
Figures & data
Figure 1. The illustration of Axial attention. The left part represents horizontal attention. X represents the input feature map, and ,
and
refer to weight matrices of query, key and value for horizontal attention, and
,
and
refer to weight matrices of query, key and value for vertical attention.
and
represent the similarity matrix.
and
is attention by multiplying E with V.
and
is a convolutional kernel, and
denotes the output of horizontal attention. The right part represents vertical attention
and at represents the output of the attention module.
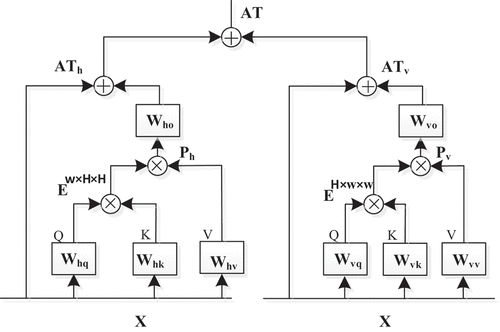
Figure 2. The illustration of the TrajGRU unit. represents the input,
represents the hidden state at time step t-1. γ denotes the sub-network within the TrajGRU model, which includes two convolutional recurrent neural networks (conv). Warp is the function used to select the dynamic connections.
is the updated hidden state at time step t-1. GRU represents a GRU neural network model, and
represents the hidden state at time step t.
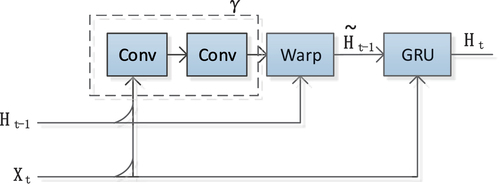
Figure 3. The illustration of the SA-TrajGRU unit. represents the input, and
represents the hidden state at time step t-1. At denotes the attention layer, and
represents the sub-network of the SA-TrajGRU unit, which includes two convolutional recurrent neural networks (conv) and the attention layer (AT). Warp is the function used to select the dynamic connections.
represents the updated hidden state at time step t-1. GRU represents a GRU neural network model, and
represents the hidden state at time step t.
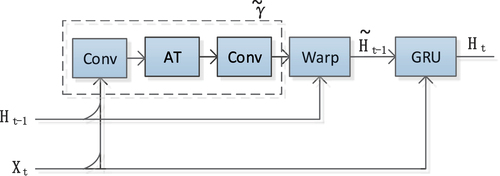
Figure 4. Encode-decode architecture based on SA-TrajGRU units. and
represent the input, while
and
represent the output. Conv refers to the convolution block, and SA-TrajGRU represents the SA-TrajGRU unit, and Deconv represents the deconvolution block.
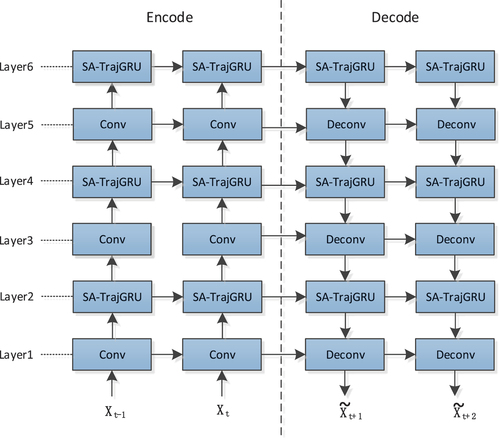
Table 1. The details of the SA-TrajGRU model.
Figure 5. Frame-wise MSE comparisons of different models on the moving MNIST-2 test set. The numbers following the model names in the captions represent the average values of MSE.
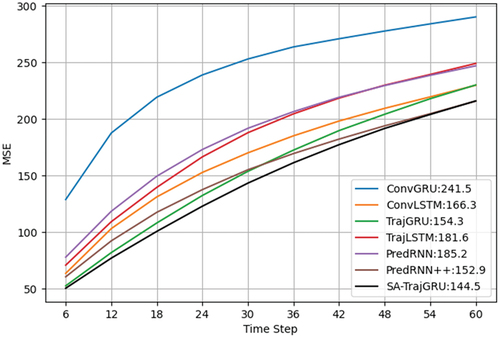
Figure 6. Prediction case on the moving MNIST-2 test set.

Table 2. Comparison of the average rainfall-RMSE scores of different models.
Table 3. Correspondence between dBZ and precipitation intensity.
Figure 7. HSS and CSI scores of different nowcast lead time. (a) HSS τ = 25 dBZ. (b) CSI τ = 25 dBZ. (c) HSS τ = 35 dBZ. (d) CSI τ = 35 dBZ. (e) HSS τ = 45 dBZ. (f) CSI τ = 45 dBZ.
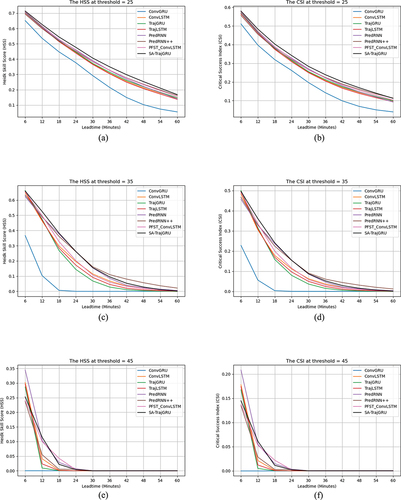
Figure 8. Prediction case of convective precipitation on the CIKM AnalytiCup 2017 test set.

Supplemental Material
Download MS Word (17.6 KB)Data availability statement
The data that support the findings of this study are available the Tianchi Laboratory website on Alibaba Cloud. Data are available at https://tianchi.aliyun.com/dataset/1085 with the permission of Alibaba.