cross-modal adaptation for action recognition. IEEE Transactions on Image Processing, 29, 3957–3969. https://doi.org/10.1109/TIP.83
- Tian, Y., Wang, Y., Krishnan, D., Tenenbaum, J. B., & Isola, P. (2020). Rethinking few-shot image classification: A good embedding is all you need?. Computer Vision--ECCV 2020: 16th European Conference (pp. 266-282). Springer.
- Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., & Paluri, M. (2018). A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6450–6459). IEEE COMPUER SOC.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I (2017). Attention is all you need. Advances in Neural Information Processing Systems. 30.
- Wang, H., Kläser, A., Schmid, C., & Liu, C.-L (2013). Dense trajectories and motion boundary descriptors for action recognition. International Journal of Computer Vision, 103, 160–79. https://doi.org/10.1007/s11263-012-0594-8
- Wang, H., Tran, D., Torresani, L., & Feiszli, M. (2020). Video modeling with correlation networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 352–361). IEEE COMPUTER SOC.
- Wang, J., Jiao, J., Bao, L., He, S., Liu, Y., & Liu, W. (2019). Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4006–4015). IEEE COMPUTER SOC.
- Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., & Van Gool, L. (2016). Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision (pp. 20–36). Springer.
- Wang, M., Xing, J., Mei, J., Liu, Y., & Jiang, Y. (2023). Actionclip: Adapting language-image pretrained models for video action recognition. IEEE Transactions on Neural Networks and Learning Systems, 1–13.
- Wang, X., Girshick, R., Gupta, A., & He, K. (2018). Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7794–7803). IEEE COMPUTER SOC.
- Xia, C., Duan, S., Fang, X., Gao, X., Sun, Y., Ge, B., Zhang, H., & Li, K.-C. (2022). Efgnet: Encoder steered multi-modality feature guidance network for rgb-d salient object detection. Digital Signal Processing, 131, Article 103775. https://doi.org/10.1016/j.dsp.2022.103775
- Xia, C., Gao, X., Li, K.-C., Zhao, Q., & Zhang, S. (2020). Salient object detection based on distribution-edge guidance and iterative bayesian optimization. Applied Intelligence, 50, 102977–2990. https://doi.org/10.1007/s10489-020-01691-7
- Xia, C., Sun, Y., Li, K.-C., Ge, B., Zhang, H., Jiang, B., & Zhang, J. (2024). Rcnet: Related context-driven network with hierarchical attention for salient object detection. Expert Systems with Applications, 237, Article 121441. https://doi.org/10.1016/j.eswa.2023.121441
- Yamazaki, K., Vo, K., Truong, Q. S., Raj, B., & Le, N. (2023). Vltint: Visual-linguistic transformer-in-transformer for coherent video paragraph captioning. In Proceedings of the AAAI Conference on Artificial intelligence (Vol. 37, pp. 3081–3090). AAAI.
- Zhang, R., Zhang, W., Fang, R., Gao, P., Li, K., Dai, J., Qiao, Y., & Li, H. (2022). Tip-adapter: Training-free adaption of clip for few-shot classification. In European conference on computer vision (pp. 493–510). Springer.
- Zhou, K., Yang, J., Loy, C. C., & Liu, Z. (2022a). Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 16816–16825). IEEE COMPUTER SOC.
- Zhou, K., Yang, J., Loy, C. C., & Liu, Z. (2022b). Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9), 2337–2348. https://doi.org/10.1007/s11263-022-01653-1
Appendix
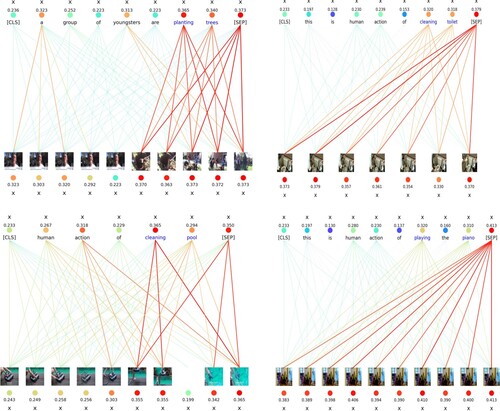
This document brings additional details of experimental results. As shown in Figure , each number above the image represents the maximum similarity between each word and the image, where [SEP] token is the similarity between the entire sentence and each frame. The number at the bottom of the image represents the similarity between each frame and the entire sentence. The sum of the numbers above the image is text-to-video similarity, and the sum of the numbers below the image is video-to-text similarity. Adding and dividing by 2 gives the text to video WTI value, which is consistent with the description in Equation (Equation12(12)
(12) ). More visualisation results of the proposed method are shown in Figure .
Figure A1. Visual picture experimental result for the proposed method, in which blue words are the classification results.
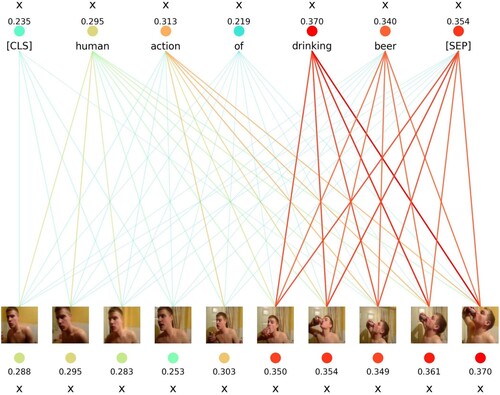
Figure A2. Qualitative results on videos from dataset Kinetics-400.