
ABSTRACT
The aim of the article is to present a model of decision-making processes in the design of flow-based Internet of Things systems. This is an attempt to fill the research gap in the construction of decision-making systems for designing both infrastructure and the application development environment. Therefore, the aim of the article is to show a decision-making model for selecting infrastructure and design environment for the development of IoT systems. In order for these processes to be implemented, it is necessary to use containerization processes and Flow Based Programming systems, both at the stage of system prototyping and its subsequent implementation.
The model verification was carried out on the example of design in accordance with the assumptions of the parallel design process model proposed in the article, using the infrastructure as code approach in infrastructure design, the Docker process for creating containers, publisher and subscriber design in Node Red, and Postgress database design.
1. Introduction
Flow Base Programing systems allow the application of the best programming practices through the possibility of visualizing the system architecture. The range of these technologies, as well as the process of selecting these technologies, is very diverse, as exemplified by NoFlo and Node-Red. For these technologies, it is possible to select libraries as well as use external projects using the flow-based programming paradigm. RECEIVE THE DATA → PROCESS THIS DATA → FORWARD THE DATA. This design process is of particular importance in the case of IoT (Internet of Things) systems, in which we connect objects and people. It is based on the concept of connecting M2M (Machine to Machine) devices for creating intelligent spaces (Mouha, Citation2021).
In the case of such systems, both the acquisition of data and the directions of their transmission require decision-making analyzes. Then the model of the decision-making process includes both the mqtt broker construction model and the selection of publishers and subscriber to this model. Therefore, a system based on geolocation, database, data processing system, mobile application and website was created. Additionally, Docker processes were used for the construction, which created conditions for creating a parallel environment (Orłowski & Kowalczuk, Citation2012; Pastuszak et al., Citation2012).
The article begins with an introduction to Flow-based Programming to explain data flow processes. Next, the environment for building Node-Red data flows was characterized. Then, the Docker environment will be characterized, as well as its Docker Compose and Docker Swarm processes. Next, a model of system design processes in a parallel development environment is presented. This model has been validated using container management processes for the implementation of database design processes as well as subscibers and publishers.
2. Flow base programing systems and docker processes in the design of IoT systems
Flow Base Programing (FBP) systems have developed very quickly over the years. The result of using these systems is a departure from designing embedded systems on a single computing resource and moving to the form of a complex system of hardware or software. Such a system consists of heterogeneously connected resources, processor cores and hardware accelerators. Therefore, data flow languages are used for application modelling, streaming, but also for modelling embedded systems (Kanagachidambaresan, Citation2021; Karmakar et al., Citation2019).
One of the first and one of the most popular FBP languages based on JavaScript programmable flows is NoFlo by The Grid. In this environment, the application being built consists of ‘black boxes’ linked together by input and output nodes. These nodes enable the flow of data. One flow can respond to changes in the file system, text messages, or incoming HTTP requests and simultaneously save data to the database. shows an example of data flow in the noFlo environment.
Figure 1. An example of using noFlo and CSS manipulation components to create an analog clock.
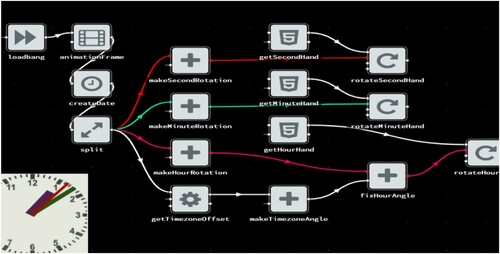
The flow in shows the nodes used to create the analog clock. Another FBP environment for system design is Reactive Patch Development (RPD). It's also a node-based environment. The programmer has the ability to create his own Node (Nirmala et al., Citation2022). shows an example of using the Reactive Patch for summing values.
Figure 2. Using Reactive Patch Development to create a flow that sums the values of A and B.
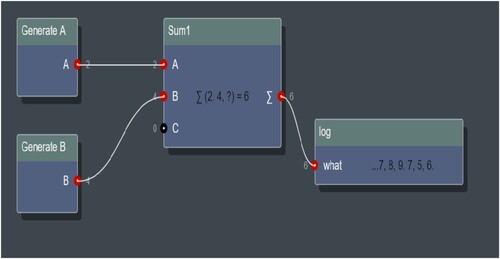
The nodes ‘Generate A’ and ‘Generate B’ are responsible for generating the numbers. Node A randomly generates a number between 1–3 and Node B randomly generates 4-6. These nodes were connected by the ‘Sum1’ node, which is responsible for adding up the two generated numbers. Finally node Sum1 has been connected to the ‘log’ node which displays the result of the addition.
Node-Red is an Open Source development environment developed by IBM. Commonly used to develop Internet of Things (IoT) applications. It has a rich database of nodes and libraries that contribute to connecting hardware devices, APIs and online services through the so-called DRAG AND DROP method. A flow is created based on the incoming, processing and outgoing nodes (Degreef et al., Citation2019). Thanks to the growing user base and the Node-Red community, new nodes are created that enable code reuse for IoT systems (Benila & Bhanu, Citation2022; Dogea et al., Citation2023).
The use of Flow-based Programming primarily contributes to improving the work of programmers in creating and modelling the structure of the application. It also allows you to create application logic, but also works well when working with distributed data (Diego et al., Citation2018). The key functionality of these systems is the ability to build the system architecture, which allows for a combination of the system design and implementation process. If we assume that the system we are designing is the result of team work, and the version control repositories do not meet the requirements, FBP systems are a reasonable alternative. These systems, however, require a lot of decision analyzes concerning both the data flow and the division of tasks between programmers (Chabik et al., Citation2007; Orłowski et al., Citation2016). Therefore, after the presentation of the FBP systems system, the docker processes were presented to create the basis for discussing the decision model in the design of IoT systems (International Conference on Knowledge-Based and Intelligent Information and Citation11, Citation2006; Javed, Citation2016).
Docker is a platform that makes it possible to separate the application from the infrastructure, thanks to which it is possible to install the software in containers (Sadri et al., Citation2022). A container is an isolated development environment. Containers are lightweight, and at the same time have everything that is needed to run the environment: code, runtime, system tools, system libraries and settings. Containers do not burden a physical machine as it is in the case of virtual machines (Alzahrani et al., Citation2022; Ribeiro Juniora & Kamienskia, Citation2021).
Summarizing, it can be said that Docker has become one of the fundamental system design processes in response to the growing number of microservices (Sharma & Jain, Citation2020). shows the operation of the Docker process used (Bhatter et al., Citation2021; Wysocki & Orłowski, Citation2011).
Figure 3. Diagram of the containerization and docker engine used on RaspberryPi.
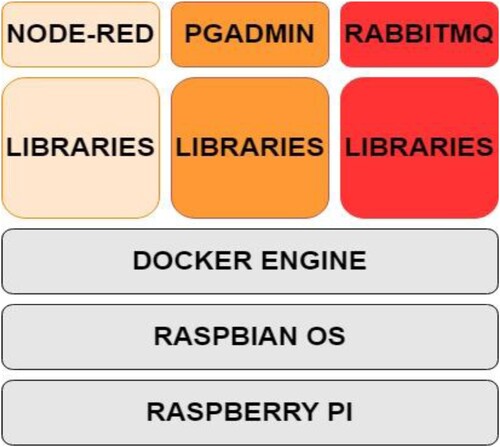
3. Model of IoT decision-making processes in a parallel software development environment
Model building began with the identification of the objects making up the model. These objects are infrastructure, containers, publisher, subscriber, FBP system and database. Then, decision-making processes for building a parallel design environment were identified. It was assumed that the decision-making processes are analyzed in a parallel design environment. This concept of a parallel design environment should be understood as an environment in which processes are created concurrently, including both infrastructure construction and software development. Decision-making processes occurred in four main phases of software development:
Implementation of the selected development process
Testing the operation of this process
Build a prototype
Providing a ready production environment
In a parallel design environment, partners share tasks that require specific production processes. These tasks have been divided into common as well as individual tasks. Each of the partners performs a set of common tasks and individual tasks for four production processes: infrastructure construction, container construction, installation and preparation of Node-Red applications for publisher and subscriber and installing and preparing the database for work.
The fourth figure shows how these processes were divided and how they were implemented during the project. Note that all processes are sequential, iterative in nature. shows sequential and iterative processes, noting that this model represents the first reference to design processes. Therefore, both the iterative nature of the processes and the need to apply feedback between the performance of individual tasks have been assumed.
Figure 4. Model of decision-making processes in a parallel development environment for IoT systems.
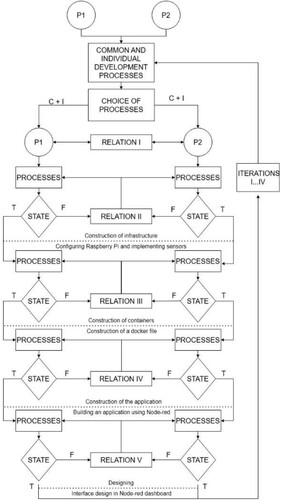
The technological relations between both partners during the implementation of individual project tasks were significant in the implementation of production processes in a parallel environment. Figure four shows these technological relationships at different stages of the design process. It should be noted that the decisions regarding these technological relations and the resulting conclusions are the most difficult to implement in the presented model.
The decision-making model presented in illustrates the application design processes in which, at individual stages called relationships, the following are defined:
Processes that form the basis for building applications. These processes are necessary to define the requirements for the application being built and to select the infrastructure and design environment.
The second report in analyzes the infrastructure selection process. Classic Edge Cloud infrastructures are considered, but also infrastructures based on IoT, in which the Fog intermediate layer is separated, which is the basis for data processing.
The third relation defines containers. Their number and size depend on the application being created. Containers are a kind of bridge connecting infrastructure requirements with application requirements. Hence, the way they are designed, the orchestrators used and their number depend on both the infrastructure and application requirements.
In the fourth relation, the application is constructed using the application development environment. Both fast application development environments, such as RAPID, are considered. Then programming languages such as Python or Java and languages such as Flow are considered. The selection of the manufacturing environment depends on the design processes set out in the first relationship.
In the fifth relation, we proceed to the design processes in which, depending on the selection of the design environment, the design process is implemented as in the case of programming languages and simplified, as in the case of Flow systems.
shows how important it is to select the infrastructure and application environments appropriately to the design requirements in the design process and then use the installed containers when designing the application development process.
Therefore, in the fourth figure only these relationships are shown, and it seems that in subsequent publications related to the IoT systems development process they will be precisely defined to increase the efficiency of the design process. precisely defines the sequential processes and stages of the manufacturing process, while these relationships have not been fully identified.
4. Model verification
The model was verified in Node-red, pgAdmin and postgresql databases using the Docker Compose process. Below are examples of two-layer verification of the fourth model shown in : Node-Red layers, publishers and subscriber construction, and the container construction layer.
In the Node-Red layer (), data was downloaded, data processed, and then sent to a database located on an external server. The data flow process was implemented in Node-Red and is outlined in .
Figure 5. System of the Flow type processing the data received from the API and storing it in the Postgresql database.
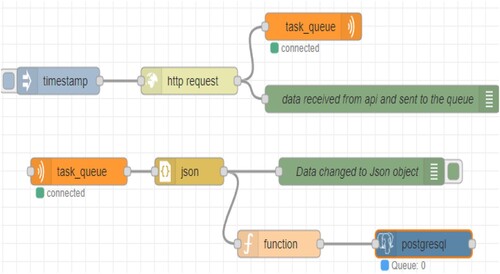
The data is made available via the provider's API timestamp node. Then they are sent to the RabbitMQ broker (task_queue). In this node, data is processed locally or in the cloud using queues. Due to the possibility of supporting many messaging protocols, this node can be configured according to the flow requirements. Additionally, the presented flow can be monitored thanks to the debug nodes. Subsequently, a ‘Subscriber’ was designed, which is responsible for receiving processed data using the JSON protocol. Then, using a postgresql node, a database was added to the flow implemented with Docker processes, which is Docker Swarm.
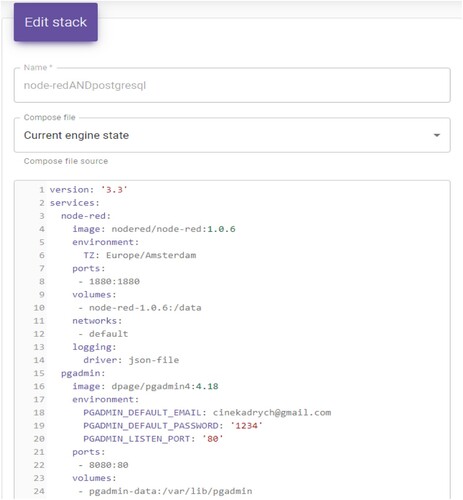
The docker_compose.yml file was used in the container construction layer, and its implementation was prepared by Stack in Docker Swarm to connect Node-Red to a database created locally on a physical machine. Working in a parallel environment was possible thanks to the use of dockerfile files. The structure of these files is shown in . It should be assumed that the decision-making process regarding the sequence of environment preparation, implementations in the container environment, and then managing these containers, required an assessment of the possibilities of cooperation of partners creating this environment. Additionally, it should be assumed that before preparing the next environments, the complexity of the dockerfile files should be taken into account. It includes the following processes that have important aspects of decision-making in the design environment:
| 1. | Construction of the Node-red container on the basis of the last image along with the identification of the ports on which the container is placed. | ||||
| 2. | Building a pgadmin container from an image. | ||||
| 3. | Building a postgress container based on an image. | ||||
Figure 6. Common dockerfile for partners of the parallel environment.
5. Conclusions
The aim of the article was to present a model of design processes in IoT in a parallel design environment. The model proposed in the article was a response to the complexity of IoT system design processes and the increasing number of recommendations, good practices and models for design processes.
The model developed by the authors was verified using a flow system developed in the Node-Red environment. Development processes in the Node-Red environment and the use of the Docker process show that the environment is so complex that it requires the use of design process models. Therefore, the article presents the system objects and the sequence and parallelism of the design processes.
This is an example of how an IT system can be developed in which each partner can act as a programmer and, on the other hand, be responsible for the delivery of the system. That is why it is so important to identify modelling processes that respond to the relationships between the designer and the supplier.
The construction of virtual machines, the docking process and containerization of virtual machines significantly improve the design process, but on the other hand, it requires the project partners to sequence and prioritize tasks. Therefore, the model presented in the article can be an example of how to design IoT systems and how to use flow-based systems. It can also be an example of standardization of the software development process and infrastructure construction, which can be used by any project team.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Cezary Orłowski
Cezary Orłowski is the director of the IBM Center for Advanced Studies on Campus at the WSB University in Gdańsk. He participated in many IT projects (including for banks, large IT companies and cities), managing digital transformation projects of organizations and being an advisor in the selection of technologies and Big Data processing processes. In IBM projects, he led the service integration processes for IBM Watson. Currently, together with his team, he is designing Internet of Things systems using artificial intelligence methods for Smart Cities.
Marcin Adrych
Marcin Adrych is an experienced IT specialist, specializing in computer networks and programming. He completed engineering studies in Programming and Master's studies in Computer Networks. His main area of interest is creating 'prototypes' in the Node-RED platform and preparing Docker and Docker Compose files. As an enthusiast of innovative solutions, Marcin focuses on rapid prototyping and testing of ideas, which enables effective implementation of applications in containers. Additionally, he likes to test his solutions in parallel using Raspberry Pi. In his free time, he attends IBM CAS laboratories, where he creates prototypes in Node-RED.
References
- Alzahrani, A. I. A., Al-Rasheed, A., Ksibi, A., Ayadi, M., Asiri, M. M., & Zakariah, M. (2022). Anomaly detection in fog computing architectures using custom tab transformer for internet of things. MDPI, s.2-s20.
- Benila, S., & Bhanu, N. U. (2022). Fog managed data model for IoT based healthcare systems. Journal of Internet Technology, s.1–s10.
- Bhatter, S., Sinha, S., & Sharma, R. (2021). Design of chatbots using node-RED. In R. Sharma, M. Mishra, J. Nayak, B. Naik, & D. Pelusi (Eds.), Green technology for smart city and society. lecture notes in networks and systems, Vol 151. Springer. https://doi.org/10.1007/978-981-15-8218-9_7.
- Chabik, J., Orłowski, C., & Sitek, T. (2007). Intelligent knowledge-based model for IT support organization evolution. Smart Information and Knowledge Management, 177–196.
- Degreef, P., Van Merode, D., & Tabunshchyk, G. (2019). Low-cost, open-source automation system for education, with Node-RED and raspberry Pi. In M. Auer, & R. Langmann (Eds.), Smart Industry & Smart Education. REV 2018. Lecture Notes in Networks and Systems, vol 47. Springer. https://doi.org/10.1007/978-3-319-95678-7_51.
- Diego, C., Maurizio, L., Gianna, R., & Filippo, R. (2018). Towards an approach for developing and testing Node-RED IoT systems. Research Gate, s.1–s.9.
- Dogea, R., Yan, X. T., & Millar, R. (2023). Implementation of an edge-fog-cloud computing IoT architecture in aircraft components. Springer, s.416–s.424.
- International Conference on Knowledge-Based and Intelligent Information and 11. (2006).
- Javed, A. (2016). Complex flows: Node-Red. In Building arduino projects for the internet of things. Apress. https://doi.org/10.1007/978-1-4842-1940-9_4.
- Kanagachidambaresan, G. R. (2021). Node-Red programming and page GUI builder for industry 4.0 dashboard design. In Role of Single Board Computers (SBCs) in rapid IoT Prototyping. Internet of Things (Technology, Communications and Computing). Springer. https://doi.org/10.1007/978-3-030-72957-8_6.
- Karmakar, A., Dey, N., Baral, T., Chowdhury, M., & Rehan, M. (2019). Industrial internet of things: A review. ResearchGate, s.77–s.98.
- Mouha, R. A. (2021). Internet of Things (IoT). Research Gate, s.77–s.98.
- Nirmala, M., Saravanan, V., Jayasudha, A. R., John, P. M., Privietha, P., & Mahalakshmi, L. (2022). Clinical implication of machine learning based cardiovascular disease prediction using IBM Auto AI service. International Journal for Research in Applied Science and Engineering Technology, s.124–s.143. https://doi.org/10.22214/ijraset.2022.46087
- Orłowski, C., & Kowalczuk, Z. (2012). Knowledge management based on dynamic and self-adjusting fuzzy models.
- Orłowski, C., Ziółkowski, A., Orłowski, A., Kapłański, P., & Sitek, T. (2016). High-level model for the design of KPIs for smart cities systems. Transactions on Computational Collective Intelligence, XXV, 1–14.
- Pastuszak, J., Czarnecki, A., & Orłowski, C. (2012). Ontologically aided rule model for the implementation of ITIL processes. Advances in Knowledge-Based and Intelligent Information and Engineering, 11.
- Ribeiro Juniora, F. M., & Kamienskia, C. A. (2021). Data resilience system for fog computing. Science Direct, s.2–s13.
- Sadri, A. A., Rahmani, A. M., Saberikamarposhti, M., & Hosseinzadeh, M. (2022). Data reduction in fog computing and internet of things: A systematic literature survey. Science Direct, s.1–s.5.
- Sharma, S., & Jain, R. (2020). Pronika, data deduplication for efficient storage on cloud using fog computing paradigm. International Journal of Recent Technology and Engineering, s.812–s.815.
- Wysocki, W., & Orłowski, C. (2011). A multi-agent model for planning hybrid software processes. Procedia Computer Science, 159, 1688–1697. https://doi.org/10.1016/j.procs.2019.09.339