
ABSTRACT
The emerging field of Labour Market Intelligence focuses on extracting real-time information for professional skills. Online job posting websites provide unique opportunities to gather such intelligence, useful for job seekers and academic administrators in charge of preparing the future labour force. We propose a probabilistic topic modelling approach, incorporating occupational ontologies, to extract skillsets required for jobs needing a Master of Business Administration (MBA) degree. Analysing LinkedIn job postings in Pennsylvania, USA, we identified 28 job functions and associated skillsets confirming known demands and revealing new ones not yet identified in government and private labour market reports. By aggregating these skills, we can align MBA curricula with market needs, offering a superior alternative to conventional surveys. Our results are comparable with other popular neural models. Our approach provides improved computational efficiency with simpler methods Additionally, this methodology can be applied globally in other fields with existing occupational ontologies.
1. Introduction
Labour Market Intelligence (Boselli et al., Citation2018) is an emerging field of study that employs artificial intelligence (AI) tools and frameworks that harness the power of big data to support decision-making of different stakeholders in the employment marketplace. This opens new opportunities for graduate schools of business offering Master of Business Administration (MBA) programmes. Compared to other professional graduate degrees, such as engineering, medicine, law, skills for positions requiring an MBA degree are much more nebulous. They may range from the so-called soft skills (interpersonal, collaborative, communication, leadership) to business skills (contract negotiation, entrepreneurial mindset, planning and organising, decision-making, analytical mindset) to very specific technical skills (inventory planning, portfolio management, budgeting) (Alibasic et al., Citation2022; Rios et al., Citation2020). Also, there is an intense debate as to whether business schools train their MBA graduates with skills that directly translate to the workplace (Alam et al., Citation2021; Rubin & Dierdorff, Citation2013). In response, business schools continuously update their curriculum, based on traditional methods such as case studies (Alam et al., Citation2021), surveys (Prince et al., Citation2015), and reports from professional organisations (Corporate Recruiter’s Survery, Citation2023; Summary Report, Citation2023; “The Graduate Business Education Curriculum Survey” Citation2023). These methods are, however, limited by the amount of data they provide and are also retrospective in nature and thereby run the risk of being dated.
In this regard, professional job posting sites provide the most reliable, real-time, and direct source of information regarding skills and competencies. Hence, we propose a framework to elicit such information for jobs requiring an MBA degree based on online placement ads (Khaouja et al., Citation2021; Rios et al., Citation2020). The objective of our work is to provide timely labour market intelligence to business schools to help them align curricula and train the future workforce with in-demand skills. We gathered 6400 unique job postings from LinkedIn in the period between 15 April and 15 May 2023 in the state of Pennsylvania in the United States (US). In this research, we employ a Bayesian topic modelling approach, ProdLDA (a variation of the widely used Latent Dirichlet Allocation, or LDA method) (Srivastava & Sutton, Citation2017) where the pre-processing and representation tuning steps in the topic discovery pipeline are augmented by incorporating background knowledge encoded in two well-defined ontologies – the European standard classification of occupations (ESCO) (European Commission, Citation2022), and the Occupational Information Network (O*Net) (O*NET). Our analysis of the data set reveals 28 clusters representing specific industry sectors, positions within that sector, and associated skills. About 55,000 industry and position-specific skills, thus extracted, have been further aggregated into 32 broader skill categories utilising a skill hierarchy defined in the ontologies.
Our work makes significant contributions from both methodological and domain perspectives. First, we create our own vocabulary in the pre-processing and representation tuning steps in the topic modelling pipeline for identifying skills that require an MBA degree. This vocabulary is based on standard occupational taxonomies defined across two continents – Europe (ESCO) and North America (ONET) – thus making the process more generalised. Since domain ontologies are created with input from human experts, our process is more explainable compared to other Natural Language Processing (NLP) models where the process of topic discovery may not be entirely transparent. Second, we demonstrate that with sufficiently accurate background knowledge (developed in the prior stage), state-of-the-art performance can be achieved even with simpler topic discovery approaches, comparable to more complicated large language models (LLM) such as BERT (Reimers & Gurevych, Citation2019). Consequently, our approach is more efficient and computationally sustainable and can be used for text classification tasks instead of more computationally intensive LLMs. Finally, from a domain perspective, to the best of our knowledge, there is no scholarly effort yet to create a formal framework for gathering labour market intelligence for graduate business programmes such as the MBA. To this end, our work provides business school administrators and programme directors with a methodology for aligning and adapting their curriculum with current market demand. Furthermore, this method can also be extended to other disciplines with rather broadly defined keywords for skillsets (such as healthcare administration).
2. Related work
2.1. Skill identification from job postings
The most fundamental method of skill identification is a frequency count method based on occurrences of certain keywords. The counting can be performed with or without an existing skill base (Khaouja et al., Citation2021). While apparently simple, changes in the labour market require frequent updates in skill base. On the other hand, qualitative studies mostly rely on content analysis techniques to elicit skills (Sodhi & Son, Citation2010). This method requires extensive expert input and are often time-consuming, therefore not appropriate for large text corpora. Topic Models, discussed in detail, later employ an unsupervised method to discern underlying themes.
A third method employs word embedding techniques where a vector representation of skills occurring together are created by training word embedding models (e.g. Word2Vec) on a collection of job ads (Jaramillo et al., Citation2020). While this method can identify clusters of similar skills, it may also increase the number of false negatives (Khaouja et al., Citation2021).
Finally, the fourth method employs various supervised machine learning techniques. These methods use deep learning to identify named entities from text or use Long Short-Term Memory (LSTM) or Bidirectional Encoder Representations from Transformers (BERT) (Cao & Zhang, Citation2021). While these methods are powerful in uncovering hidden relationships between words, they are computationally quite intensive and require an annotated dataset.
We find topic modelling to be the most appropriate for our purpose since there are no pre-defined skills dataset for jobs requiring an MBA degree. Also, note that these methods are not mutually exclusive of one another. As we discuss below, employing word embedding in the text processing pipeline in our topic modelling framework results in efficient outcome.
2.2. Topic modelling and discovery
Topic modelling refers to a class of unsupervised machine-learning techniques used for information retrieval (Abdelrazek et al., Citation2022; Churchill & Singh, Citation2022). The purpose is to uncover underlying themes hidden in a collection of documents used as input, the output being a summary capturing the most prevalent subjects (i.e. topics) in the input corpus.
While research on topic models dates to algebraic models in the 1990s, the introduction of Latent Dirichlet Allocation (LDA) (Blei et al., Citation2003), has ushered in the widespread use of Bayesian probabilistic topic models. These models gained popularity in many different domains due to their relative ease of use, interpretability, and computational efficiency (Abdelrazek et al., Citation2022; Churchill & Singh, Citation2022).
Once data collection is complete, the typical topic discovery pipelines include three general steps: 1) document text embedding, 2) some form of unsupervised clustering, and 3) an optional post-processing step for further fine-tuning or generalisation of the identified topics’ keywords. Usually, the first and third steps typically employ LLMs. Following other scholars (Luthfi et al., Citation2020), we incorporate background knowledge to leverage external information for potential performance improvement. Such background knowledge may already be codified in different domain-specific knowledge structures such as databases, taxonomies, and ontologies. Below, we discuss two sources of existing knowledge that pertain to our research objective.
2.2.1. Background knowledge
The background knowledge is drawn from two occupation-skill ontologies ESCO (European Commission, Citation2022) and O*Net (O*NET). The ESCO taxonomy provides descriptions of 3,008 occupations and 13,890 skills linked to these occupations in the European labour market. The O*Net, on the other hand, is developed for the North American economy by the US Department of Labour. It contains 923 occupations and is continually updated. We use the crosswalk between the ESCO and O*Net classifications for occupations to connect the two international standards to create a comprehensive list of occupations related to an MBA degree. To the best of our knowledge, our work is the first one to utilise such a combined set of occupations spanning two continents. The use of such background knowledge serves two important purposes. First, the text describing each skill in ESCO and O*Net defines the vocabulary of possible tokens. Second, the final fine-tuning step exploits the hierarchy of the skills pillar in the ESCO ontology ESCO Publications, 2019; Malandri et al., Citation2021). This hierarchy defines skills in progressively granular levels for occupation-specific roles. One such example is: skills (Level 0) > S1.0: communication, collaboration, and creativity (Level 1) > S1.1: Negotiating (Level 2) > S.1.1.1: negotiating and managing contracts and agreements (Level 3) > develop licencing agreements (Level 4). Using this hierarchy, it is possible to select the level of aggregation (generalisation) of identified skills into broader concepts. This is exactly the role of the LLM in the typical fine-tuning steps of topic modelling; however, many unsupervised learning models make this step a black box. Exploiting the background knowledge encoded the ESCO and O*Net ontologies, both the text embedding and, more importantly, the fine-tuning (generalisation) steps of the whole pipeline become completely explainable.
3. Research setting and methodology
Our text processing pipeline is depicted in . Details of each of the steps are elaborated in the sections below.
Figure 1. Text processing pipeline.
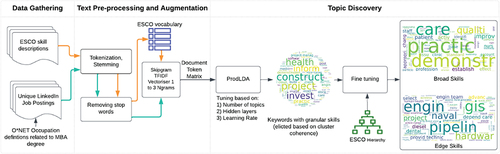
3.1. Data gathering
Using the O*NET ontology linking educational outcomes and occupations, we identified a set of 55 occupations provided by the Classification of Instructional Programmes (CIP) that are related to MBA educational outcomes. CIP 52.0201 and CIP 52.0703 are related to 45 general and 10 small business and administration occupations, respectively. Using these as a query text and setting geographical boundaries in Pennsylvania, US, we scraped 6400 unique full-text job postings between 15 April −15 May 2023 from LinkedIn. For the analysis, we used the entire posted text without removing any segments. This step is shown in the first swimlane in .
We exhaustively included all 13,890 skills in ESCO so as not to limit ourselves.
3.2. Text pre-processing and augmentation
The next step comprises tokenisation, stemming and vectorisation, resulting in a document-token matrix (Chakrabarti, Citation2002). Tokenisation is the process of breaking down the document into different words, resulting in a bag of words for each document. The tokenised words enter the stemmer, a program for producing morphological variants of a root word (e.g. ‘care’, ‘cared’, and ‘caring’ to the stem ‘care’). We used the Snowball stemmer. Finally, we removed stop words (such as ‘a’, ‘the’, ‘on’), using the NLTK (Natural Language Toolkit).
Both ESCO skill descriptions and the job postings corpora go through the same text pre-processing pipeline independently. The result from the ESCO text pre-processing finishes into a vocabulary. This vocabulary is used to generate up to 3 skipgrams (tokens) (Guthrie et al., Citation2006), an algorithm that returns the occurrence of one, two or three words together in a bag of words. The obtained skipgrams are used as columns in a matrix, while the rows are each of the job postings. The matrix is transformed using Term Frequency Inverse Document Frequency (TF-IDF) (Baeza-Yates & Ribeiro-Neto, Citation1999), resulting in a document token matrix. The process is shown in the second swimlane in .
3.3. Topic modelling
The result of any topic modelling is a set of topics and corresponding tokens (keywords) with their associated weights. In many cases, these keywords tend to be very specific, and usually, topic discovery approaches have an additional optional step that performs so-called fine-tuning of the topics to obtain broader, more generalisable topic lists. This step most commonly relies on LLMs. The third swimlane in represents this final and most important step. Details of each step are described below.
3.3.1. Topic discovery with latent Dirichlet allocation with product of experts (ProdLDA)
The LDA follows the Bayesian network modelling. It is a probabilistic one where the prior is estimated using the Dirichlet distribution (a continuous probability distribution, which is a multivariate generalisation of the beta distribution). It is frequently used to model the uncertainty about a vector of unknown probabilities. To infer the number of topics using LDA (Blei, Citation2012), the documents are considered to belong to latent topics with a certain weight. Each topic is characterised by a distribution of all the words in all documents.
In LDA, the distribution of the words in a document given two parameters (α and β, parameters of the Dirichlet prior on the per-document topic and per-topic word distributions) is a mixture of multinomials and cannot make predictions that are sharper than the components that are being mixed. The ProdLDA algorithm (Srivastava & Sutton, Citation2017) resolves this issue and provides a drastic improvement in topic coherence by replacing the mixture of multinomials with a weighted product of experts (PoE), a machine learning algorithm capable of making sharper predictions than any of the constituent experts (Hinton, Citation2002).
The outcome of this sub-step is the detection of 28 topic clusters of skill sets based on cluster coherence measures. Detailed description and insights from these clusters are provided in section 4.3. Each skill area (identified as a topic) has a set of finely granular skills associated with a corresponding weight. Some of the topics need further narrowing down, as the associated individual keywords for some topic clusters can go up to 1500. For better interpretability and usefulness, these skill sets need to be aggregated into a broader set through fine-tuning. This sub-step is discussed next. Using the skills relationship in ESCO, one can generate a directed graph where edges are directed towards a broader skill. Such a graph is shown in .
Figure 2. Procedure for determining coarser skills. (a) relation among skills from narrower to broader. (b) the red node is the selected skill from the set of keywords. (c) sub-graph of related skills to a top skill marked with green. (d) yellow nodes are coarser skills that are three edges from the top skill.

3.3.2. Fine-tuning the topic representation
This step harnesses the relationship information encoded in the ESCO ontology. We selected the top 75% of the keywords in the skills identified in the previous sub-step. The procedure starts from the selected skill using the full-text search, i.e. the red node in . Traversing the ESCO graph from this starting point provides a sub-graph of reachable skills. This sub-graph can have one or more nodes whose out-degree is zero, i.e. skills that do not have broader concepts (e.g. green node in ). The identified coarser occupations, yellow nodes in , are the leaves of the edge graph that are at least three edges away from the most general skill. The selected radius of three edges is considered a hyperparameter defining the ‘zoom’ level. The rationale behind the choice of level three is that the majority of ESCO skills form a hierarchy that is four levels deep.
4. Results
First, we focus on the performance of the ProdLDA model, followed by the analysis and discussion of the discovered skills and competencies. We compared our results with LLM-based topic discovery method sBERT (Reimers & Gurevych, Citation2019). Details are discussed below.
4.1. Hyper parameter tuning
One of the most common ways to check model performance in topic discovery is through topic coherence measures (Lau et al., Citation2014). The ProdLDA model has three hyperparameters to be selected: The number of topics, the number of hidden layers of the encoder/decoder networks, and the learning rate. Performing a grid search was feasible since the number of possible combinations was in the rank of 103. Since the training process was not computationally so demanding, we trained separate models for each triplet of parameter values. The results are shown in .
Figure 3. Coherence measures changes based on the number of topics and the number of hidden layers of the encoder/decoder. The spread is calculated based on the variation of the learning rate parameter.
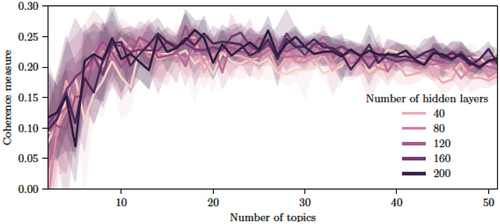
The normalised log-ratio coherence measure was used (Lau et al., Citation2014). The spread in the plots is calculated based on the variation of the topic coherence vs the learning rate for a particular combination of number of hidden layers and topics. Note that the values reach a steady plateau around 20 topics. It turned out that the number of hidden layers does not make a significant difference, although more complex networks tend to provide better topic coherence results. As expected, the coherence measure decreases as the number of topics increases.
As we observe from , the optimum number of clusters is somewhere between 20 and 30. We decided on 28 clusters to balance granularity and interpretability. Based on these results, the subsequent analysis was performed using a ProdLDA model with 28 topics, 160 hidden nodes and a dropout rate of 0.2 during the training. The training used Adam optimiser (Kingma & Ba, Citation2014) with learning rate of 10.3.
4.2. Topic diversity measure
In addition to topic coherence, set of topics were evaluated using topic diversity. Dieng et al. (Citation2020) defined topic diversity as percentage of unique words in the top 25 words of all topics. As a result, larger values are preferred, ideally values close to 1 (or 100%). In our case, the ProdLDA model has topic diversity of 88%, whereas sBERT achieved 61%.
4.3. Identification of various job functions and associated skillsets
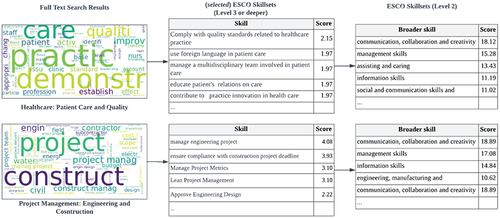
Of the 28 identified topic clusters, two are shown as examples in . Each topic cluster contains tokenised keywords from the job posting corpora. Since there are far too many keywords (about 15,000) at this stage to provide a broad picture, they are mapped to skills in the ESCO level 3 hierarchy or deeper using the method described in section 2.2.1. Each one of such mapped skills is assigned a score, representing the sum of the weighted importance of all keywords that are associated with the skill’s description.
Figure 4. Selected topics and keywords.

Closer inspection of the union of those level 3 (or deeper) skills in a cluster (by the director of the MBA programme and other industry experts) reveals key requirements for a specific type of job function, often within an industry sector. For example, Topic 6 skills relate to providing quality patient care in healthcare. Topic 19 is associated with project management skills, mainly in engineering and construction projects. provides the demand distribution associated with each of the 28 topics. Note that probabilistic topic models allow a posting to belong to multiple categories, e.g. the position listing for the executive leadership of a hospital will fall into the strategic leadership, healthcare, as well as global collaboration and people management categories, albeit with different weights for each job function. The first two blocks of show the identification of the skill sets in detail (for the two selected topic clusters, i.e. job functions) from the individual keywords to their associated level 3 skillsets.
Figure 5. Topic (job function, and/or industry sector) clusters and number of openings.
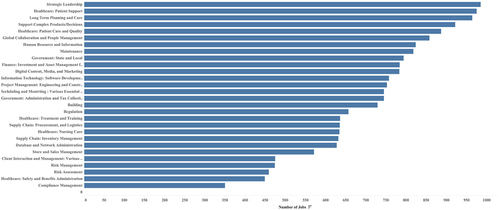
Figure 6. From full-text search results to granular and subsequent broader skill sets.
4.3.1. Broad skill sets
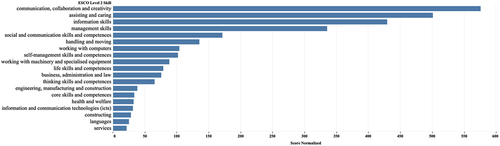
For all identified 28 industry sectors and positions (i.e. topics), a total of 54,818 ESCO level 3 (or deeper) skills were extracted from the text corpora. It should be noted that at this stage, some full-text results are repeated since the fine-tuning step can result in several equally probable broader concepts for a specific skill (yellow nodes in ). The number of skill sets for a category ranges from 252 to 3800, with a median of 2000. While such granular information is very useful for both job seekers and university administrators for grasping the requirements of the current labour market in specific functional areas, a somewhat aggregation and abstraction of the skillsets is also necessary from a curriculum design perspective (Amblee et al., Citation2023). In this regard, the ESCO skill hierarchy is helpful in that each of the identified narrow skillsets is mapped to broader skillsets. The last two blocks of show the aggregation of broader Level 2 skill sets (corresponding to the two selected topic clusters in ) from the associated level 3 (or deeper) skillsets. Subsequently, the 54,818 skillsets are narrowed to 32 broader ESCO level 2 skills. Of these, the top 19 are shown in , where the normalised scores show the importance of each broader skill across the various job functions.
Figure 7. Relative significance of extracted skills.
4.4. Insights from the job functions and skill sets
The topic clusters provide labour market intelligence in Pennsylvania, offering much greater insights than government or other private party reports in terms of depth and granularity. For example, sectors such Healthcare-related fields are consistent with the reports provided by the Pennsylvania Centre for Workforce Information and Analysis China Weighing Instrument Association (CWIA, Citation2023). Our analysis, however, reveals four distinct healthcare-related functions – patient care and quality, nursing care, patient treatment and training, and patient support (these categories identified here pertain to business administration skills, not clinical skills). While some of these categories are expected for job seekers with an MBA degree (such as strategic leadership), somewhat unanticipated are the prevalence of different state and local government jobs, maintenance, as well as digital content media and marketing. Real-time demand information () about these under-the-radar sectors can be utilised by business school administrators for enrolment growth (through customised curriculum and target marketing) as well as student career counselling for seeking new career opportunities.
From a skills perspective, some (communication, collaboration, and creativity, information, management, and social and communication skills) align fairly well with the competencies identified in the seminal work (Rubin & Dierdorff, Citation2009). Other skills, to the best of our knowledge, are unique in the literature regarding the graduate business curriculum. One such example is the skill ‘Assisting and Caring’ (ESCO definition: ‘providing assistance, nurturing, care, service and support to people, and ensuring compliance to rules, standards, guidelines or laws’). To get a better understanding of how these broad skill categories relate to the 28 topic clusters, we plotted their mapping and relative significance (as captured in the significance scores) (not shown here). Closer inspection reveals that Assisting and Caring skills are also necessary for strategic leadership and complex product/service decisions.
Taken together, our work provides empirical evidence for graduate business schools in Pennsylvania to update their MBA programmes by offering focussed curriculum that fulfil the demand for labour in areas that are not yet captured in traditional reports. Furthermore, the spread of broader skills across job functions and/or industry sectors provides important pointers for curriculum development and revision. Indeed, our finding that communication, collaboration, and social communication skills (broader skills 1 and 5) are crucial across many job categories tend to support recent research in graduate management education (Amblee et al., Citation2023) that Managing Human Capital is a crucial competency for MBA curriculum.
4.5. Comparison with sBERT
To validate the topics obtained using ProdLDA, we repeated the analysis using Sentence-BERT (sBERT) (Reimers & Gurevych, Citation2019), a modification of the Bidirectional Encoder Representations from Transformers (BERT), a neural model that uses siamese triplet networks to produce a sentence embedding. We specifically chose sBERT because of its state-of-the-art performance in clustering and information retrieval on a large scale (Suryadjaja & Mandala, Citation2021), with slightly modification. We tried three different variations:
automatic detection of the number of topics allowing up to 3 n-gram tokens,
using the skip-gram vectoriser with automatic detection of the number of topics, and
using the skip-gram vectoriser and tuning the number of topics based on topic coherence values.
The 1st provided 135 and the 2nd provided 83 topics. The topic coherence values were 0.05 ± 1.5 and 0.3 ± 0.31, respectively. Since topic coherence was used to select the number of topics in the LDA approach, the same method is followed here as well. The change in the topic coherence value over varying number of topics are shown in .
Figure 8. Topic coherence in the SBERT text processing pipeline.
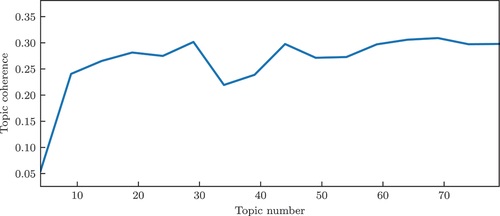
Similar to our approach using ProdLDA (), the topic coherence reaches a plateau of around 28 topics in this case, too. Using the same number of topics as in the LDA approach results in an almost identical set of topics and corresponding features
Our results thus show that both approaches provide comparable performance. Increasing the number of topics does not lead to increased coherence. Using the same number of topics as in the LDA approach results in an almost identical set of topics and corresponding features.
5. Conclusion
Labour Market Intelligence is becoming a topic of increasing importance due to various factors – the rise of hybrid work, the advent and rapid embracing of generative AI in business, economic and demographic shifts, advances in technology – to name a few. Understanding the changes in the labour market in a timely manner is not only crucial for job seekers but also for educational institutions who prepare the labour force for the future. In this regard, AI-enabled labour market intelligence presents a special opportunity for business schools as the skill requirements for graduates vary widely compared to other professions. The first step in this endeavour is the creation of an inventory of current and emerging skillsets and associated positions, preferably utilising extensive data sources available from prominent online job posting sites where employers communicate directly with job seekers (Khaouja et al., Citation2021). In this regard, we utilise job postings from LinkedIn, the predominant professional networking website for positions requiring/preferring an MBA degree in the state of Pennsylvania, US. The geographic constraint is used as a means to appropriately scope the problem at hand. To validate, our results are compared with the popular neural model sBERT, and we show that it is possible to achieve state-of-the-art performance and improved computational efficiency with simpler methods. Furthermore, given that the background knowledge embedded in the ESCO ontology is translatable in 28 different languages, our framework is highly transferable to other countries.
At this point, the limitations of our work must also be acknowledged. We are constrained by the limitations of the ESCO and O*Net ontologies as these are used as background knowledge in the pre-processing and representation tuning steps. Also, Pennsylvania is a fairly large state, with demographics and market demand varying from one region to another. Further geo-labels associated with the job functions may be required for more actionable insights for institutions located in different parts of the state. At a general level, this limitation pertains to choosing the appropriate boundary -geographic or otherwise – for the corpora of job postings.
Our research contributes to the growing call for the need for the creation of standardised labour market intelligence frameworks (Boselli et al., Citation2018). Indeed, our use of the O*Net and ESCO ontologies in skill extraction and aggregation are in alignment with this philosophy that the use of standard taxonomy of occupations is an instrumental part of fact-based decision-making and faster time to market. The identification of yet undiscovered skills pertinent to graduates of MBA programmes provides input to prominent accreditation bodies for graduate business education towards setting standards for MBA programme learning goals. In future, we would like to expand this research by utilising the geo-tags associated with the job postings, so that higher level of granularity in the identified skill sets can be utilised. Furthermore, longitudinal data would help us uncover emerging trends in skills, a topic of utmost importance in the current labour market given the significant impact of generative AI and similar technologies in the workplace. The general framework of the text processing pipeline, presented in this research, can also be extended to other domain areas (such as healthcare administration, law, software development) that require a wide range of technical and soft skills.
Code availability
The numerical implementation of the analysed projections and corresponding data sets is available at https://repo.ijs.si/bmileva/penn.git.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Biljana Mileva Boshkoska
Biljana Mileva Boshkoska is an associate professor at Faculty of Information Studies in Novo Mesto Ljubljana, Ljubljana, Slovenia. She received her Ph. D. from Jozef Stefan Institute. Her research focuses on decision support, statistical modelling, data mining, and modelling of technical and nontechnical systems. Her work has been published in Computers in industry, PLoS One, Journal of Decision Systems, Informatica, International Journal of Decision Support System Technology, and Journal of Intelligent Manufacturing. She has served as programme chair and research track chair in various conferences.
Sagnika Sen
Sagnika Sen is an associate professor of Information Systems in the School of Graduate Professional Studies at Pennsylvania State University. She received her Ph.D. from Arizona State University. Her research focuses on process performance, metrics and incentive design, and the use of data-driven decision models to obtain analytical insights on various domains – healthcare, information security, graduate business education, etc. Her work has been published journals such as Information Systems Research, Journal of Management Information Systems, Decision Support Systems, Expert Systems with Applications, Information and Management, Communications of the ACM, Human Resources Management, Service Sciences, Journal of Managerial Psychology, and BMC Health Services Research. She has served in various executive roles for the AIS Special Interest Group on Decision Support and Analytics (SIGDSA) and is currently serves as an advisory board member.
Pavle Boškoski
Pavle Boškoski is an associate professor at the department of Systems and Control at Jožef Stefan Institute. He received his Ph. D. from Jozef Stefan Institute. His research focuses on signal processing, system identification, stochastic analysis, Bayesian inference and HPC. His work has been published journals such as Expert Systems with Applications, Journal of Power Sources, Brain and Behavior, Knowledge-Based Systems, Applied Energy, Annals of Oncology, and IEEE access.
References
- Abdelrazek, A., Eid, Y., Gawish, E., Medhat, W., & Hassan, A. (2022). Topic modeling algorithms and applications: A survey. Information Systems, 102131. https://doi.org/10.1016/j.is.2022.102131
- Alam, G.M., Morsheda, P., Ahmad Fauzi Bin Mohd, A., Kader, R., & Rahman, M.M. (2021). Does an MBA degree advance business management skill or in fact create horizontal and vertical mismatches? [MBA advances skills: Time to rethink]. Business Process Management Journal, 27(4), 1238–1255. https://doi.org/10.1108/BPMJ-10-2020-0465
- Alibasic, A., Upadhyay, H., Simsekler, M.C.E., Kurfess, T., Woon, W.L., & Omar, M.A. (2022). Evaluation of the trends in jobs and skill-sets using data analytics: A case study. Journal of Big Data, 9(1), 32. https://doi.org/10.1186/s40537-022-00576-5
- Amblee, N., Ertl, H., & Dhayanithy, D. (2023). A more relevant MBA: The role of across-the-curriculum delivery of intercompetency coursework in aligning the required curriculum with required managerial competencies. Journal of Management Education, 47(2), 204–238. https://doi.org/10.1177/10525629221121700
- Baeza-Yates, R., & Ribeiro-Neto, B. (1999). Modern information retrieval (Vol. 463). ACM press.
- Blei, D.M. (2012). Probabilistic Topic Models communications of the ACM. Obtenido de, 55(4), 77–84. https://doi.org/10.1145/2133806.2133826
- Blei, D.M., Ng, A.Y., & Jordan, M.I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3(Jan), 993–1022.
- Boselli, R., Cesarini, M., Mercorio, F., & Mezzanzanica, M. (2018). Classifying online job advertisements through machine learning. Future Generation Computer Systems, 86, 319–328. https://doi.org/10.1016/j.future.2018.03.035
- Cao, L., & Zhang, J. (2021). Skill requirements analysis for data analysts based on named entities recognition. 2021 2nd International Conference on Big Data and Informatization Education (ICBDIE), Hangzhou, China.
- Chakrabarti, S. (2002). Mining the web: Discovering knowledge from hypertext data. Morgan Kaufmann.
- China Weighing Instrument Association. (2023). 2023 Pennsylvania In-demand occupations list. https://www.workstats.dli.pa.gov/Documents/PA%20IDOL/PA%20IDOL.pdf
- Churchill, R., & Singh, L. (2022). The evolution of topic modeling. ACM Computing Surveys, 54(10s), Article 215. https://doi.org/10.1145/3507900
- Corporate Recruiter’s Survery: 2023 Summary Report. (2023).
- Dieng, A. B., Ruiz, F. J., & Blei, D. M. (2020). Topic modeling in embedding spaces. Transactions of the Association for Computational Linguistics, 8, 439–453.
- European Commission. (2022). What is ESCO?. https://esco.ec.europa.eu/en/about-esco/what-esco
- The Graduate Business Education Curriculum Survey. (2023). https://gbcroundtable.org/
- Guthrie, D., Allison, B., Liu, W., Guthrie, L., & Wilks, Y. (2006). A closer look at skip-gram modelling. Language Resources and Evaluation.
- Hinton, G.E. (2002). Training products of experts by minimizing contrastive divergence. Neural Computation, 14(8), 1771–1800. https://doi.org/10.1162/089976602760128018
- Jaramillo, C.M., Squires, P., Kaufman, H.G., Silva, A.M.D., & Togelius, J. (2020, December 10-13). Word embedding for job market spatial representation: Tracking changes and predicting skills demand. 2020 IEEE International Conference on Big Data (Big Data), Online Virtual conference.
- Khaouja, I., Kassou, I., & Ghogho, M. (2021). A survey on skill identification from online job ads. IEEE Access, 9, 118134–118153. https://doi.org/10.1109/ACCESS.2021.3106120
- Kingma, D.P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization International Conference on Learning Representations (ICLR), San Diego. http://arxiv.org/abs/1412.6980
- Lau, J.H., Newman, D., & Baldwin, T. (2014). Machine reading tea leaves: Automatically evaluating topic coherence and topic model quality. Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden.
- Luthfi, M., Goto, S., & Ytshi, O. (2020, August 14-16). Analysis on the Usage of Topic Model with background knowledge inside discussion activity in industrial engineering context. 2020 IEEE International Conference on Smart Internet of Things (SmartIoT), O*NET. O*NET Online. https://www.onetonline.org/
- Malandri, L., Mercorio, F., Mezzanzanica, M., & Nobani, N. (2021). MEET-LM: A method for embeddings evaluation for taxonomic data in the labour market. Computers in Industry, 124, 103341. https://doi.org/10.1016/j.compind.2020.103341
- Prince, M., Burns, D., Lu, X., & Winsor, R. (2015). Knowledge and skills transfer between MBA and workplace. Journal of Workplace Learning, 27(3), 207–225. https://doi.org/10.1108/JWL-06-2014-0047
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence embeddings using siamese BERT-networks. Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China.
- Rios, J.A., Ling, G., Pugh, R., Becker, D., & Bacall, A. (2020). Identifying critical 21st-century skills for workplace success: A content analysis of job advertisements. Educational Researcher, 49(2), 80–89. https://doi.org/10.3102/0013189X19890600
- Rubin, R.S., & Dierdorff, E.C. (2009). How relevant is the MBA? Assessing the alignment of required curricula and required managerial competencies [article]. Academy of Management Learning & Education, 8(2), 208–224. https://doi.org/10.5465/AMLE.2009.41788843
- Rubin, R.S., & Dierdorff, E.C. (2013). Building a better MBA: From a decade of Critique Toward a Decennium of Creation. Academy of Management Learning & Education, 12(1), 125–141. https://doi.org/10.5465/amle.2012.0217
- Sodhi, M.S., & Son, B.G. (2010). Content analysis of or job advertisements to infer required skills. Journal of the Operational Research Society, 61(9), 1315–1327. https://doi.org/10.1057/jors.2009.80
- Srivastava, A., & Sutton, C. (2017). Autoencoding variational inference for topic models. arXiv Preprint arXiv: 170301488, Toulon, France.
- Suryadjaja, P.S., & Mandala, R. (2021, September 29-30). Improving the performance of the extractive text summarization by a novel topic modeling and sentence embedding technique using SBERT. 2021 8th International Conference on Advanced Informatics: Concepts, Theory and Applications (ICAICTA), Online Virtual Conference, September 29–30 2021.