
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
This paper proposes a penalized method for high-dimensional variable selection and subgroup identification in the Tobit model. Based on Olsen's [(1978). Note on the uniqueness of the maximum likelihood estimator for the Tobit model. Econometrica: Journal of the Econometric Society, 46(5), 1211–1215. https://doi.org/10.2307/1911445] convex reparameterization of the Tobit negative log-likelihood, we develop an efficient algorithm for minimizing the objective function by combining the alternating direction method of multipliers (ADMM) and generalised coordinate descent (GCD). We also establish the oracle properties of our proposed estimator under some mild regularity conditions. Furthermore, extensive simulations and an empirical data study are conducted to demonstrate the performance of the proposed approach.
1. Introduction
Subgroup analysis has broad applicability in precision medicine, economics and sociology as there is an increasing need to distinguish homogeneous subgroups of individuals, detect the subgroup structure and model the relationships between the response variable and predictors for individuals belonging to different subgroups. Thus, vast statistical methods for subgroup analysis have been developed, such as mixture models (Everitt, Citation2013) and regularization methods (Ma & Huang, Citation2017). Mixture model methods assume that the data come from a mixture of subgroups and require the specification of an underlying distribution. Shen and He (Citation2015) proposed a structured logistic-normal mixture model to identify subgroups. However, they often require the number of subgroups to be specified to group the parameterized models, which can often be difficult to implement in practice. In contrast, Ma and Huang (Citation2017) developed a pairwise fusion approach using concave penalty functions, such as the smoothly clipped absolute deviation (SCAD, J. Fan & Li, Citation2001) penalty and the minimax concave penalty (MCP, Zhang, Citation2010), that automatically identifies subgroup structures and estimates subgroup-specific effects. Ma et al. (Citation2019) considered a heterogeneous treatment effects model. Wang et al. (Citation2019) proposed a general framework of spatial subgroup analysis method for spatial data with repeated measures.
In numerous regression problems, the dependent variables can only be observed within a restricted range. For instance, when studying the influencing factors of different family expenditures in a group, some families may spend zero on items like medical insurance. Similarly, when studying individual or collective income, negative income generated by debt cannot be included in the income calculation. These scenarios involve left-censored data, which exist commonly in economics. Therefore, it encourages us to develop models specially tailored to address such situations. Tobin (Citation1958) developed the Tobit model to study the relationship between the annual expenditure of durable goods and household income. Due to the large number of scenarios of left-censored data in economics and social sciences, the Tobit model remained popular and it has been thoroughly studied and extended to deal with other types of censored data (Amemiya, Citation1984). Regarding subgroup analysis with censored data, Dagne (Citation2016) proposed a method that simultaneously addresses left-censoring and unobserved heterogeneity within longitudinal data. Additionally, Yan et al. (Citation2021) developed a censored linear regression model with heterogeneous treatment effects.
The advent of advanced data collection techniques has led to an increase in the prevalence of high-dimensional data in the aforementioned fields. When dealing with high-dimensional problems, J. Fan and Lv (Citation2010) provided a comprehensive overview of variable selection approaches, which incorporate methods discussed by J. Fan and Li (Citation2001). In the context of high-dimensional censored models, Müller and van de Geer (Citation2016) and Zhou and Liu (Citation2016) respectively introduced lasso penalty and adaptive lasso penalty to the least absolute deviation (LAD) estimator (Powell, Citation1984) for variable selection in high-dimensional censored models. Johnson (Citation2009) and Soret et al. (Citation2018) proposed lasso penalties for Buckley-James estimators in right and left censored data. Moreover, Bradic et al. (Citation2011) provided a non-concave penalized approach in Cox proportional hazards model with non-polynomial-dimensionality. Alhamzawi (Citation2016) and Alhamzawi (Citation2020) developed the Bayesian method of penalty censored regression. Recently, Jacobson and Zou (Citation2023) extended the Tobit model to high-dimensional regression. However, none of these methods focus on subgroup analysis in high-dimensional censored data.
This paper focuses on subgroup identification and variable selection for a high-dimensional Tobit model. To the best of our knowledge, there have been no discussions on subgroup analysis for high-dimensional Tobit models in the existing literature. We adopt a penalized approach to identify the subgroup structures and select covariates simultaneously. The subgroup structure is determined by penalizing pairwise differences between subject-specific effects while significant covariates are chosen based on a penalty on coefficients. To ensure the sparsity and unbiasedness of the proposed estimators, we consider two commonly used concave penalties, SCAD (J. Fan & Li, Citation2001) and MCP (Zhang, Citation2010). Due to the non-convex of the negative log-likelihood in the Tobit model (Tobin, Citation1958), optimization becomes challenging for high-dimensional settings. To address this issue, we employ a convex reparameterization of negative log-likelihood, building upon the idea proposed by Olsen (Citation1978). This reparameterization enables us to solve the problem using convex optimization approaches. The computational algorithm we proposed combines the alternating direction method of multipliers (ADMM) algorithm (Boyd et al., Citation2011) and generalized coordinate descent (GCD) algorithm (Jacobson & Zou, Citation2023; Yang & Zou, Citation2013) using two concave penalties, such as SCAD or MCP. Furthermore, we conduct a theoretical analysis of the proposed estimators and establish their oracle properties under mild conditions.
The remainder of this paper is organized as follows. Section 2 introduces the main problem and outlines the proposed method. In Section 3, we propose an algorithm for identifying the subgroup structures and performing variable selection. We state technical assumptions and establish the theoretical properties of our proposed approach in Section 4. Section 5 provides extensive simulation studies to illustrate the empirical performance of the proposed method, while Section 6 presents its application to empirical data. A summary and prospects for future research are presented in Section 7 and all technical proofs are given in Appendix.
2. Model and method
2.1. Model setting
Suppose that is a p-dimensional vector of covariates for the ith subject.
is the response for a restricted range, where c is a known constant. Without loss of generality, we assume that c = 0 in the following. The Tobit model assumes that the observed data y satisfies
, where
is a latent variable. Under the homogeneous case, the classical linear model takes the form
(1)
(1) where μ is the unknown intercept,
is the vector of coefficients for the covariates
, and
are assumed to be independent and identically distributed with normal distribution
.
If individuals are from different groups with a unique intercept , the homogeneity assumption in the model (Equation1
(1)
(1) ) is invalid. To model the subject-specific effects, we consider the subject-specific linear model
(2)
(2) We assume
arise from
different groups with
unknown and the subjects from the same groups have the same intercept. In other words, we have
for all
, where
is the common value of intercept
in subgroup
and
is a mutually partition of
. In practice, the number of subgroups K is unknown and is smaller than the sample size n.
Define , where
is an indicator function. Then the observed data
satisfy the following Tobit model
(3)
(3) with subgroup structure
(4)
(4) Let
denote the standard normal cumulative distribution function (CDF). Then
and the Tobit likelihood is given by
where
. Therefore, after omitting an inconsequential constant, the log-likelihood function of the Tobit model is
It is apparent that the function
is non-concave with respect to the parameters
. By adopting the reparameterization suggested in the works of Olsen (Citation1978) and Jacobson and Zou (Citation2023) with
,
and
, we achieve a transformation that leads to a concave function with respect to parameters
,
where
.
2.2. Method
There are usually some redundant covariates in high-dimensional scenarios, and regularization is the most commonly used method to identify the sparsity of regression coefficient vectors (Bondell & Reich, Citation2008; J. Fan & Lv, Citation2010; Y. Fan & Tang, Citation2013). The subgroup structure (Equation4(4)
(4) ) can be transformed as the fusion sparse structure,
. In order to estimate the parameters
, and γ, and to select proper covariates through the sparsity assumption of
, we propose a new method that combines ideas of penalized Tobit regression (Jacobson & Zou, Citation2023) and the subgroup analysis by concave pairwise fusion penalization (Ma & Huang, Citation2017; Ma et al., Citation2019), which can be expressed as minimizing the following loss function
(5)
(5) where
and
are penalty functions,
are tuning parameters that control the strengths of regularization of
and
, respectively. Note that the sparsity of
is achieved through the first penalty term, while the homogeneity detection is achieved by the second penalty term. Additionally, when
the problem reduces to the subgroup analysis in censored regression; when
the problem reduces to the penalized Tobit regression.
It is important to note that lasso estimators may fail to achieve consistent model selection unless a stringent ‘irrepresentable condition’ (Zhao & Yu, Citation2006; Zou, Citation2006). Particularly, the penalty tends to overshrink non-zero difference of
, which can result in an inflated number of subgroups. To address this limitation, we consider two common concave penalty functions for the purposes of identifying the subgroup structure and selecting variables, namely the smoothly clipped absolute deviation (SCAD, J. Fan & Li, Citation2001) and the minimax concave penalty (MCP, Zhang, Citation2010). These penalties provide alternative approaches to handle the challenges associated with variable selection and subgroup detection.
The SCAD is defined as follows
and the MCP is
where a is a parameter that controls the concavity of the penalty function.
3. Computational algorithm
In this section, we propose an algorithm utilizing the alternating direction method of multipliers (ADMM) (Boyd et al., Citation2011) in conjunction with generalized coordinate descent (GCD) (Jacobson & Zou, Citation2023; Yang & Zou, Citation2013) to address the minimization problem (Equation5(5)
(5) ). Since the penalty function is not separable with respect to
, it is challenging to directly minimize the objective function (Equation5
(5)
(5) ). We introduce a new set of parameters
, and then the minimizing problem can be written as the following constraint optimization problem
where
is the negative log-likelihood function which we call it Tobit loss for short and
. Applying the augmented Lagrangian method, the estimates of the parameters can be obtained by minimizing
(6)
(6) where
are Lagrange multipliers, and ρ is the penalty parameter.
To obtain the minimum in (Equation6(6)
(6) ), we propose to use the following iterative algorithm based on the ADMM. Let t denote the iteration step. We update the estimates of
,
, and
iteratively at the
th iteration step as follows
(7)
(7)
(8)
(8)
(9)
(9) where
.
It is worth noting that, given , the objective function in the first minimization problem (Equation7
(7)
(7) ) can be simplified as
(10)
(10) where
, and C is a constant independent with
.
Due to the complexity of the function (Equation10(10)
(10) ) with respect to
, we apply the generalized coordinate descent (GCD) method to solve the problem. By employing the GCD method, we can iteratively update each variable while holding the others fixed.
Let and
be the current values for
and γ, respectively. For the sake of simplicity in notation, let
denote the vector
with the jth element removed in the subsequent context. In order to get the estimate of
, we begin by expressing the Tobit loss
with respect to
We observe that after dropping the negligible constants, the Tobit loss
associated with
solely depends on the data collected from subject i. In line with Theorem 1 presented in Jacobson and Zou (Citation2023), the quadratic majorization function for
takes the following form:
where
represents the derivative of function with respect to
. Following the MM principle, the update of
can be obtained by minimizing the expression
, and
is an
vector with the jth element being 1 and the remaining elements being 0. Therefore, for fixed
, and
at the kth step, the update of
is as follows
(11)
(11) where I is the identity matrix, and
with
.
Now we consider coordinate-wise updates of . Let
. Similarly to
, we also have the quadratic majorization function of
with respect to
with form
where
is the derivative of
with respect to
. Here, the Tobit loss with respect to
can be expressed as
We can update
by minimizing
through MM principle. For
, let
. Hence, for SCAD penalty with
, the update of
at the
th step is
(12)
(12) where
is the soft-thresholding rule, and
. And when
for the MCP penalty, the updated value is
(13)
(13) Lastly, for given
and
, we minimize
to update γ,
(14)
(14) Once the convergence is achieved, we denote the final iteration of the GCD as
.
As for the second minimization function (Equation8(8)
(8) ), by eliminating insignificant constants that have no effect on the minimization process, the optimization function simplifies to the following form
(15)
(15) with respect to
, where
. It's worth noting that (Equation15
(15)
(15) ) is convex with respect to each
when
for MCP or
for SCAD. Hence, the closed-form solution for the MCP penalty at the
iteration is
(16)
(16) Then for the SCAD penalty, it is
(17)
(17) We provide the complete algorithm in Algorithm (1), referred to as the ADMM-GCD algorithm for convenience.

Remark
In the algorithm, there are two iterative steps. In the nested GCD iteration, the iterative convergence criterion is defined as follows
On the other hand, for ADMM, we employ the following criterion
It is worth mentioning that in our simulation studies, we set
and
, respectively.
The following Proposition 3.1 presents the convergence properties of the proposed algorithm.
Proposition 3.1
Given and
for MCP or
and
for SCAD, any accumulation point
generated by Algorithm 1 is a coordinate-wise minimum of
. In addition, the primal residual
and the dual residual
of the ADMM satisfy that
and
for both MCP and SCAD penalties.
4. Theoretical properties
In this section, we study the theoretical properties of the proposed estimators. We first introduce , a subspace of
, defined as
For each
, it can be also written as
, where
is the
indicator matrix defined by
for
and
otherwise, and
is a
vector of parameters. Let
denotes the number of elements in
, we have
by matrix calculation. Define
and
.
First, we assume that the true values of the parameters for ,
and γ are
,
and
, respectively. Let
, where
is the underlying common intercept for group
. We let
denote the true support set of
and define
,
and
. Under the sparsity assumption,
.
To consider the true variables, we set and define
, where
are the true variables with
and
are the zero variables. Then we define a subspace of
as
Additionally, we let
and
for notational convenience.
Since there are obvious differences between censored and uncensored observations in the Tobit likelihood, we use a more convenient expression to differentiate them clearly. When we define as the number of observations for which
and
, we can re-block our observations as
where
is the
matrix of predictors corresponding to the observations for which
while
is the
matrix of predictors corresponding to the observations for which
. Similarly,
and
denote the responses greater than and not greater than 0, respectively. Then by the definition above we get the same form
4.1. Technical conditions
In this subsection, we will introduce several mild conditions and discuss their relevance in detail.
| (C1): | Assume | ||||
| (C2): | The penalty function | ||||
| (C3): | The error vectors | ||||
When the true group memberships and true support set
are known, the oracle estimators for
,
and γ are defined as
After removing the redundant variables, we can write
and
for ease of calculation. Then, the oracle estimators for
,
and γ are given by
(18)
(18) The problem (Equation18
(18)
(18) ) can be reduced to the traditional Tobit model. To obtain the estimator using the maximum likelihood method, it is necessary to calculate the matrix of second partials. We define
and
. The matrix can be expressed as follows
(19)
(19) where
is a
diagonal matrix with
.
Olsen (Citation1978) found that the matrix in (Equation19(19)
(19) ) is negative semidefinite. Theorem 1 in Amemiya (Citation1973) established the asymptotic result that this matrix becomes non-zero with probability one. This ensures the invertibility of the above gradient matrix. Moreover, we introduce an additional condition to support Theorem 4.2.
| (C4): | The tuning parameter | ||||
4.2. Theoretical results
Theorem 4.1
Suppose that where
and define
for
. Let
denote the oracle solution to the Tobit model when the true group memberships and true support set of
are known. Suppose conditions (C1)–(C3) hold, and then
corresponds to the unique maximum of the likelihood function and is a consistent estimator of the true parameter values
such that
(20)
(20) where
. Moreover, we denote
as the maximum eigenvalue of the matrix
. If
is satisfied, we have that with probability at least
,
(21)
(21) where
and C is a constant.
For , let
be the minimal difference of the common values between the two groups.
Theorem 4.2
Suppose the conditions in Theorem 4.1 hold and . If the minimum signal strength of
satisfies
and
. When
, where a is a given constant in (C2), then there exists a local minimum
of the objective function
given in (Equation5
(5)
(5) ) satisfying
that is,
The proofs of these theorems are given in the Appendix.
5. Simulation studies
In this section, we conduct extensive simulation studies to investigate the numerical performance of the proposed approaches. We generate data from the censored heterogeneous linear model:
where
are generated from independent normal distribution
and the error terms
are from independent normal distribution
. We set
with censoring rate q. The true coefficients are set as
, which is a p-dimensional vector with p−5 zero elements. To investigate the effect of the magnitude of difference between subgroup-specific effects, we consider two cases for the subgroup structure:
| Case 1: |
| ||||
| Case 2: |
| ||||
We evaluate the performance of the estimators obtained using the proposed method using three different penalties (SCAD, MCP and Lasso), and compare them to the penalized Tobit approach (Tobit SCAD, Jacobson & Zou, Citation2023), which assumes a homogeneous intercept effect μ. Additionally, we present the results of Oracle estimators (Tobit Oracle) as well. For each simulation, we generate 100 datasets with sample size of n = 100, for every combination of and p = 10, 50, 200. Specifically, we set
and set
for the SCAD penalty and
for the MCP penalty. Subsequently, we conduct the simulations by selecting the optimal tuning parameters via minimizing the modified BIC (Wang et al., Citation2007):
(22)
(22) Wang et al. (Citation2009) used
in the simulation to apply the divergence of the predictor with sample size in high-dimensional scenarios. In this article, we let
, where d = n + p + 1 and c is a positive constant that we set to 1.5.
We evaluate the methods based on three aspects, accuracy of the coefficient estimates, performance of the variable selection and identifying the subgroup structures. To measure the estimation accuracy of parameters , we use the square error of the mean squared errors. Let
and
represent the true parameters. The square roots of the mean squared errors for
and
are defined by
,
and
, respectively.
In order to assess the variable selection of these methods, we report the number of true variables not included (NT) and the number of error variables included (NE). Moreover, to evaluate the performance of the subgroup analysis, we present the estimate of the number of groups (), the rate of false estimation of the number of groups (FK%) and the Rand Index (RI, Rand, Citation1971), which is defined by
where true positive (TP) indicates that two observations from the same truth group are allocated to the same group, true negative (TN) means two observations from different groups are allocated to different groups, false positive (FP) denotes two observations from different groups but allocated to the same group, and false negative (FN) represents two observations from the same group are allocated to different groups. A high Rand Index indicates a substantial proportion which of individuals being assigned to the correct subgroups.
Tables and present the average square root of the mean squared error (RSME) of the estimates of the five methods. The cases considered in the tables involve varying values of p and censoring rates. It is evident from the tables that the proposed methods, namely MCP and SCAD, consistently yield smaller RMSE values compared to the Lasso and Tobit SCAD methods across all simulations. Moreover, the method utilizing the lasso penalty consistently underestimates the number of groups. Consequently, the substantial deviation of the estimator can be attributed to the loss of heterogeneous intercept information. Similarly, the Tobit SCAD method when utilized without the subgroup recognition function, shows comparable results.
Table 1. The sample means and standard deviations of the index to be measured when K = 2.
Table 2. The sample means and standard deviations of the index to be measured when K = 3.
In Tables and , we report the results for variable selection and identification of subgroups. The NT and NE values indicate that our method exhibits comparable performance to other methods in identifying relevant variables while outperforming them in efficiently screening out irrelevant variables. The proposed approaches also achieve higher RI and lower FK values, further establishing their superiority over the alternative methods. Despite facing increased challenges in model recovery due to higher censoring rates and larger parameter dimensions, our method still maintains a remarkably low prediction error rate for the number of subgroups. Incorrect estimations only occur when the deletion ratio reaches , underscoring the robustness of our approach even under such demanding conditions.
Table 3. The sample means and standard deviations of the index to be measured when K = 2.
Table 4. The sample means and standard deviations of the index to be measured when K = 3.
6. An empirical application to the HIV drug resistance data
Antiretroviral therapy (ART) is a common medical treatment for human immunodeficiency virus (HIV). However, the high mutation rate of HIV leads to drug-resistant mutations (DRMs) in HIV-infected patients receiving ART. In response to this challenge, physicians regularly monitor HIV viral load. When the patient's treatment regimen fails to suppress the virus, genotypic testing is conducted to check for DRMs, and subsequently, they can update the patient's drug regimen appropriately.
To identify DRMs and quantify the degree of resistance they provide to different ART treatments, the proposed approach is applied to model the relationship between HIV viral load and mutations in the virus's genome. The data used in this section are from the OPTIONS trial by the AIDS Clinical Trials Group (Gandhi et al., Citation2020), which can be downloaded from the Stanford HIV Drug Resistance database (Shafer, Citation2006). Specifically, the OPTIONS trial encompassed 412 participants afflicted with HIV-infected, who were undergoing protease inhibitor (PI)-based treatment and grappling with virological failure. Each individual was administered an individualized ART regimen on the basis of their drug resistance and treatment history. Individuals exhibiting moderate drug resistance were randomly allocated to either include nucleoside reverse transcriptase inhibitors (NRTIs) into their optimized treatment regimens or to exclude NRTIs from these regimens. Individuals with high drug resistance were all provided with optimized regimens that encompassed NRTIs.
Our dataset includes n = 407 participants who were subjected to a comprehensive 12-week follow-up assessment. Within this dataset, there are a multitude of predictors p = 601, including 99 protease (PR) and 240 reverse transcriptase (RT) gene mutation indicators. Due to the technical limitations of the assays employed for its measurement, it cannot be measured when the HIV viral load is less than the threshold (50 copies/ml), the response variable is left censored. As proposed by Soret et al. (Citation2018), we use -HIV viral load as our response due to its prevalent conformity to a normal distribution. In this trial, 35.6% of individuals have no detectable viral load, which implies a left censoring ratio of 35.6% for the data sample. We compare our proposed methods (SCAD and MCP) and Tobit SCAD (Jacobson & Zou, Citation2023) for modelling HIV viral load 12 weeks after drug regimen assignment as a function of several variables, including HIV genotypic mutations, current drug regimen, baseline viral load, and observation week, etc.
First, to evaluate the performance of model selection, we apply Tobit SCAD and the proposed methods (SCAD and MCP) for fitting the entire data respectively. The constant values are set as in Section 5. Consequently, sparse models containing covariates M184V, the baseline viral load and RAL are consistently selected across all three approaches. Among them, M184V is an indicator of mutations in the reverse transcriptase (RT) gene, and RAL refers to whether the participant was taking raltegravir. The Stanford University HIV Resistance Database lists M184V as a major NRTIs resistance mutation (Jacobson & Zou, Citation2023; Shafer, Citation2006). Moreover, the absence of additional NRTIs being chosen as important variables aligns with the results in Gandhi et al. (Citation2020). This congruence highlights the practical performance of the proposed approaches in model selection. As a result, the specific estimated coefficients are comprehensively shown in Table .
Table 5. The estimators of parameters in the example.
The key difference between the proposed methods and the Tobit SCAD lies in the capacity of the proposed methods to identify the subgroup structures within the intercepts. As depicted in Figure , we present the estimated density function of , where
is the coefficient vector estimate for Tobit SCAD model (Jacobson & Zou, Citation2023). It is not difficult to see the distribution of
is multimodal. Consequently, it appears more appropriate to employ a model with heterogeneous intercepts to fit the dataset. Subsequently, in Figure , we present the density functions estimates of
for two subgroups characterized by different intercepts, where
is the coefficient vector estimate for proposed SCAD model. The density function estimates of the proposed MCP method exhibit similar characteristics and are therefore omitted here. When compared with the density functions shown in Figure , it is evident that each subgroup in Figure displays an unimodal distribution with greater homogeneity.
Figure 1. Density plot of the response variable after adjusting for the effects of the covariates in the empirical example.
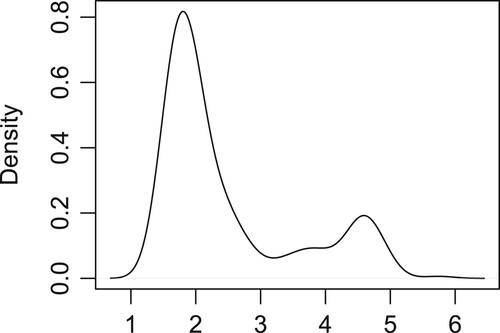
Figure 2. Density plots of response variable after adjusting for the effects of the covariates under two different intercept groups for proposed SCAD method.
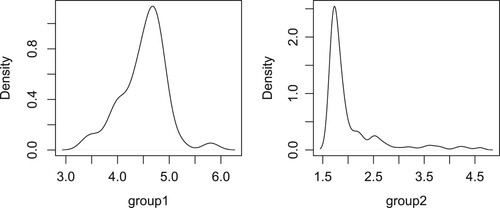
The application of the proposed SCAD method leads to the detection of two subgroups with sample sizes of and
, respectively. It is worth noting that the patients in the OPTION design were originally categorized into two groups: a randomized group consisting of 356 patients, and a highly resistant group, comprising 51 patients. Consequently, we can consider this historical grouping as a control group structure. We calculate the rand index (RI) for the proposed SCAD method based on the control group structure. The rand index (RI) is 0.757, which indicates a substantial degree of agreement between the detected subgroup structure and the historical one. This suggests that the subgroup composition may undergo changes as a result of antiretroviral therapy, a phenomenon that is quite reasonable in the context of HIV patient management.
In addition, we compare the in-sample error and out-of-sample error for the aforementioned methods and the Tobit SCAD method with known subgroup structures. These errors are defined as the mean square error of
across all samples, where
is the fitted response, and
is the predicted response using a 5-fold cross-validation approach. To ensure comparability, we employ stratified sampling to maintain a consistent left-censored ratio across each test set. Table presents the two types of criteria. For both two types of error, the Tobit SCAD method, when applied with known subgroup structures, exhibits smaller errors compared to the homogeneous model. This result underscores the significance of capturing the inherent heterogeneity within the dataset, as it enables more effective modelling of the influential variables affecting the response. While the errors in the control group are slightly larger compared to the proposed methods, it is essential to consider that these discrepancies may stem from changes in drug resistance among patients during treatment. Moreover, the disparities with the control group could serve as a basis for further examination of specific patient cases. It is conceivable that the existence of distinct groups may be attributed to disparities in the treatment trajectories of patients or inherent physiological differences among individuals. In clinical terms, these findings suggest the potential for devising more precise and tailored management protocols for specific patient subgroups, improving the overall treatment efficacy.
Table 6. The in-sample error and out-of-sample error
7. Conclusion
This paper introduces a novel approach to analysing censored data with potential heterogeneity in intercept effects by combining the penalty Tobit likelihood function with a concave fusion penalty. The proposed method can automatically identify heterogeneous structures in intercept effects and conduct variable selection.
To address the optimization problem associated with the method, we propose an algorithm based on the generalized coordinate descent method and alternating direction method of multipliers. This algorithm simplifies the optimization problem and reduces computational costs by employing a quadratic optimization function instead of a complex nonlinear optimization problem. This choice ensures efficient computation, particularly in scenarios with high complexity, while still maintaining good properties for the estimator. Furthermore, we establish the oracle property of parameter estimators. It is shown that within the domain of the oracle solution, a local minimum point of the objective function can be consistent with the oracle solution, providing theoretical support for the correctness of the method. Our ADMM-GCD algorithm with SCAD or MCP performs well in both extensive simulation case studies and the application of real data.
The proposed method can also be extended to incorporate the fusion of coefficient terms. However, there are still challenges in applying this method to generalized linear models or survival models, and further research is needed to develop algorithms and establish theoretical properties in these models.
Acknowledgements
We are very grateful to the editor, managing editor and the referee for their comments that improved this article.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Alhamzawi, A. (2020). A new Bayesian elastic net for Tobit regression. Journal of Physics: Conference Series, 1664(1), 012047.
- Alhamzawi, R. (2016). Bayesian elastic net Tobit quantile regression. Communications in Statistics-Simulation and Computation, 45(7), 2409–2427. https://doi.org/10.1080/03610918.2014.904341
- Amemiya, T. (1973). Regression analysis when the dependent variable is truncated normal. Econometrica: Journal of the Econometric Society, 41(6), 997–1016. https://doi.org/10.2307/1914031
- Amemiya, T. (1984). Tobit models: A survey. Journal of Econometrics, 24(1–2), 3–61. https://doi.org/10.1016/0304-4076(84)90074-5
- Bondell, H. D., & Reich, B. J. (2008). Simultaneous regression shrinkage, variable selection, and supervised clustering of predictors with OSCAR. Biometrics, 64(1), 115–123. https://doi.org/10.1111/biom.2008.64.issue-1
- Boyd, S., Parikh, N., Chu, E., Peleato, B., & Eckstein, J. (2011). Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3(1), 1–122. https://doi.org/10.1561/2200000016
- Bradic, J., Fan, J., & Jiang, J. (2011). Regularization for Cox's proportional hazards model with NP-dimensionality. Annals of Statistics, 39(6), 3092. https://doi.org/10.1214/11-AOS911
- Dagne, G. A. (2016). A growth mixture Tobit model: Application to AIDS studies. Journal of Applied Statistics, 43(7), 1174–1185. https://doi.org/10.1080/02664763.2015.1092114
- Everitt, B. (2013). Finite mixture distributions. Springer Science & Business Media.
- Fan, J., & Li, R. (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association, 96(456), 1348–1360. https://doi.org/10.1198/016214501753382273
- Fan, J., & Lv, J. (2010). A selective overview of variable selection in high dimensional feature space. Statistica Sinica, 20(1), 101–148.
- Fan, Y., & Tang, C. (2013). Tuning parameter selection in high dimensional penalized likelihood. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 75(3), 531–552. https://doi.org/10.1111/rssb.12001
- Gandhi, R. T., Tashima, K. T., Smeaton, L. M., Vu, V., Ritz, J., Andrade, A., Eron, J. J., Hogg, E., & Fichtenbaum, C. J. (2020). Long-term outcomes in a large randomized trial of HIV-1 salvage therapy: 96-week results of AIDS Clinical Trials Group A5241 (OPTIONS). The Journal of Infectious Diseases, 221(9), 1407–1415. https://doi.org/10.1093/infdis/jiz281
- Jacobson, T., & Zou, H. (2023). High-dimensional censored regression via the penalized Tobit likelihood. Journal of Business & Economic Statistics, 42(1), 286–297. https://doi.org/10.1080/07350015.2023.2182309
- Johnson, B. A. (2009). On lasso for censored data. Electronic Journal of Statistics, 3, 485–506. https://doi.org/10.1214/08-EJS322
- Ma, S., & Huang, J. (2017). A concave pairwise fusion approach to subgroup analysis. Journal of the American Statistical Association, 112(517), 410–423. https://doi.org/10.1080/01621459.2016.1148039
- Ma, S., Huang, J., Zhang, Z., & Liu, M. (2019). Exploration of heterogeneous treatment effects via concave fusion. The International Journal of Biostatistics, 16(1), 20180026. https://doi.org/10.1515/ijb-2018-0026
- Müller, P., & van de Geer, S. (2016). Censored linear model in high dimensions: Penalised linear regression on high-dimensional data with left-censored response variable. Test, 25(1), 75–92. https://doi.org/10.1007/s11749-015-0441-7
- Olsen, R. J. (1978). Note on the uniqueness of the maximum likelihood estimator for the Tobit model. Econometrica: Journal of the Econometric Society, 46(5), 1211–1215. https://doi.org/10.2307/1911445
- Powell, J. L. (1984). Least absolute deviations estimation for the censored regression model. Journal of Econometrics, 25(3), 303–325. https://doi.org/10.1016/0304-4076(84)90004-6
- Rand, W. M. (1971). Objective criteria for the evaluation of clustering methods. Journal of the American Statistical Association, 66(336), 846–850. https://doi.org/10.1080/01621459.1971.10482356
- Shafer, R. W. (2006). Rationale and uses of a public HIV drug-resistance database. The Journal of Infectious Diseases, 194(s1), S51–S58. https://doi.org/10.1086/jid.2006.194.issue-s1
- Shen, J., & He, X. (2015). Inference for subgroup analysis with a structured logistic-normal mixture model. Journal of the American Statistical Association, 110(509), 303–312. https://doi.org/10.1080/01621459.2014.894763
- Soret, P., Avalos, M., Wittkop, L., Commenges, D., & Thiébaut, R. (2018). Lasso regularization for left-censored Gaussian outcome and high-dimensional predictors. BMC Medical Research Methodology, 18(1), 1–13. https://doi.org/10.1186/s12874-018-0609-4
- Tobin, J. (1958). Estimation of relationships for limited dependent variables. Econometrica: Journal of the Econometric Society, 26(1), 24–36. https://doi.org/10.2307/1907382
- Tseng, P. (2001). Convergence of a block coordinate descent method for nondifferentiable minimization. Journal of Optimization Theory and Applications, 109(3), 475–494. https://doi.org/10.1023/A:1017501703105
- Wang, H., Li, B., & Leng, C. (2009). Shrinkage tuning parameter selection with a diverging number of parameters. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 71(3), 671–683. https://doi.org/10.1111/j.1467-9868.2008.00693.x
- Wang, H., Li, R., & Tsai, C. L. (2007). Tuning parameter selectors for the smoothly clipped absolute deviation method. Biometrika, 94(3), 553–568. https://doi.org/10.1093/biomet/asm053
- Wang, X., Zhu, Z., & Zhang, H. H. (2019). Spatial automatic subgroup analysis for areal data with repeated measures. arXiv:1906.01853.
- Yan, X., Yin, G., & Zhao, X. (2021). Subgroup analysis in censored linear regression. Statistica Sinica, 31(2), 1027–1054.
- Yang, Y., & Zou, H. (2013). An efficient algorithm for computing the HHSVM and its generalizations. Journal of Computational and Graphical Statistics, 22(2), 396–415. https://doi.org/10.1080/10618600.2012.680324
- Zhang, C. H. (2010). Nearly unbiased variable selection under minimax concave penalty. The Annals of Statistics, 32(2), 894–942.
- Zhao, P., & Yu, B. (2006). On model selection consistency of Lasso. The Journal of Machine Learning Research, 7(90), 2541–2563.
- Zhou, X., & Liu, G. (2016). LAD-lasso variable selection for doubly censored median regression models. Communications in Statistics-Theory and Methods, 45(12), 3658–3667. https://doi.org/10.1080/03610926.2014.904357
- Zou, H. (2006). The adaptive lasso and its oracle properties. Journal of the American Statistical Association, 101(476), 1418–1429. https://doi.org/10.1198/016214506000000735
Appendix
A.1. Proof of Proposition 3.1
First, according to the definition of , we have
for any
. Define
and then we have
Let k be a non-negative integer, since
, so we can obtain that
According to Yang and Zou (Citation2013), we can infer that the GCD limit point
is the coordinatewise minimum of
. Additionally, the objective function is convex with respect to
. Then according to Theorem 4.1 in Tseng (Citation2001), the sequence
converges to a coordinatewise minimum point
. Thus we have
and for all
Therefore,
Since the above inequality holds for all
, then
.
Moreover, since minimize
, by definition, we have that
Thus,
Since
,
Therefore,
.
A.2. Proof of Theorem 4.1
Let , q = K + s + 1. We can see that
according to (Equation20
(20)
(20) ) where
.
In order to get the tail probability of the event in (Equation21(21)
(21) ), we introduce a q-dimension vector
satisfying
, that is
. It is obvious that
. Since
. Then it is easy to get
. Since
is a symmetric positive definite matrix, the maximum value of the quadratic
at
is the largest eigenvalue
of the matrix
.
For a normal distribution , the two-tailed probability inequality is
(A1)
(A1) So
Since the right-side of the above inequality with respect to f is a decreasing function, then
Therefore,
(A2)
(A2) Since
, we set
and
. Then
, where C is a constant. Obviously we have
and then
when
.
A.3. Proof of Theorem 4.2
First, with the underlying group division and true support set
we define
and denote
Let
be the mapping such as that
is the
vector whose kth coordinate equals to the common value of
for
. And let
be the mapping such that
. Let
be the mapping such that
retains only the part of
whose corner is labelled
, that is
. And let
be the mapping such that
. Obviously, when
and
,
and
. Moreover, for every
and
, we have
and
. For every
and
, we have
and
. Hence
(A3)
(A3) Consider the neighbourhood of
Define the event
. By Theorem 1 we have
. For any
and
let
and
. We will prove that
is a local minimizer of the objective function
with probability approaching 1 through the following two steps.
On the event
,
There is an event
Therefore, by the result of (i) and (ii), we have for any
, so that
is a strict local minimizer of
on the event
with
for sufficiently large n.
Step (i): Since is a global minimizer of
,
for all
. Then we derive that
is a constant which does not depend on
for
and
is also a constant which does not depend on
for
. Let
. For any
, since
so
and
(A4)
(A4) Therefore, for all k and
,
which indicates
is a constant by Condition (C2), and as a result
is also a constant. Similarly, for any
, let
, since
By the condition
, we have
As a result, both
and
are constants.
On conclusion, we have for all
. In addition,
and
. Hence, we get
, and the result in (i) is proved.
Step (ii): First, we introduce a neighbourhood for a positive sequence
. For
, by Taylor's expansion at
, we have
where
and
in which
and
for some
. Firstly,
(A5)
(A5) As shown in (EquationA4
(A4)
(A4) ),
(A6)
(A6) Since
,
(A7)
(A7) As the same steps in (EquationA4
(A4)
(A4) ) and (EquationA6
(A6)
(A6) ),
(A8)
(A8) Since
,
(A9)
(A9) Then by Condition (C1),
Consider the ith element of the vector in
, define a positive constant
satisfying
Define
, so we have
Therefore,
By Condition (C3), set a constant
Thus there is an event
such that
, and on the event
,
Under the conditon (C4), it is easy to get
, and hence
(A10)
(A10) Then, denote
,
Swap i and j in the second term of the second equation,
(A11)
(A11) When
, and
has the same sign as
, and hence
Then, for
, since
we have
and thus
. Therefore,
(A12)
(A12) Moreover, by the same reasoning as (EquationA4
(A4)
(A4) ), for
we have
Then
(A13)
(A13) Since
is concave,
. As a result,
(A14)
(A14) On the other hand, we have
(A15)
(A15) Since
and
, on the event
,
(A16)
(A16) Under the condition (C4), we can get
(A17)
(A17) Then,
(A18)
(A18) When
,
, and
has the same sign as
. Hence
(A19)
(A19) For
, by (EquationA9
(A9)
(A9) ),
(A20)
(A20) Thus
. Therefore,
(A21)
(A21) Furthermore, by the same process as (EquationA13
(A13)
(A13) ), for
(A22)
(A22) Let
. Then
,
. Therefore, by (EquationA5
(A5)
(A5) ), (EquationA10
(A10)
(A10) ) and (EquationA14
(A14)
(A14) ),
(A23)
(A23) And by (EquationA15
(A15)
(A15) ), (EquationA17
(A17)
(A17) ) and (EquationA21
(A21)
(A21) ),
(A24)
(A24) Therefore, for sufficiently large n,
so that the result (ii) is proved.