
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Digital twin railway is a pivotal foundation for the intelligent construction and maintenance of railway engineering projects within extensive open spaces. Its essence is the integrated representation and association management of multi-granularity spatiotemporal data, executable analysis models, and professional knowledge. These elements are characterized by the prominent characteristics of multi-source, heterogeneity, and massive volume. However, current decentralized and independent management strategies often neglect the dynamic coupling relationships between them, and numerous multi-path joins and conversion aggregation operations exist across various spatial scale applications. Consequently, this results in challenges such as the inability to dynamically couple data-model-knowledge and conduct global association retrieval, thereby limiting the potential for real-time analysis and intelligent application capabilities. To address these problems, we first constructed a tripartite graph model () that explicitly associates temporal, spatial, and interactive relationships. Subsequently, an association management architecture was proposed, accompanied by a global association graph index (
) and a global-local indexing mechanism. Finally, a prototype system for railway data-model-knowledge association management was developed. The effectiveness of the distributed association management method was demonstrated by employing a case study of high-temperature safety risk analysis in railway tunnel engineering with multi-physics field coupling.
1. Introduction
Digital twin railway represents a pivotal technology for the intelligent construction and maintenance of high-speed railway engineering (Broo, Bravo-Haro, and Schooling Citation2022; C. Lu et al. Citation2019; Y. Gao et al. Citation2021), which attempts to provide comprehensive real-time feedback on multi-dimensional, multi-disciplinary feature entities and their spatiotemporal evolution processes throughout the entire lifecycle (Jones et al. Citation2020). Currently, spatiotemporal data, executable analysis models, and professional knowledge are typically managed independently and dispersed across various departmental business systems (McMahon, Zhang, and Dwight Citation2020; S. Li et al. Citation2016). This is primarily because railways are often physically spaced in multiple sections for parallel construction and operation (Profillidis Citation2016). Although the existing decentralized and independent management strategies can satisfy certain specialized applications, they neglect the dynamic coupling relationships between them (H. Li, Zhu, et al. Citation2022). In this scenario, decentralized databases, model bases, and knowledge bases exist in isolation within the information space. The current workflow necessitates extensive collaboration among professionals, often involving coordination across different railway sections. The process of finding appropriate services is both time-consuming and burdensome. This causes difficulties in delivering holistic and systematic data-model-knowledge services across geographical regions, departments, business systems, lifecycle stages, hierarchical levels, and professional domains (Semeraro et al. Citation2021; Yang et al. Citation2020). Therefore, efficient association management of distributed data, models, and knowledge is crucial for facilitating intelligent applications of digital twin railway.
With the integration of advanced technologies such as virtual geographical environments, building information modeling (BIM), and the Internet of Things (IoT) in railway infrastructure (Ning et al. Citation2020), multi-granularity data, models, and knowledge have been extensively and routinely utilized in diverse railway applications at three typical spatial scales (regional, engineering, and construction site scales) (Wu et al. Citation2022). However, the multi-source, heterogeneity, and massive volume characteristics of this information make their association relationships insufficient and increase acquisition costs. These constraints hinder the ability to dynamically couple data-model-knowledge in real-time applications (H. Li, Zhu, et al. Citation2022; L. Ding et al. Citation2020). In addition, diverse business systems adopt individualized information organizational patterns (J. Lu, Holubová, and Holubová Citation2019). As data, models, and knowledge integrate to deliver key functionalities, a large number of multi-path joins and conversion aggregation operations may be generated, which subsequently influences the timeliness of dynamic feedback between physical space and information space (Park and Cheng Citation2023; W. Li, Batty, and Goodchild Citation2020). Despite recent advancements in distributed management and spatiotemporal indexing, these difficulties still cause challenges that should be addressed. An additional explanation of these challenges is presented in .
Figure 1. Pervasive challenges of current decentralized and independent management strategies. Figure (a) depicts a general analysis process where implicit and incomplete relationships between objects are emphasized. Figure (b) expresses the inconsistent organizational strategy of data, models, and knowledge commonly observed in most railway engineering projects. (a) Insufficient association relationships and (b) Inconsistent organizational patterns.
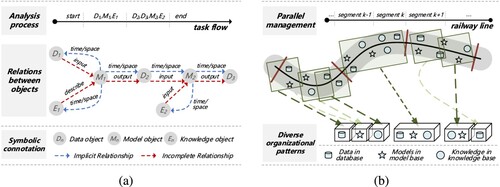
(1) Implicit and incomplete association relationships. Although most metadata carry basic temporal and two-dimensional spatial attributes, enabling the calculation of fundamental spatiotemporal relationships, we contend that these implicit relationships are insufficient to support dynamically couple data-model-knowledge (Bloch and Sacks Citation2020; Deng, Jia, and Chen Citation2019). In addition, inherent characteristics such as multi-source and heterogeneity inevitably result in incomplete association relationships. The multi-source aspect refers to data, models, and knowledge from various production departments, diverse business systems, and multiple types of physical sensors. Heterogeneity encompasses the syntactic, structural, and semantic processes (Asfand-E-Yar and Ali Citation2020). Therefore, the most practical solution may be predefining an extensible set of explicit association-relationship rules for data, models, and knowledge.
(2) Inefficient global accessibility. Dividing the railway's physical space into sections naturally separates the information space. Because of variations in sharing methods and policies, interdisciplinary collaborators often struggle to become acquainted with this information, which hinders their ability to retrieve the required results accurately and efficiently (H. Li et al. Citation2021). Furthermore, individualized database application patterns are highly integrated with business systems, and retrieving and flowing identical information across different applications may require numerous object-relational mappings, correlated subqueries, and stored procedures (Ravat et al. Citation2020). This significantly burdens the processes driven by the data, models, or knowledge of digital twin railway. A comprehensive management from a global perspective on multiple railway sections is a viable solution to improve this issue.
Generally, the scope of our research about railway engineering is centered on the technical aspects of the digital twin railway information space, encompassing distributed data, models, and knowledge throughout the entire lifecycle. The primary research question is to establish explicit association capabilities and global accessibility between distributed data, models, and knowledge. To address this, our study introduces an efficient distributed association management method that considers temporal, spatial, and interactive relationships. The intuitive principle of our method lies in developing an association graph model, implemented as an association graph index and integrated into a specialized management architecture, to facilitate effective global association management. The major advantages of the proposed method are as follows: (1) it provides a practical solution for dynamically coupling data, models, and knowledge utilizing explicit relationships; and (2) the association graph index enables effective global association retrieval throughout the entire lifecycle.
The remainder of this paper is organized as follows. Section 2 briefly reviews related research. Section 3.1 introduces the workflow of the proposed method and problem setup. Sections 3.2 to 3.3 elaborate the methodological details encompassing the association management architecture, global association graph index generation algorithm, and global-local index mechanism. Section 4 describes the prototype system, a use case, experiments, and discussions. Finally, the last section concludes the paper.
2. Related works
The most relevant literature in this context can be grouped into three broad categories: (1) Data, models, and knowledge management; (2) Spatiotemporal data models; and (3) Indexing methods in distributed environments.
(1) Data, models, and knowledge management. Recent developments in distributed information systems in tandem with relational and NoSQL databases have proven their effectiveness in organizing and managing structured, semi-structured, and unstructured railway information (Sahal, Breslin, and Ali Citation2020; Z. Zhang and Li Citation2020). For the management of spatiotemporal data, some digital twin railway applications have adopted dedicated storage and management systems, such as distributed file systems (Suleykin, Panfilov, and Bakhtadze Citation2019), document-based systems (J. Li et al. Citation2019), and hybrid cloud-based systems (Sarkar, Patel, and Dave Citation2022). These systems support diverse business processes throughout the lifecycle of railway operations (Doubell et al. Citation2021). In executable analysis model management, the focus is on enabling model sharing and reuse. Consequently, many interoperability standards and services have been established (F. Zhang et al. Citation2021), such as OpenGMS (Qiao et al. Citation2021) and OpenMI2.0 (Harpham, Hughes, and Moore Citation2019). These standards provide a framework for the model description, publication, management, invocation, and composition of complex models in service chains (Chen et al. Citation2020). The two primary knowledge management strategies are relationship-based management (e.g. Jena and RDF) and native graph management (e.g. Neo4J) (W. Li, Wang, et al. Citation2022). Knowledge graphs have emerged as the most promising and popular methods (Ji et al. Citation2021).
Despite some strides in integrated management (Candel, Ruiz, and Garca-Molina Citation2022; G. Lü, Batty, et al. Citation2019), the comprehensive management of multi-source, heterogeneous, and dispersed railway information remains a significant challenge (H. Li, Zhu, et al. Citation2022). To address these challenges, there is still a pressing need for a holistic management architecture specifically designed to explicitly associate decentralized data, models, and knowledge for digital twin railway.
(2) Spatiotemporal data models. Railway entities typically carry temporal and spatial markers, and a suitable spatiotemporal data model is crucial to their integration and management (Ma et al. Citation2020). Common spatiotemporal data models primarily focus on archiving temporal snapshots of changes in entities, as seen in space-time cube models, snapshot sequence models, and others (F. Gao et al. Citation2022; Z. He et al. Citation2020). They accentuate object modifications, emphasizing relationship alterations, as depicted in object-oriented models, process-oriented models, and similar concepts. Alternatively, they center on events and activities, detailing the semantic relationships of entity changes, as with event-based or ontology-based models (Ma et al. Citation2020). Moreover, several globally recognized data models that aspire to utilize a unified model have been developed to represent and disseminate railway network information. Among these, Industry Foundation Classes (IFC) and RailTopoModel (RTM) stand out (Bischof and Schenner Citation2021). The IFC focuses on the design phase, showcasing robust applications in this area. In contrast, RTM targets the operational phase and is particularly effective in applications such as integrating data from terrestrial-monitoring devices and near-field communication systems, enhancing the intelligent maintenance of railway infrastructure (Kampczyk Citation2019, Citation2021; Kampczyk and Dybeł Citation2021). Despite the diversity of existing data models, their direct applicability in accurately representing and managing the complex interrelationships among railway entities remains insufficient. This is because of the dynamic nature of railway entities throughout their lifecycle, unlike entities with unified planning, such as natural resource entities (Y. Ding et al. Citation2022). Recently, researchers have proposed a conceptual model for the integrated representation of geospatial data, models, and knowledge of digital twin railway (H. Li, Zhu, et al. Citation2022). However, a conceptual model alone does not fulfill management needs and requires further development and implementation. Graphs offer a flexible data structure suitable for effectively modeling the dynamic spatiotemporal evolution of various entities and their interrelationships (Gross, Yellen, and Anderson Citation2018; Y. He et al. Citation2022).
Here, the primary focus was on the relationship between three distinct sets: data, models, and knowledge. We intentionally overlooked pre-existing internal relationships within each set. Given these characteristics, a tripartite graph model can be an apt framework for further association management (Pai et al. Citation2013). Another advantage is its divisibility into multiple bipartite graphs in distributed environments, which enhances both the parallel processing and overall performance.
(3) Indexing methods in distributed environments. Distributed spatiotemporal data indexing methods mainly cater to three domains: distributed computing systems, NoSQL-based databases, and independent distributed systems (Tian et al. Citation2022). For distributed computing systems, there has been a gradual assimilation of centralized indexing technology (Jitkajornwanich et al. Citation2020; Mahmood, Punni, and Aref Citation2019). These systems commonly employ global-local index structures, including 3D-R trees, Quad-Trees, and K-D trees. Applications such as HadoopTrajectory (Bakli, Sakr, and Soliman Citation2019) and GeoFlink (Shaikh et al. Citation2020) demonstrate the implementation of such structures. Linear indexing technologies like the Z-Curve and GeoHash are often adopted for NoSQL databases. This is evident in works such as HSTI (C. Zhang et al. Citation2018) and Redis-Geo (Makris et al. Citation2019), which utilize these technologies for specialized use cases. For independent distributed systems, the predominant indexing methods leverage structures such as consistent hashing, octrees, and R-trees. Several applications combine these structures to construct hybrid indexes (Feng et al. Citation2018; Memarzia et al. Citation2019). From another perspective, focusing on index structure, there has been a growing preference for hybrid index structures like multi-level indexes and multi-dimensional indexes, suggesting an emerging trend (Grandjean Citation2020; Madhavi and Supreethi Citation2023). Multi-level indexes are particularly suited to queries that prioritize temporal or spatial dimensions. In contrast, multi-dimensional indexes, capable of high throughput, are ideal for handling large-scale and intricate spatial-temporal queries with tight real-time constraints (Tian et al. Citation2022).
Nevertheless, most current indexing methodologies are anchored in specific data structures and database paradigms. These studies often overlooked the holistic incorporation of particular railway spatiotemporal metadata attributes, limiting their immediate applicability in the burgeoning field of digital twin railway (Sim et al. Citation2020). Considering the presence of specialized indexes tailored for railway database systems, the hybrid global-local indexing mechanism has emerged as a compelling strategy for efficiently managing multi-dimensional relationships while concurrently preserving the integrity of existing indexes (Feng et al. Citation2018; Zhu et al. Citation2017). Therefore, developing a global association graph index that can accommodate distributed data, models, and knowledge is imperative.
3. Methodology
3.1. Overview and problem setup
3.1.1. Overview of the approach
To solve the practical problems mentioned above caused by current management strategies, we define an association graph model for data, models, and knowledge based on tripartite graph theory, whereby explicit association relationships can be represented. In addition, we propose an association management architecture. The core of this architecture lies in generating and constructing an additional global association graph index while ensuring a tiny disruption to existing information systems. The overall workflow of the proposed method is illustrated in and includes two key parts: the association graph model and association management.
Figure 2. The overall workflow encapsulating the key steps involved in our proposed association management method for data, models, and knowledge in digital twin railway.
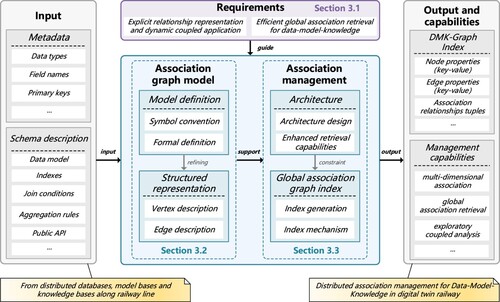
In particular, our method is guided by two crucial requirements that drive the problem setup, as described in Section 3.1.2. This method begins by obtaining retrievable metadata and schemas from distributed databases, model bases, and knowledge bases, which are inputs for all subsequent steps. Second, we propose an association graph model that provides a definition and structured representation, as elaborated in Section 3.2. The data, models, and knowledge are divided into 16 subcategories encompassing the comprehensive features of aboveground and belowground railway engineering environments. The association relationships are described from three perspectives: time, space, and interaction. Third, we design an association management architecture emphasizing enhancing the retrieval capabilities, which is delineated in Section 3.3. A global association graph index and a parallel dynamic generation algorithm are implemented in this architecture. Finally, our method outputs a global directed association graph index and facilitates efficient association management capabilities.
3.1.2. Problem setup
To formalize the description of this research, we introduce several mathematical symbol conventions that will be used consistently in subsequent sections. The inputs consist of three distinct independent sets: (Data Sets),
(Model Sets), and
(Knowledge Sets), where
represent the number of elements in each set, respectively. To elaborate on the characteristics and properties of each set, we introduce
,
, and
to represent the categorization types of data, models, and knowledge, respectively. Let
denote the association relationship between elements from set α and set β, where
and
. For each pair of elements
and
, we can represent the association relationship as a tuple
, where
is a subset of
, indicating the existence of one or more relationships between i and j. The purpose of this study is to establish an association graph model, denoted as
, which consists of a set of vertices
and a set of edges
, that can explicitly defines and represents the association relationships among data, models, and knowledge. Moreover, this study aims to design an association management architecture comprising a global association graph index(denoted as
), to efficiently support real-time coupling analysis applications in digital twin railway.
3.2. Association graph model
In this section, we first formally define an association graph model based on a tripartite graph. Next, we elaborate on the structured representation of vertex categorization types and their association relationships.
3.2.1. Model definition
Considering the asymmetry of the association relationships and the ensuing process of association retrieval, the DMK- is designed as a labeled directed property graph structure. A schematic and example of the DMK-
is presented in .
Figure 3. Schematic and an example of the DMK-.
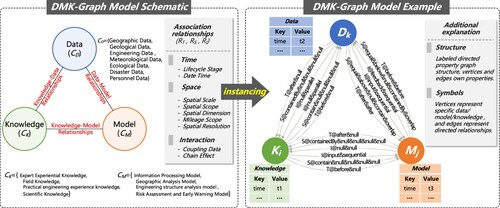
Formally, the DMK- can be defined as follows:
Definition of .
The DMK- is a directed property graph
, such that:
is the set of vertices, with each vertex
- - - - -
3.2.2. Vertex description
A standardized and unified vertex definition is crucial for guaranteeing compatibility across both entity-relationship calculations and algorithmic processing. To faithfully model both aboveground and underground railway entities, a vertex must encompass essential spatiotemporal and domain-specific attributes. We analyzed the existing railway information systems and identified the following categories: Data categories () comprise Geographic Data, Geological Data, Engineering Data, Meteorological Data, Ecological Data, Disaster Data, and Personnel Data; Model categories (
) include Information Processing Model, Geological Environment Analysis Model, Geographic Environment Analysis Model, Engineering Analysis Model, and Risk Analysis and Early Warning Model; Knowledge categories (
) comprise Expert Experiential Knowledge, Field Knowledge Graph, Engineering Practice Knowledge, and Scientific Research Achievement. presents a UML diagram illustrating the definitions for each category.
Figure 4. UML diagram describing the data structure of vertices in the DMK-.
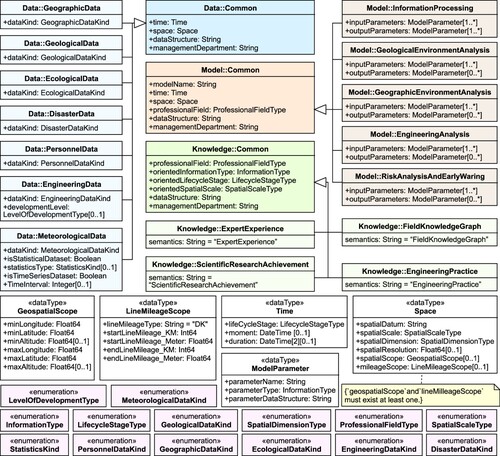
As depicted in this UML diagram, we first establish the necessary enumeration and data types that provide constraints for calculating association relationships before defining the vertices. Subsequently, we define 16 vertex data structures encompassing ,
, and
. These cover the essential parameters for calculating association relationships, such as information type, time, space, and data structure, and also accommodate replaceable and optional parameters (e.g. mileageScope and spatialScope can calculate the spatial scope relationship as long as one exists). In addition, extra parameters, such as management departments, are included to facilitate association management.
3.2.3. Edge description
The predefined association relationships serve a dual purpose: they enable the algorithmic procedures for the calculation of relationships between vertices and establish input conditions for subsequent relationship-based retrieval. This study builds upon general spatiotemporal relationships to introduce three types of association relationships applicable to digital twin railway. Calculating certain relationships sometimes proves challenging, owing to the incompleteness of the related attributes of Vertices and
. To address this situation, it is helpful to subdivide the association relationships into categories that can be interchangeably supported (for instance, Mileage Scope can be substituted with Spatial Scope, both of which can calculate the spatial scope relationship). Accordingly, the association relationships are categorized into: Time relationships (
), characterized by Lifecycle Stage and Date Time; Space relationships (
), characterized by Spatial Scale, Spatial Dimension, Spatial Resolution, Spatial Scope, and Mileage Scope; and Interaction relationships (
), characterized by Coupling and Chain Effect. The optional bidirectional input pairings and results of every association relationship calculation are listed in .
Table 1. Association relationships among data, models and knowledge.
As illustrated in the table, several general relationships are directly followed. These include the Date Time, Spatial Dimension, Spatial Resolution, and Spatial Scope. Furthermore, specific association relationships tailored to the digital twin railway are identified: (1) Lifecycle Stage, representing the relationships among the various phases in the railway engineering lifecycle; (2) Spatial Scale, expressing the relationship between different spatial scales ranging from small to large, comprising regional, engineering, and construction site scales; (3) Mileage Scope, a distinctive method for calculating the Scope relationships across railway line mileage attributes, where these attributes are typically denoted as distances in meters (e.g. DK1001m–DK1010m); (4) Coupling, uncovering the mutual feedback mechanisms and logical links between Vertices and
; (5) Chain Effect, emphasizing the transitive logical associations between Vertices
and
, thereby enhancing their interconnectedness.
3.3. Association management
The association management method in digital twin railway must be meticulously intertwined with the actual application requirements, distinctive characteristics, and current advanced technologies of data, models and knowledge. This necessitates a focus not only on the interactive feedback between physical space and information space, but also on the efficiency of dynamic coupling and association retrieval. In this section, we explicate the association management architecture, parallel index generation algorithm, and index mechanism.
3.3.1. Architecture
The architecture for association management fundamentally operates on cyclical interactions and iterative feedback processes between the physical and information spaces. As illustrated in , our architecture encompasses a complete information flow pipeline, which spans from: ‘Gathering in Physical Space Integration and Organization
Retrieval
Engineering Applications
Intelligent Services
Feedback to Physical Space’. Within the ‘Integration and Organization’ module, various railway departments, each having unique responsibilities and operating at different levels, produce, integrate, and organize a myriad of railway spatiotemporal data, mechanistic and analytical models, as well as professional experiential knowledge, all of which are obtained from the physical space. Next, the ‘Retrieval’ module provides retrieval capabilities by leveraging the cooperation of global and local indexes. The local index, chosen based on the data structure of the managed objects, is usually supported by SQL/NoSQL databases. It is mostly stored in external storage and loaded into the main memory when needed. However, the global index, tailored by users, addresses specific association retrieval tasks for data, models, and knowledge. It is primarily stored in the main memory and undergoes periodic batch-wise persistence to the disk. Lastly, the ‘Diverse Engineering Applications’ module houses various business applications, including integrated command and dispatch, comprehensive optimization design, and construction management. This module delivers intelligent services with description, prediction, diagnosis, and prognosis capabilities, thus empowering iterative optimization and feedback for entities within the physical space.
Figure 5. Design of association management architecture for digital twin railway information: an iterative feedback flow pipeline between physical space and information space.
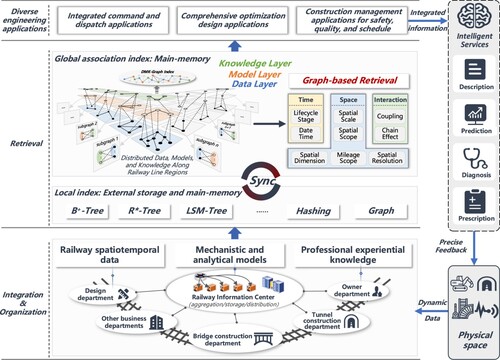
Considering the driving force behind the architecture and the real-time coupling analysis requirements, an essential work is to provide the effective global association retrieval capabilities of data, models, and knowledge in the ‘Retrieval’ module. In other words, this study focuses on designing and implementing a global association index within the boundary conditions set by the association graph model.
3.3.2. Global index generation
This study introduces a global association index anchored in the DMK-, which we call the
. Given the computationally intensive nature of generating this index, we devise a parallel algorithm tailored to leverage multicore CPU environments. The pseudocode for this algorithm is presented in , and a detailed description is provided below.
Algorithm 1: Parallel Index Generation for
The algorithm is rigorously designed upon the foundational principles of the previously defined DMK-. By accepting as its inputs the sets
,
, and
, the algorithm is meticulously tailored to harness the computational capacity of the available CPU cores, denoted by CPUs. The ultimate objective is to form a global association graph index represented by G. Initiated with an empty graph G, the algorithm's procedural flow is channeled into two cardinal phases: generation of vertices and establishment of edges. In the vertex generation phase, vertices are derived and extracted from the source datasets:
,
, and
. After extracting the essential attributes, these vertices are congregated into distinct sets and delineated as
and
. Transitioning to the edge establishment phase leverages the intrinsic tripartite graph structure for parallel processing. Each vertex set undergoes partitioning into subsets, matching the number of available CPUs. This strategic segmentation enhances the parallel processing capabilities of CPUs when addressing vertex set combinations
, and
. The function
is the linchpin for calculating the association relationships between vertices. Upon identifying a relationship, a pair of directed edges are placed in G.E: one traces from Vertex v to Vertex u, whereas the other gains its inverse utilizing the
function. Finally, a complete global association index is returned. Sample codes and datasets that demonstrate the given algorithm are available as online resources (refer to the Data and codes availability statement).
Theoretically, the time complexity of this global index generation algorithm is predominantly governed by owing to pairwise interactions among vertices. However, the incorporation of parallelism reduces this to
. This demonstrates that, with a fixed number of vertices n, increasing the number of CPUs can lead to marked efficiency improvements, making the algorithm especially potent for processing extensive data, models, and knowledge sets. The space complexity is capped at
, underscoring its scalability. By leveraging the inherent tripartite structure, the algorithm offers increased concurrency and maintains the relationship integrity among vertices, ensuring a substantial decrease in the index generation time.
3.3.3. Index mechanism
Here, we synchronize the global association index with local indexes. The global association index is designed to support the global association retrieval of temporal, spatial, and interactive relationships. This index encapsulates the association relationships between Vertices and
across disparate independent sets. Note that potential relationships between distinct vertices within the same set may also exist (e.g.
). If these relationships exist, they are seamlessly integrated into the
. In addition, the local index fundamentally enhances the efficiency of data retrieval and scheduling, particularly for certain I/O-intensive retrieval tasks. clearly illustrates the indexing mechanism between the global association index and the local index, detailing two key processes: search and update.
Figure 6. The mechanism of the global association index and local indexes in association management architecture is described through two key processes: search and update.
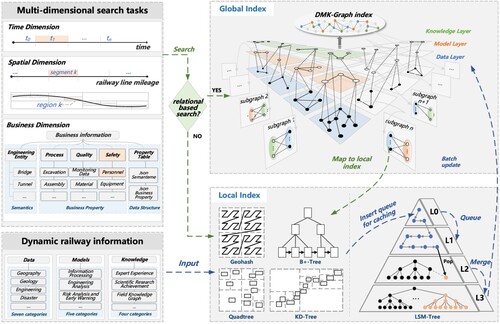
In the context of multi-dimensional search, the appropriate selection of indexing processes based on the specific search task is important. We explore two distinct search processes, differing mainly on whether they are relation-based or not. The first search process hinges on the association relationships among the data, models, and knowledge. Here, an initial query is dispatched to . The search operation then utilizes the preliminary results as query parameters to map the corresponding local index, facilitating a direct match and yielding results. The second search process addresses scenarios where a non-relation-based search is required, and the specific query parameters are already known. For instance, if the retrieval object is ‘Geographic Data’ with a spatial range of (29
N, 90
E) to (30
N, 91
E), and the data structure is ‘.tif’, the search operation can directly interface with the local index, bypassing
. This way efficiently omits unnecessary steps, thereby enhancing the search process.
During the dynamic update process, a diverse range of railway data, models, and knowledge with varying frequencies are inputted. The initial step involves updating the local index correlating to the updated objects such as Geohash, B+-Tree, Quadtree, or KD-Tree. Concurrently, the attributes associated with the global index are extracted and immediately updated in the LSM-Tree, fortified with a hash structure. Following extraction, the data are populated into a low-level cache queue, a core component of the LSM-Tree. When the volume of data in the queue reached a predefined threshold or after a specified time duration, the data are batched and transitioned to a higher level within the LSM-Tree. This configuration significantly enhances write throughput owing to the LSM-Tree's design, specifically tailored to handle write-intensive workloads. This hierarchical process continues until the updated object is incorporated into . Here, updates are executed in batches to optimize the speed of the overall update process.
4. Prototype system and experiments
The prototype system was developed to implement the presented theoretical method in Section 3, aiming to validate the effectiveness of the method in practical scenarios. To achieve this goal, it had been applied to a typical and real railway engineering problem fitting this study. Then, the case problem was described and experiments were conducted.
4.1. Prototype system design and implementation
To accommodate the diverse hardware performance environments pervasive among various railway departments, it was designed by leveraging a browser/server architecture, ensuring lightweight deployment and cross-departmental applications in a single integrated solution. illustrates the overall design of the prototype system. Relevant code and datasets demonstrating prototype system implementations, as well as experiments based on them, are accessible as online resources (refer to the Data and codes availability statement).
Figure 7. Prototype system design and implementation based on the browser/server architecture.
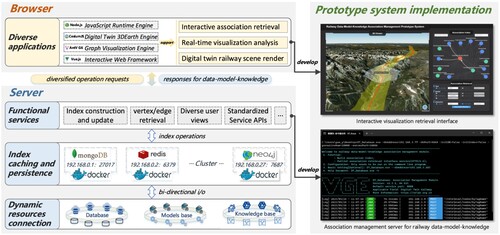
On the server side, the primary functions involve establishing connections with distributed resources and delivering functional services. The design is principally partitioned into three modules: (1) dynamic resource connection, which connects with distributed databases, model bases, and knowledge bases to facilitate information I/O operations. (2) Index Caching and Persistence: This module employs distributed database clusters to ensure regular, persistent backups of the cached indexes located in the main memory. (3) Functional Services: This module provides index generation, updates, and vertex/edge retrieval services. Moreover, it supports various types of responses to data, models, and knowledge. This study employed the Golang programming language, in-memory/external storage databases, and Docker technology to achieve the above design. These tools were utilized to develop a server program for railway data-model-knowledge association management. This program can run in the command-line interface environment of both Linux and Windows systems.
On the browser-side, an interface for interactive visualization and retrieval is provided. The interface is divided into three parts as follows: (1) 3D Viewer: This module is a virtual 3D earth engine capable of loading diverse railway spatiotemporal data, including but not limited to geographical and geological environment models and railway BIM. This integration of data is utilized to generate various workspace scenarios. Furthermore, the 3D viewer can perform visual spatial analyzes such as landslide hazard assessments. (2) Association Index: This module provides an interactive retrieval interface for the navigation of the . It bolsters progressive graph exploration based on association relationships and enables users to inspect vertex label properties and load vertex-associated spatiotemporal data into a 3D viewer module. (3) Association Retrieval: This module is a panel that allows users to set retrieval conditions or inspect vertex label properties. These applications are developed utilizing specialized engines and frameworks in collaboration with the server and are compatible with browsers that support WebGL.
4.2. Use case
Typically, the temperature distribution problem is a critical concern that poses significant risks throughout the entire lifecycle of railway engineering. High-temperature geothermal environments significantly influence the surveying stage, construction process, and the period of operation and management, markedly affecting both safety and quality. An effective risk mitigation strategy encompasses continuously monitoring sensor parameters, analyzing real-time temperature distributions within a multi-physics field, and providing feedback on control parameters to mechanical devices for optimizing the cooling strategy.
We chose an ongoing project of tunnel, a typical component of railway engineering, as the case problem. This analysis process, including seven vertices and their coupling relationships as defined in the DMK-, is concisely summarized in reference to the existing research (M. Lin et al. Citation2022) and depicted in . The input comprises metadata that aligns with the DMK-
's vertex data structure and the corresponding actual data, demonstrating the method's adaptability to distributed environments and highlighting its global association capabilities.
Figure 8. A brief steps summary of high-temperature safety risk analysis in railway tunnel engineering based on the study in this paper.
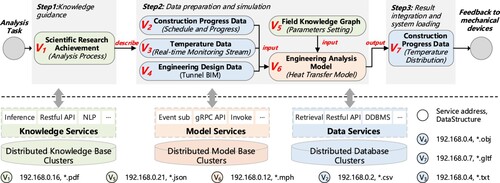
The analysis process is divided into three principal steps: (1) Knowledge guidance, where represents scientific research achievements in *.pdf format, determining the required data, models, and knowledge for the analysis process, along with their coupling relationships. (2) Data preparation and simulation, involving data retrieval essential for model input and a field knowledge graph to guide model parameterization, leading to the analysis model invocation. Supporting this step,
represents construction process data in *.csv format, crucial for ascertaining the tunnel's spatial positioning;
holds real-time temperature data in *.txt format;
contains the tunnel's 3D engineering design model in *.obj format, foundational for finite element model construction;
offers a field knowledge graph in *.json format for model parameter setting; and
represents an executable heat transfer model in *.mph format for temperature distribution analysis. (3) Result integration and system loading, where output
, in *.gltf format, represents temperature distribution results, integrated with geographic and geological digital twin models for enhanced visualization and analysis. Finally, the relevant parameter results are fed back into the mechanical devices within the physical space.
In our application scenario, we've encapsulated data, models, and knowledge into callable services within our system's ‘Functional Services’ module. Data and knowledge are accessed through HTTP-based RESTful APIs, while the heat transfer model () is deployed as a Remote Procedure Call (RPC) service. During the model execution,
integrates inputs from
,
,
, and
to run the simulation. This process starts with
setting numerical parameters, followed by
and
shaping the finite element model, and
providing real-time data, culminating in the generation of output
. The output is then integrated with digital twin models for enhanced visualization and further application.
4.3. Experiments
4.3.1. Task description
To validate our approach, we established distinct tasks for qualitative and quantitative experimentation:
(1) Qualitative tasks: Initiating a retrieval process from Vertex with the objective of locating Vertex
utilizing the
, to verify the effectiveness of the method. As a preparation, we input case-related information of seven vertices into the prototype system in advance. Their interrelationships, as well as the relationships with existing vertices, are then integrated into the
.
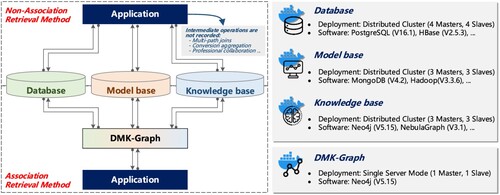
(2) Quantitative tasks: Recording the time for association and non-association retrieval processes across varying data volumes aims to statistically analyze our method's practicality. Given our method's unique association retrieval capabilities, absent in current information systems, these time metrics for non-association retrieval serve only as a baseline and are not meant for direct efficiency comparisons. The key difference resides in whether the global association index is utilized or not, as outlined in . The association retrieval process, leveraging the , involves an initial step of retrieval within the global index, followed by the database retrieval. The non-association retrieval is simulating the processes of decentralized and independent database application patterns, which is a two-step retrieval process across distributed databases, model bases, or knowledge bases, respectively.
Figure 9. Design of quantitative tasks and related software deployment environments.
4.3.2. Processes and results
Experiments were executed on a consumer-grade hardware featuring an AMD Ryzen 7 6800HS CPU (3.20 GHz, 8 cores, 16 logical processors), 32 GB RAM (4800 MHz), and an NVIDIA GeForce RTX 3070 Ti Laptop GPU.
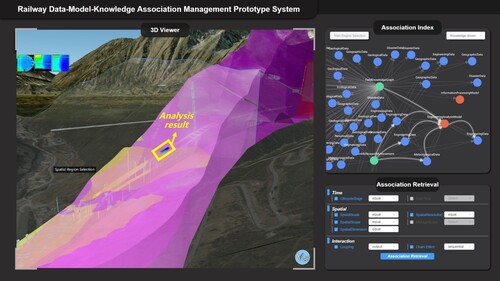
In the qualitative task, we utilized the prototype system's interactive visualization retrieval interface specifically for association retrieval. The process began in the ‘Association Index’ module, where a spatial work scope was selected and Vertex was found as the starting point. Subsequently, in the ‘Association Retrieval’ module, we performed a stepwise retrieval of the required data, models, and knowledge. This retrieval was based on temporal, spatial, and interactive relationships and utilized ‘and’ as the logical connector for conditions. The process culminated with the successful retrieval of the final result vertex, which was then loaded into the ‘3D Viewer’ module. The data represented by this result(Vertex
) was integrated with the geographic and geological digital twin environmental models. The final outcome, achieved through exploratory interaction within the prototype system, is depicted in . A video is provided to illustrate the step-by-step execution of the procedures (refer to the Data and codes availability statement).
Figure 10. An association retrieval result obtained by exploratory interaction retrieval in the prototype system.
In our quantitative tasks, we meticulously tracked the time consumption of two distinct retrieval processes. We selected three pairs of associated vertices within the use case: Data-Model (Vertices and
), Knowledge-Data (Vertices
and
), and Model-Knowledge (Vertices
and
). To observe trends in time consumption, we created five different sets of data volumes, incrementally increased by 200,000, ranging from 200,000 to 1,000,000 for each retrieval process. In the association retrieval process, our procedure entailed retrieving the designated initial vertex and its associated result vertex from the
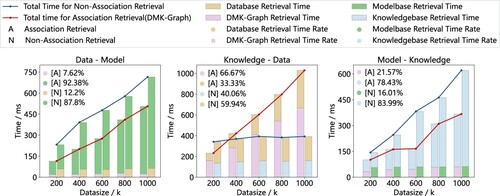
, acquiring the UUID, and then leveraging this UUID to access information from the appropriate information bases. For the current non-associated retrieval method, the procedure involved initially identifying the known initial information within the respective information bases. This was followed by formulating appropriate retrieval conditions for the result information base through processes like conversion and aggregation, and then retrieving information from the result bases. Subsequently, we set up the system to manage ten simultaneous single requests and calculated the average time required for 100 loop retrievals. The duration of this process, measured in milliseconds, was carefully analyzed, and the results are presented in .
Figure 11. Time consumption records and statistical analysis for association and non-association retrieval processes, emphasizing the method's practicality rather than direct efficiency comparisons.
4.4. Discussion
We conducted the following analysis and discussion on the experimental results, highlighting our findings and their implications for digital twin railway.
(1) Qualitative capability. The successful retrieval pathway from Vertex to Vertex
via the
demonstrates the method's capabilities in facilitating dynamic coupling capabilities and global accessibility between distributed data, models, and knowledge. It can intuitively be seen that the proposed method yields superior results, which are difficult to achieve across distributed and independent information systems. Moreover, the proposed method makes a crucial step forward in practical practice. The implementation of this method exhibits notable practical application, distinguishing it from the prevailing body of related research, which largely focuses on theoretical design aspects (H. Li, Zhu, et al. Citation2022; Y. Ding et al. Citation2022).
(2) Quantitative capability. The experimental results indicate that the tasks were completed within a reasonable and acceptable time consumption. Notably, the method enhanced the retrieval capabilities while maintaining the functionality of existing information systems, highlighting the method's practicality. Specifically, the lower overall time consumption observed within the ‘Data-Model’ and ‘Model-Knowledge’ segments can be attributed to the , which pre-calculates relationships. In other words, this approach trades storage overhead for enhanced time efficiency. However, the ‘Knowledge-Data’ segment exhibits a higher growth rate in overall time consumption. Upon further observation of the time allocation for each step within the retrieval processes, it can be inferred that the increased time consumption is attributable to the massive coupling relationships between vertex pairs (Knowledge-Data). This observation aligns with empirical facts. Such relationships lead to an expansion of the graph index scale, consequently necessitating increased time consumption. It is noteworthy that in practical railway engineering applications, the non-association retrieval process encompasses numerous time-consuming intermediate operations, specifically multi-path joins, conversion aggregation, and professional collaboration. These operations were omitted in our experiments.
(3) Limitations. Despite its effectiveness and practicality, our method has notable limitations. First, the proposed method assumes an idealized and standardized data state, which may overlook issues related to data acquisition, especially concerning legal and privacy aspects. Second, in , vertex attributes originate from various professional fields with semantic differences, necessitating a comprehensive review of data before input. Third, the capabilities of the global association graph index predominantly reside at the association retrieval level, more intelligent applications will require further development of application-driven methods. Lastly, the retrieval performance of the global association graph index is directly influenced by its scale. An increase in scale leads to more time consumption, thus indicating the need for advanced techniques to further improve the association management process.
5. Conclusion
This study introduced an innovative perspective of data-model-knowledge association management in digital twin railway, enabling more efficient support for dynamic coupling and global association retrieval services. First, our method proposed an extensible association graph model () as a foundation to explicitly define and represent the association relationships among the distributed data, models, and knowledge. Subsequently, we provided an association management architecture and a global association index (
) accompanied by a parallel dynamic generation algorithm. The advantages of this method over existing ones include its capabilities in association management, efficient global association retrieval, and intelligent services that dynamically couple data, models, and knowledge. Finally, we developed a prototype system and analyzed typical use case, yielding results that were in accordance with qualitative and quantitative experimental tasks.
In future work, we will further study the hybrid drive methodologies that coordinate data-driven, model-driven, and knowledge-driven approaches, aiming to further enhance the intelligent service capability of digital twin railway applications. Additionally, leading techniques such as reinforcement learning and probabilistic inference could be applied to strengthen the association retrieval process, ensuring that the method remains flexible and efficient even in demanding real-time railway environments under high load conditions. We believe that further exploration of this area would yield innovative software solutions, further improving the effectiveness of intelligent analysis applications in digital twin railway.
Data and codes availability statement
Supplemental online video, encapsulating the prototype system and the intermediate operation process of association retrieval, is accessible via the following link: https://youtu.be/Pv2CykRNGF0. The data and codes that support the findings of this study are available in figshare at the private link: https://figshare.com/s/49c77bf58a0e5a1dc242.
Acknowledgments
The authors wish to express their profound gratitude to both the editors and the anonymous reviewers.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Asfand-E-Yar, Muhammad, and Ramis Ali. 2020. “Semantic Integration of Heterogeneous Databases of Same Domain Using Ontology.” IEEE Access 8:77903–77919. https://doi.org/10.1109/ACCESS.2020.2988685.
- Bakli, Mohamed, Mahmoud Sakr, and Taysir Hassan A. Soliman. 2019. “Hadooptrajectory: A Hadoop Spatiotemporal Data Processing Extension.” Journal of Geographical Systems 21:211–235. https://doi.org/10.1007/s10109-019-00292-4.
- Bischof, Stefan, and Gottfried Schenner. October 24–28, 2021. “Rail Topology Ontology: A Rail Infrastructure Base Ontology.” In International Semantic Web Conference, Vol. 12922, 597–612. Springer. https://doi.org/10.1007/978-3-030-88361-4_35.
- Bloch, Tanya, and Rafael Sacks. 2020. “Clustering Information Types for Semantic Enrichment of Building Information Models to Support Automated Code Compliance Checking.” Journal of Computing in Civil Engineering 34 (6): 04020040. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000922.
- Broo, Didem Gürdür, Miguel Bravo-Haro, and Jennifer Schooling. 2022. “Design and Implementation of a Smart Infrastructure Digital Twin.” Automation in Construction 136:104171. https://doi.org/10.1016/j.autcon.2022.104171.
- Candel, Carlos J. Fernández, Diego Sevilla Ruiz, and Jesús J. Garíca-Molina. 2022. “A Unified Metamodel for Nosql and Relational Databases.” Information Systems 104:101898. https://doi.org/10.1016/j.is.2021.101898.
- Chen, Min, Alexey Voinov, Daniel P. Ames, Albert J. Kettner, Jonathan L. Goodall, Anthony J. Jakeman, Michael C. Barton. 2020. “Position Paper: Open Web-Distributed Integrated Geographic Modelling and Simulation to Enable Broader Participation and Applications.” Earth-Science Reviews 207:103223. https://doi.org/10.1016/j.earscirev.2020.103223.
- Deng, Shaojiang, Shuyuan Jia, and Jing Chen. 2019. “Exploring Spatial–Temporal Relations Via Deep Convolutional Neural Networks for Traffic Flow Prediction with Incomplete Data.” Applied Soft Computing 78:712–721. https://doi.org/10.1016/j.asoc.2018.09.040.
- Ding, Linfang, Guohui Xiao, Diego Calvanese, and Liqiu Meng. 2020. “A Framework Uniting Ontology-Based Geodata Integration and Geovisual Analytics.” ISPRS International Journal of Geo-Information 9 (8): 474. https://doi.org/10.3390/ijgi9080474.
- Ding, Yulin, Zhaowen Xu, Qing Zhu, Hankan Li, Yan Luo, Ying Bao, Lingjun Tang, and Sen Zeng. 2022. “Integrated Data-Model-Knowledge Representation for Natural Resource Entities.” International Journal of Digital Earth 15 (1): 653–678. https://doi.org/10.1080/17538947.2022.2047802.
- Doubell, Gerhardus Christiaan, Karel Kruger, Anton Herman Basson, and Pieter Conradie. 2021, March. “The Potential for Digital Twin Applications in Railway Infrastructure Management.” In World Congress on Engineering Asset Management, 241–249. Campo Grande, Brazil: Springer. https://doi.org/10.1007/978-3-030-96794-9_22.
- Feng, Bin, Qing Zhu, Mingwei Liu, Yun Li, Junxiao Zhang, Xiao Fu, Yan Zhou, et al. 2018. “An Efficient Graph-Based Spatio-Temporal Indexing Method for Task-Oriented Multi-Modal Scene Data Organization.” ISPRS International Journal of Geo-Information 7 (9): 371. https://doi.org/10.3390/ijgi7090371.
- Gao, Yan, Shuyue Qian, Zihan Li, Ping Wang, Feiyue Wang, and Qing He. July 15–August 15, 2021. “Digital Twin and its Application in Transportation Infrastructure.” In 2021 IEEE 1st International Conference on Digital Twins and Parallel Intelligence (DTPI), 298–301. Beijing, China: IEEE. https://doi.org/10.1109/DTPI52967.2021.9540108.
- Gao, Fan, Peng Yue, Zhipeng Cao, Shuaifeng Zhao, Boyi Shangguan, Liangcun Jiang, Lei Hu, Zhe Fang, and Zheheng Liang. 2022. “A Multi-Source Spatio-Temporal Data Cube for Large-Scale Geospatial Analysis.” International Journal of Geographical Information Science 36 (9): 1853–1884. https://doi.org/10.1080/13658816.2022.2087222.
- Grandjean, Martin. 2020, July. “A Conceptual Framework for the Analysis of Multilayer Networks in the Humanities.” In Digital Humanities 2020, Ottawa.
- Gross, Jonathan L, Jay Yellen, and Mark Anderson. 2018. Graph Theory and Its Applications. New York: Chapman and Hall/CRC. https://doi.org/10.1201/9780429425134.
- Harpham, Quillon K., Andrew Hughes, and R. V. Moore. 2019. “Introductory Overview: The Openmi 2.0 Standard for Integrating Numerical Models.” Environmental Modelling & Software 122:104549. https://doi.org/10.1016/j.envsoft.2019.104549.
- He, Zhanjun, Min Deng, Jiannan Cai, Zhong Xie, Qingfeng Guan, and Chao Yang. 2020. “Mining Spatiotemporal Association Patterns From Complex Geographic Phenomena.” International Journal of Geographical Information Science 34 (6): 1162–1187. https://doi.org/10.1080/13658816.2019.1566549.
- He, Yufeng, Yehua Sheng, Barbara Hofer, Yi Huang, and Jiarui Qin. 2022. “Processes and Events in the Centre: A Dynamic Data Model for Representing Spatial Change.” International Journal of Digital Earth 15 (1): 276–295. https://doi.org/10.1080/17538947.2021.2025275.
- Ji, Shaoxiong, Shirui Pan, Erik Cambria, Pekka Marttinen, and S. Yu Philip. 2021. “A Survey on Knowledge Graphs: Representation, Acquisition, and Applications.” IEEE Transactions on Neural Networks and Learning Systems 33 (2): 494–514. https://doi.org/10.1109/TNNLS.2021.3070843.
- Jitkajornwanich, Kulsawasd, Neelabh Pant, Mohammadhani Fouladgar, and Ramez Elmasri. 2020. “A Survey on Spatial, Temporal, and Spatio-Temporal Database Research and An Original Example of Relevant Applications Using Sql Ecosystem and Deep Learning.” Journal of Information and Telecommunication 4 (4): 524–559. https://doi.org/10.1080/24751839.2020.1774153.
- Jones, David, Chris Snider, Aydin Nassehi, Jason Yon, and Ben Hicks. 2020. “Characterising the Digital Twin: A Systematic Literature Review.” CIRP Journal of Manufacturing Science and Technology29:36–52. https://doi.org/10.1016/j.cirpj.2020.02.002.
- Kampczyk, Arkadiusz. April 28, 2021. “Railway Special Grid in Near Field Communication Technology for Rail Transport Infrastructure.” In Challenges of Urban Mobility, Transport Companies and Systems: 2018 TranSopot Conference, 87–99. Springer. https://doi.org/10.1007/978-3-030-50010-8_8.
- Kampczyk, Arkadiusz, and Katarzyna Dybeł. 2021. “Integrating Surveying Railway Special Grid Pins with Terrestrial Laser Scanning Targets for Monitoring Rail Transport Infrastructure.” Measurement170:108729. https://doi.org/10.1016/j.measurement.2020.108729.
- Kampczyk, Arkadiusz. May 19, 2019. “Irregularities in Level Crossings and Pedestrian Crossings.” In Challenges of Urban Mobility, Transport Companies and Systems: 2018 TranSopot Conference, 249–261. Taiwan: Springer. https://doi.org/10.1007/978-3-030-17743-0_21.
- Li, Wenwen, Michael Batty, and Michael F. Goodchild. 2020. “Real-Time GIS for Smart Cities” . https://doi.org/10.1080/13658816.2019.1673397.
- Li, Songnian, Suzana Dragicevic, Francesc Antón Castro, Monika Sester, Stephan Winter, Arzu Coltekin, Christopher Pettit. 2016. “Geospatial Big Data Handling Theory and Methods: A Review and Research Challenges.” ISPRS Journal of Photogrammetry and Remote Sensing 115:119–133. https://doi.org/10.1016/j.isprsjprs.2015.10.012.
- Li, Jianbin, Liujie Jing, Xiaofeng Zheng, Pengyu Li, and Chen Yang. 2019. “Application and Outlook of Information and Intelligence Technology for Safe and Efficient TBM Construction.” Tunnelling and Underground Space Technology 93:103097. https://doi.org/10.1016/j.tust.2019.103097.
- Li, Wenwen, Sizhe Wang, Sheng Wu, Zhining Gu, and Yuanyuan Tian. 2022. “Performance Benchmark on Semantic Web Repositories for Spatially Explicit Knowledge Graph Applications.” Computers, Environment and Urban Systems 98:101884. https://doi.org/10.1016/j.compenvurbsys.2022.101884.
- Li, Heng, Chunxiao Zhang, Ziwei Xiao, Min Chen, Dequan Lu, and Shuhui Liu. 2021. “A Web-Based Geo-Simulation Approach Integrating Knowledge Graph and Model-Services.” Environmental Modelling & Software 144:105160. https://doi.org/10.1016/j.envsoft.2021.105160.
- Li, Hankan, Qing Zhu, Liguo Zhang, Yulin Ding, Yongxin Guo, Haoyu Wu, Qiang Wang, et al. 2022. “Integrated Representation of Geospatial Data, Model, and Knowledge for Digital Twin Railway.” International Journal of Digital Earth 15 (1): 1657–1675. https://doi.org/10.1080/17538947.2022.2127949.
- Lin, Ming, Ping Zhou, Yifan Jiang, Feicong Zhou, Jiayong Lin, and Zhijie Wang. 2022. “Numerical Investigation on Comprehensive Control System of Cooling and Heat Insulation for High Geothermal Tunnel: A Case Study on the Highway Tunnel with the Highest Temperature in China.” International Journal of Thermal Sciences 173:107385. https://doi.org/10.1016/j.ijthermalsci.2021.107385.
- Lü, Guonian, Michael Batty, Josef Strobl, Hui Lin, A-Xing Zhu, and Min Chen. 2019. “Reflections and Speculations on the Progress in Geographic Information Systems (GIS): A Geographic Perspective.” International Journal of Geographical Information Science 33 (2): 346–367. https://doi.org/10.1080/13658816.2018.1533136.
- Lu, Jiaheng, and Irena Holubová. 2019. “Multi-Model Databases: A New Journey to Handle the Variety of Data.” ACM Computing Surveys (CSUR) 52 (3): 1–38. https://doi.org/10.1145/3323214.
- Lu, Chunfang, Junfei Liu, Yanhong Liu, and Yuming Liu. 2019. “Intelligent Construction Technology of Railway Engineering in China.” Frontiers of Engineering Management 6 (4): 503–516. https://doi.org/10.1007/s42524-019-0073-9.
- Ma, Zongmin, Luyi Bai, and Li Yan. 2020. “Spatiotemporal Data and Spatiotemporal Data Models.” In Modeling Fuzzy Spatiotemporal Data with XML, 1–18. Cham: Springer International Publishing. https://doi.org/10.1007/978-3-030-41999-8_1.
- Madhavi, Pappula, and K. P. Supreethi. July 21–22, 2023. “Multi-Dimensional Staqr Indexing Algorithm for Drone Applications.” In International Conference on Multi-disciplinary Trends in Artificial Intelligence, Vol. 14078, 611–619. Hyderabad, India. https://doi.org/10.1007/978-3-031-36402-0_57.
- Mahmood, Ahmed R., Sri Punni, and Walid G. Aref. 2019. “Spatio-Temporal Access Methods: A Survey (2010–2017).” GeoInformatica 23:1–36. https://doi.org/10.1007/s10707-018-0329-2.
- Makris, Antonios, Konstantinos Tserpes, Dimosthenis Anagnostopoulos, Mara Nikolaidou, and Jose Antônio Fernandes de Macedo. 2019, June. “Database System Comparison Based on Spatiotemporal Functionality.” In Proceedings of the 23rd International Database Applications & Engineering Symposium, 1–7. Athens Greece. https://doi.org/10.1145/3331076.3331101.
- McMahon, Paul, Tieling Zhang, and Richard Dwight. 2020. “Requirements for Big Data Adoption for Railway Asset Management.” IEEE Access 8:15543–15564. https://doi.org/10.1109/ACCESS.2020.2967436.
- Memarzia, Puya, Maria Patrou, Md Mahbub Alam, Suprio Ray, Virendra C. Bhavsar, and Kenneth B. Kent. June 10–13, 2019. “Toward Efficient Processing of Spatio-Temporal Workloads in a Distributed In-Memory System.” In 2019 20th IEEE International Conference on Mobile Data Management (MDM), 118–127. Hong Kong: IEEE. https://doi.org/10.1109/MDM.2019.00-66.
- Ning, Xinwen, Qing Zhu, Heng Zhang, Changjin Wang, Zujie Han, Junxiao Zhang, and Wen Zhao. 2020. “Dynamic Simulation Method of High-Speed Railway Engineering Construction Processes Based on Virtual Geographic Environment.” ISPRS International Journal of Geo-Information 9 (5): 292. https://doi.org/10.3390/ijgi9050292.
- Pai, Kung-Jui, Shyue-Ming Tang, Jou-Ming Chang, and Jinn-Shyong Yang. December 12–14, 2013. “Completely Independent Spanning Trees on Complete Graphs, Complete Bipartite Graphs and Complete Tripartite Graphs.” In Advances in Intelligent Systems and Applications-Volume 1: Proceedings of the International Computer Symposium ICS 2012 Held at Hualien, Vol. 20, 107–113. Taiwan: Springer. https://doi.org/10.1007/978-3-642-35452-6_13.
- Park, Seula, and Tao Cheng. 2023. “Framework for Constructing Multimodal Transport Networks and Routing Using a Graph Database: A Case Study in London.” Transactions in GIS 27 (5): 1391–1417. https://doi.org/10.1111/tgis.13071.
- Profillidis, Vassilios. 2016. Railway Management and Engineering. London: Routledge. https://doi.org/10.4324/9781315245362.
- Qiao, Xiaohui, Zhiyu Li, Fengyuan Zhang, Daniel P. Ames, Min Chen, E. James Nelson, and Rohit Khattar. 2021. “A Container-Based Approach for Sharing Environmental Models as Web Services.” International Journal of Digital Earth 14 (8): 1067–1086. https://doi.org/10.1080/17538947.2021.1925758.
- Ravat, Franck, Jiefu Song, Olivier Teste, and Cassia Trojahn. 2020. “Efficient Querying of Multidimensional Rdf Data with Aggregates: Comparing Nosql, RDF and Relational Data Stores.” International Journal of Information Management 54:102089. https://doi.org/10.1016/j.ijinfomgt.2020.102089.
- Sahal, Radhya, John G. Breslin, and Muhammad Intizar Ali. 2020. “Big Data and Stream Processing Platforms for Industry 4.0 Requirements Mapping for a Predictive Maintenance Use Case.” Journal of Manufacturing Systems 54:138–151. https://doi.org/10.1016/j.jmsy.2019.11.004.
- Sarkar, Debasis, Harsh Patel, and Bhargav Dave. 2022. “Development of Integrated Cloud-Based Internet of Things (IOT) Platform for Asset Management of Elevated Metro Rail Projects.” International Journal of Construction Management 22 (10): 1993–2002. https://doi.org/10.1080/15623599.2020.1762035.
- Semeraro, Concetta, Mario Lezoche, Hervé Panetto, and Michele Dassisti. 2021. “Digital Twin Paradigm: A Systematic Literature Review.” Computers in Industry 130:103469. https://doi.org/10.1016/j.compind.2021.103469.
- Shaikh, Salman Ahmed, Komal Mariam, Hiroyuki Kitagawa, and Kyoung-Sook Kim. October 19–23, 2020. “Geoflink: A Distributed and Scalable Framework for the Real-Time Processing of Spatial Streams.” In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 3149–3156, Ireland. https://doi.org/10.1145/3340531.3412761.
- Sim, Hyogi, Awais Khan, Sudharshan S. Vazhkudai, Seung-Hwan Lim, Ali R. Butt, and Youngjae Kim. 2020. “An Integrated Indexing and Search Service for Distributed File Systems.” IEEE Transactions on Parallel and Distributed Systems 31 (10): 2375–2391. https://doi.org/10.1109/TPDS.2020.2990656.
- Suleykin, Alexander, Peter Panfilov, and Natalya Bakhtadze. 2019, December. “Industrial Track: Architecting Railway KPIS Data Processing with Big Data Technologies.” In 2019 IEEE International Conference on Big Data (Big Data), 2047–2056. CA, USA: IEEE. https://doi.org/10.1109/BigData47090.2019.9006196.
- Tian, Ruijie, Huawei Zhai, Weishi Zhang, Fei Wang, and Yao Guan. 2022. “A Survey of Spatio-Temporal Big Data Indexing Methods in Distributed Environment.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 15:4132–4155. https://doi.org/10.1109/JSTARS.2022.3175657.
- Wu, Haoyu, Qing Zhu, Yongxin Guo, Weipeng Zheng, Liguo Zhang, Qiang Wang, Zhou, Runfang. 2022. “Multi-Level Voxel Representations for Digital Twin Models of Tunnel Geological Environment.” International Journal of Applied Earth Observation and Geoinformation 112:102887. https://doi.org/10.1016/j.jag.2022.102887.
- Yang, Chaowei, Keith Clarke, Shashi Shekhar, and C. Vincent Tao. 2020. “Big Spatiotemporal Data Analytics: A Research and Innovation Frontier.” https://doi.org/10.1080/13658816.2019.1698743.
- Zhang, Fengyuan, Min Chen, Albert J. Kettner, Daniel P. Ames, Quillon Harpham, Songshan Yue, Yongning Wen, and Guonian Lü. 2021. “Interoperability Engine Design for Model Sharing and Reuse Among Openmi, Bmi and Opengms-Is Model Standards.” Environmental Modelling & Software144:105164. https://doi.org/10.1016/j.envsoft.2021.105164.
- Zhang, Zhaohui, and Fei Li. 2020, April. “Research on the Construction of Big Data Management Platform of Shuohuang Railway Locomotive Operation and Maintenance.” In Proceedings of the 4th International Conference on Electrical and Information Technologies for Rail Transportation (EITRT) 2019: Rail Transportation System Safety and Maintenance Technologies, Vol. 639, 43–55. Singapore: Springer. https://doi.org/10.1007/978-981-15-2866-8_5.
- Zhang, Chengyuan, Lei Zhu, Jun Long, Shuangqiao Lin, Zhan Yang, and Wenti Huang. 2018, June. “A Hybrid Index Model for Efficient Spatio-Temporal Search in Hbase.” In Trends and Applications in Knowledge Discovery and Data Mining: PAKDD 2018 Workshops, BDASC, BDM, ML4Cyber, PAISI, DaMEMO, Melbourne, VIC, Australia, June 3, 2018, Revised Selected Papers 22, Vol. 11154, 108–120. Australia: Springer https://doi.org/10.1007/978-3-030-04503-6_9.
- Zhu, Yunqiang, A-Xing Zhu, Jia Song, Jie Yang, Min Feng, Kai Sun, Jingqu Zhang, Zhiwei Hou, and Hongwei Zhao. 2017. “Multidimensional and Quantitative Interlinking Approach for Linked Geospatial Data.” International Journal of Digital Earth 10 (9): 923–943. https://doi.org/10.1080/17538947.2016.1266041.