
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Natural Language Processing (NLP) is a technology that permits computers to recognize human languages. Words are the fundamental unit of analysis in deep-level grammatical and semantic analysis. The main goal of NLP is typically word segmentation. Since the machine learning techniques cannot be directly applied to the practical issue of significant structural disparities between various data modalities in a multi-modal context. In this paper, English Vocabulary Learning Aid System Using Digital Twin Wasserstein Generative Adversarial Network Optimized using Jelly Fish Optimization Algorithm is proposed. The problematic of multiple modal data heterogeneity is handled by the feature extraction of Parameterized Local Maximum Synchro squeezing Transform and extract the features such as Phonetic features, sentence length, word embedding’s, part of speech tags, word frequencies, N-grams. Then, the Digital twin Wasserstein generative adversarial network classifies the English vocabulary to easy words, intermediate words, and difficult words. The performance of the proposed EVLS-DtwinWGAN-NLP approach attains 3.101%, 7.12%, 7.73% higher accuracy, 24.13%, 13.04%, 29.51% lower computation Time and 2.292%, 5.365%, 1.551% higher AUC compared with existing methods like Feature extraction and analysis of natural language processing for deep learning English language (EVLS-BiLSTM-NLP), State of art for semantic analysis of natural language processing (EVLS-SA-NLP) respectively.
Introduction
English Vocabulary Learning Aid System based on state-of-the-art Natural Language Processing (NLP) technology (Chen, Xie, and Tao Citation2022; Tai, Chen, and Todd Citation2022). In this fast-paced and interconnected global landscape, the ability to communicate effectively in English has become more essential than ever (Lu et al. Citation2022; Shen Citation2023; Wang et al. Citation2023). Whether a person is a professional seeking to advance in their field, a student aiming to achieve academic success, or just an individual driven by personal development, the novel approach designed to support language learning (Abreu, Grellert, and Bampi Citation2022; Malathi and Vijay Kumar Citation2023). With NLP at its core, our English Vocabulary Learning Aid System is designed to provide a seamless, personalized, and interactive learning experience (Nan and Zhang Citation2022; Zhang and Lakshmanna Citation2022). Gone are the days of tedious memorization and rote learning – our system harnesses the power of artificial intelligence to adapt to your unique needs and learning style (Martínez-Gárate et al. Citation2023; Shao, Ma, and Su Citation2022). It is like having your very own virtual language tutor available 24/7, guiding you through the intricacies of English vocabulary with unwavering patience and support (Hasegawa, Koshino, and Ban Citation2015; Senthilkumar, Tamilarasi, and Periasamy Citation2023). Through cutting-edge NLP algorithms, our system analyzes vast amounts of authentic language data, ranging from literary classics to contemporary texts, to provide you with a diverse and contextually rich vocabulary bank (Tseng, Liou, and Chu Citation2020; Yang et al. Citation2020).
Existing word segmentation models in NLP fall short in two ways: they blindly combine features from multiple modalities without considering their individual importance, and they lack the ability to choose helpful modalities and discard harmful ones. This leads to poor accuracy and long training times. The proposed method tackles these issues by dynamically assigning weights to various modalities depend on their task relevance, selecting the most beneficial ones, and filtering out distracting noise. This allows for capturing long-term semantic dependencies within text, resulting in more efficient and accurate word segmentation, ultimately boosting the performance of various NLP tasks.
The integration of NLP (Natural Language Processing) technology represents a cutting-edge approach to language education. This system employs sophisticated algorithms to enable computers to understand human languages, tailoring the learning experience for users. Through interactive exercises, contextual examples, and personalized feedback, the platform enhances vocabulary acquisition, making the process more dynamic and effective for English language learners. The fusion of NLP and vocabulary learning creates a comprehensive and user-friendly tool that adapts to individual needs, fostering a more immersive and successful language learning journey.
NLP involves combining various algorithms to harness their individual advantages, enhancing accuracy and robustness. This approach is particularly valuable when addressing complex and heterogeneous data, allowing for a nuanced understanding from multiple perspectives. The synergistic effects of combining algorithms can significantly boost performance, especially in tasks where slight improvements matter. Additionally, this amalgamation can contribute to enhanced interpretability, providing insights into model decisions by analyzing the contributions of each algorithmic component.
This approach to English vocabulary learning employs the Parameterized Local Maximum Synchro squeezing Transform (PLMSST), with the Digital Twin Wasserstein Generative Adversarial Network (DtwinWGAN). The former extracts rich features from multi-modal data, including phonetics and word embedding’s, while the latter, inspired by the concept of digital twins, acts as a sophisticated judge of word difficulty through a competitive learning process. The synergy of these techniques allows for fine-grained distinctions between easy, intermediate, and difficult words, enabling a personalized and accurate classification system. Then the approach promises to enhance English vocabulary learning by tailoring educational materials and programs to individual needs for an effectual and engaging learning experience.
The main contributions of this manuscript are abridged below:
The problematic of multiple modal data heterogeneity is handled by the feature extraction of Parameterized Local Maximum Synchro squeezing Transform and extract the features such as Phonetic features, sentence length, word embedding’s, part of speech tags, word frequencies, N-grams (Huang et al. Citation2020).
To solve text long-distance dependencies including long cost of training, Digital twin Wasserstein generative adversarial network (Hasan, Jan, and Koo Citation2023) is proposed and classifies the English vocabulary as easy words, intermediate words, and difficult words.
The proposed EVLS-DtwinWGAN-NLP is examined with accuracy and timeliness. The proposed method has good performance in learning English vocabulary.
The remaining manuscript is organized as follows: part 2 scrutinizes recent studies, part 3 designates proposed method, part 4 illustrates outcomes, part 5 presents the conclusion.
Literature Survey
Several studies were suggested in the literature related to English Vocabulary Learning Aid System based on deep learning; a few recent works are reviewed here,
Wang, Su, and Yu (Citation2020) have presented use of natural language processing feature extraction and investigation for English language deep learning. A neural network with multiple modes was presented. A multilayer sub-neural network exists to each mode. In word segmentation processing, an English word segmentation hybrid network approach was developed in light of problems with existing word segmentation models confirming the long-term dependence of text semantics with long training prediction periods. It offers high accuracy with greater computational time.
Chotirat and Meesad (Citation2021) have suggested Part-of-Speech tagging development to NLP for Thai wh-question categorization along deep learning. An approach was implemented for the utilization of feature selection and word embedding methods to better classify questions from texts. TREC-6 and Thai sentence dataset was used with term frequency as well as consolidated term frequency-inverse document frequency, viz Unigram, Unigram Bigram, Unigram + Trigram Both conventional and deep learning classifier-based machine learning modes were employed. It provides high precision with low accuracy.
Maulud et al. (Citation2021) have suggested current state of the art in natural language processing semantic analysis. Natural Language Processing was the key component of semantic analysis. It identifies the sentence or paragraph in the proper format. Because linguistic classes were interrelated, the terminology employed to communicate the subject’s importance. Semantic interpretation was done in the context of NLP in this article. It provides low computational time with high accuracy.
Ait-Mlouk and Jiang (Citation2020) have suggested KBot: a Knowledge graph base chat Bot for natural language understanding of linked data. Create an interactive user interface first by designing and developing the architecture. The system was adaptable, has numerous knowledge sources, supports several languages, and enables intuitive task design and execution for a wide range of topics. It may also be expanded with a new domain on demand. It provides high sensitivity with low accuracy.
Lauriola, Lavelli, and Aiolli (Citation2022) have suggested deep learning in natural language processing: Models, techniques, and tools. The primary NLP limitations of deep learning as well as the direction of current research were outlined. It offers high precision with less accuracy.
Danenas, Skersys, and Butleris (Citation2020) suggested enhanced extraction of SBVR business vocabulary with business rules from UML using case diagrams and natural language processing. In comparison to previous solution, the presented improvement offers more sophisticated extraction capabilities, and improved superiority of the extraction outcomes. The pre- and post-processing techniques, as well as two extraction strategies using a specially trained POS tagger, are the key contributions made in this study. It offers high precision with low accuracy.
Dessì et al. (Citation2021) have suggested Generating Knowledge Graphs utilizing Natural Language Processing with Machine Learning in the Scholarly Domain. Research article citations, study topics, places, organizations, and authors are frequently included in scientific knowledge graphs, which focus on the academic domain. It offers less computational time with low precision.
shows the benchmark table. Simulation outcomes illustrate from depicts that the EVLS-DtwinWGAN-NLP model offers 3.15%, 11.72%, 21.32%, 15.45%, 18.45%, 25.45%, 4.57% greater accuracy compared with existing methods. The Proposed EVLS-DtwinWGAN-NLP model provide 22.33%, 28.70%, 11.87%, 14.56% 18.76%, 19.43%, 28.09%, higher precision compared with existing. The proposed EVLS-DtwinWGAN-NLP method provides 26.07%, 14.36%, 18.98%, 14.65%, 23.56%, 33.67%, 24.34%, higher sensitivity compared with existing methods. The proposed EVLS-DtwinWGAN-NLP method provides 9.80%, 14.58%, 11.21%, 5.45%, 11.45%, 22.45%, 15.45%, higher specificity compared with existing methods. The Proposed EVLS-DtwinWGAN-NLP model provide 12.54%, 38.56%, 23.67%, 32.33%, 26.45%, 21.54%, 18.78%, higher F-measure compared with existing methods. The Proposed EVLS-DtwinWGAN-NLP model provide 11.22%, 34.67%, 45.7%, 22.22%, 23.54%, 21.98%, 17.65%, 16.76%, higher ROC compared with existing methods. The Proposed EVLS-DtwinWGAN-NLP model offers 10.22%, 24.67%, 15.7%, 32.22%, 16.54%, 14.98%, 31.45% and 18.11% lesser computation time compared with existing methods. The proposed EVLS-DtwinWGAN-NLP model provide 17.22%, 14.67%, 35.7%, 12.22%, 11.55%, 12.11% lesser mean squared error compared with existing Wang, Su, and Yu (Citation2020), Chotirat and Meesad (Citation2021), Maulud et al. (Citation2021), Ait-Mlouk and Jiang (Citation2020), Lauriola, Lavelli, and Aiolli (Citation2022), Danenas, Skersys, and Butleris (Citation2020), Dessì et al. (Citation2021) methods respectively.
Table 1. Some of the Benchmark Table using literature support.
Proposed Methodology
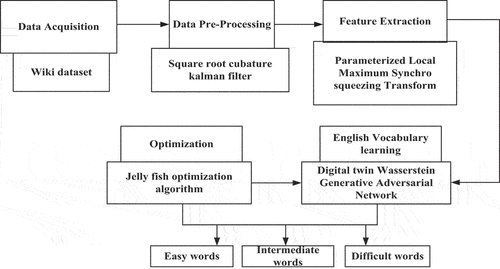
In this section, an English Vocabulary Learning Aid System using Digital twin Wasserstein Generative Adversarial Network (EVLS-DtwinWGAN-NLP) is discussed. The block diagram of EVLS-DtwinWGAN-NLP English Vocabulary Learning Aid System is represented in . It contains five stages, like Data acquisition, pre-processing, feature extraction, categorization and optimization. The comprehensive description about every stage is specified below,
Figure 1. Block diagram of the proposed EVLS-DtwinWGAN-NLP English learning vocabulary system.
Data Acquisition
The data is acquired from Wiki dataset to classify the English words (https://www.kaggle.com/datasets/jacksoncrow/wikipedia-multimodal-dataset-of-good-articles). The dataset consist of 36,476 English Wikipedia articles with 216,463 data. Then, 536 articles are sampled from this smaller set uniformly random. After excluding passages that are less than 500 characters 23,215 texts on various subjects were left.
Pre-Processing Using Square Root Cubature Kalman Filter
SCKF enables the data pre-processing for cleaning the data (Shen et al. Citation2020). Words are the fundamental unit in preparing English text data. Generally speaking, words must be used as the lowest unit in the research topic when it comes to semantics, syntax, etc. The core issue with text information mining is words. The terms in the text are separated one at a time by a computer to examine the text content. Automatic text word processing includes automated data extraction, automated data retrieval, and natural language comprehension. For the purpose of analyzing parts of speech, the derivative square-root cubature Kalman filter is developed. The square-root cubature filter provides excellent precision and robust stability. Think about the subsequent procedure and observation with vocabulary in English texts and the possibility and can be given in EquationEquation 1(1)
(1) ,
where and
denotes system state and measurement at time instant. The cubature rule to approximate n-dimensional Gaussian weighted integral is given in EquationEquation 2
(2)
(2) ,
where implies arbitrary function,
refers domain of incorporation,
refers transposed of
.Approximation with weight for a set of points is represented in EquationEquation 3
(3)
(3) ,
SCKF choose 2n cubature points on the basis of spherical-radial criterion, n implies dimensions of speech. SCKF utilize 2n points and clean the data. Finally, the preprocessed cleaned data is presented toward the feature extraction phase.
Feature Extraction Using Parameterized Local Maximum Synchro Squeezing Transform
In this step, the significant features present under pre-processing are clarified with the help of Parameterized Local Maximum Synchro squeezing Transform (PLMST) (Huang et al. Citation2020). From the pre-processing output, it includes important characteristics of phonetic features, word embedding’s, Ngrams, word frequencies, part of speech tags, sentence length are extracted with the help of Parameterized Local Maximum Synchro squeezing Transform. It addresses the issue of locating the most condensed and comprehensive feature set. The common and useful technique of representing data for classification and regression problems is still figuring out feature vectors. Each characteristic is the outcome of measuring a quantitative or qualitative, or “attribute” or “variable,” and the information is kept in straightforward tables. The secret to experimental research is to take useful elements out of text and avoid processing unnecessary data. The PLMST is a mathematical tool used in signal processing to analyze and extract useful information from time-frequency representations of signals. PLMST is an extension of LMST with additional parameters that allow for more flexibility in the analysis. The LMST and PLMST are typically used with the Continuous Wavelet Transform to achieve time-frequency localization. Here are the key equations for the PLMST.
The continuous wavelet transform of a signal with regard to a wavelet function is given in EquationEquation 4(4)
(4) ,
where denotes scale parameter that regulates the width of wavelet function.
signifies translation parameter that shifts wavelet function along time axis.
The Local Maximum Synchro-Squeezing Transform (LMST) enhances the time-frequency representation obtained from the CWT by reassigning the energy of the CWT coefficients to their local maxima. The LMST of the CWT is given in EquationEquation 5(5)
(5) ,
where represents squared magnitude of the CWT coefficients.
denotes reassignment term that redistributes the energy to local maxima. It is computed based on the ridges of the CWT and their curvature.
The PLMST extends the LMST by introducing additional parameters to control the reassignment process. It includes a reassignment function that maps the ridges to their local maxima. The PLMST is expressed in EquationEquation 6
(6)
(6) ,
The function is determined by the specific parameters chosen for the PLMST. These parameters might include the ridge following method, the density of ridges, or other factors that influence the reassignment of energy. The features are extracted from the PLMST method are provided below,
Phonetic Features
Phonetic features of the audio signal is given in EquationEquation 7(7)
(7) ,
where implies audio signal,
signifies windowing function, and
denotes frequency.
Word Embedding’s
It generates dense word embedding’s based on word co-occurrence patterns. Convert words into one-hot vectors (x) and learn the word embedding’s (w) using the objective function and is given in EquationEquation 8(8)
(8) ,
where is the context word and
is the input word.
is the conditional probability of the context word given the input word is parameterized.
N-Grams
This is contiguous series of N words in a sentence. Given a sentence S with words the equation for extracting N-grams involves generating all possible sequences of N adjacent words and is given in EquationEquation 9
(9)
(9) ,
Word Frequencies
The equation for calculating the frequency of a word w in a corpus of sentences or texts involves counting the occurrences of that word and is given in EquationEquation 10(10)
(10) ,
Part-Of-Speech (POS) Tags
The POS tagging process involves using a trained POS tagger that assigns a tag (noun, verb, adjective) to each word in a sentence.
Sentence Length
The equation for calculating the length of a sentence S in terms of words can be given in EquationEquation 11(11)
(11) ,
Then these extracted features are given into English vocabulary learning aid system classifier.
Classification Using Digital Twin Wasserstein Generative Adversarial Network
In this section, longer distance dependence of text semantics to learn English vocabulary using DtwinWGAN is discussed (Hasan, Jan, and Koo Citation2023). English word segmentation method depends upon neural network, it comprises: (1) character embedding layer – input English letters covert as vector matrix via word embedding; (2) conversion layer including multi-neural networks; (3) labeling discrimination layer – every word creates its own tag data.
A digital twin is an electronic copy or virtual counterpart of a real-world process, entity, system, or item. It is essentially a computer-based model that mirrors the real-world counterpart and allows for monitoring, analysis, and simulation of the physical entity’s behavior and performance. Wasserstein Generative Adversarial Network is dissimilar from the standard Generative Adversarial Network; if that how it is, WGAN utilizes various loss function named Wasserstein loss, these are obtained from Earth Mover’s Distance metric, also solve the vanishing gradient issue. The discriminator together with generator loss function are given in EquationEquation 12(12)
(12) and EquationEquation 13
(13)
(13) ,
The discriminator enables WGAN to update the generator parameters; it is not the container for the typical GAN. In the Wasserstein Generative Adversarial Network, the easy data is articulated as 1, the intermediate data as −1, and the difficult data as 0. When gradient norm differs from the adjusted loss value prolonged through gradient penalty, the WGAN technique penalizes the discriminator is given in EquationEquation 14(14)
(14) ,
here, samples from
and
ith uniformly sampled betwixt 0 and 1. The addition of this penalty term enhanced the samples caliber produced through WGAN.
While the discriminator seeks to discriminate between the generator’s simple data and intermediate data samples, the generator tries to provide realistic data samples. Through adversarial training, the discriminator gets stronger at telling easy from tough phrases, while the generator learns to provide increasingly realistic data. The Wasserstein distance is utilized by WGAN to equate the distributions of real and produced data. The Wasserstein distance offers a more substantial and consistent gradient during training, which improves sample quality and stabilizes GAN training. The loss function used in a typical WGAN formulation involves minimizing the Wasserstein distance, which is given by the EquationEquation 15(15)
(15)
here, is the real and generated data distribution.
Is the set of all joint distribution between
and
, where
is a cost function between r and s. The Wasserstein distance tries to identify the “optimal transport plan”
that lessens the overall cost of transforming the distribution
. Finally, DtwinWGAN classifies the English vocabulary as easy words, intermediate words and difficult words. An artificial intelligence-based optimization strategy is used for the DtwinWGAN classifier due to its practicality and relevance.
In this work, JFOA is employed to enhance the ideal parameters of DtwinWGAN classifier. Also, JFOA adjust the weight and bias parameters of DtwinWGAN. For the reasoning of JFOA selection is it contains own development, takes slower iteration time, also find out the optimal generators weight parameter. The metaheuristic technique is derived from the foraging and navigational behaviors of jellyfish. The stepwise process of JFOA is given beneath,
Stepwise Procedure of Jellyfish Search Optimizer (JSOA)
Here, the stepwise procedure is considered to achieve ideal values of DtwinWGAN using JSOA (Shaheen et al. Citation2021). First, JSOA makes distributed population uniformly for enhancing ideal DtwinWGAN parameters. The JSOA technique is utilized to stimulate the ideal solution. The Optimizer for Jellyfish Search simulates the jellyfish forage in the ocean. It is a recently created metaheuristic technique that resolves challenging optimization issues in the real world. The JS method exhibits great global exploration capabilities and robustness. However, there is still a considerable area for improvement in terms of addressing intricate optimization problems with several local optima and high dimensions. The step-by-step procedure are provided below.
Step 1: Initialization
The population members of the JSOA are jellyfish. Each jellyfish in the search area has the ability to solve an issue. Every jellyfish’s location inside the search space determines the values for the decision variables. Consequently, the vector component utilized to model every jellyfish as JSOA member is utilized to represent the values of the problem variables. Within the search region, the jellyfish are first positioned at random. This is expressed in EquationEquation 16(16)
(16)
here, denotes jellyfish food quantities,
signifies
jellyfish,
implies jellyfish problem variable in logistic map,
signifies count of jellyfish,
signifies total decision variables.
Step 2: Random generation
The input parameters are created randomly after initialization. The best fitness values are chosen based on clear hyper parameter situation.
Step 3: Evaluation of Fitness Function
The initialization creates random solution. This is assessed through parameter optimization to enhance the DtwinWGAN weight parameter. It is exhibited in EquationEquation 17
(17)
(17) ,
Step 4: Foraging behavior
In 1st phase, simulations of jellyfish behavior basis, population members are updated. The jellyfish in the optimal place is the one with the highest fitness value over all iterations. The jellyfish are guided by the best location jellyfish, the jellyfish chosen by the selection process that looks for food, and a time management mechanism. The pioneer jellyfish in JSOA is regarded as a better member and directs other members to its location at the search space. Jellyfish position updating on the foraging phase is given in EquationEquation 18(18)
(18) ,
where, represents jellyfish location, then the foraging behavior of dimension value is given in EquationEquation 19
(19)
(19)
where, represents new status of
Jellyfish Ocean recurrent,
denotes the
dimension value,
represents pioneer jellyfish.
Step 5: Defense strategies against predators for optimizing
In the second step, using models of jellyfish defensive system against predator attacks, the position of the members of the JSOA population in the search space is updated. Jellyfish defend themselves against attacks by zigzagging and randomly twisting sideways. Because they band together to confound and terrify the hunters, hyenas and dogs that prey on jellyfish are especially aggressive. The enhanced objective function value is given in EquationEquation 20(20)
(20) ,
where, represents defensive structure in the jellyfish strategy,
signifies maximum iterations,
indicates iteration shape and the offensive approach expressed in EquationEquation 21
(21)
(21) ,
where, represents
dimension value,
signifies objective function value. Iterations of the Jellyfish optimization algorithm are carried out by updating the population in relation to the first and second phases. JSOA is a more effective optimizer when it comes to solving certain objective functions. The results of the simulation show that JSOA handles fixed-dimensional multiple modalities better than nine competing algorithms. Update the better candidate solution in the ensuing iterations.
Step 7: Termination Condition
The weight parameter values of generator from DtwinWGAN are optimized under JSOA repeat step 3 until halting criteria
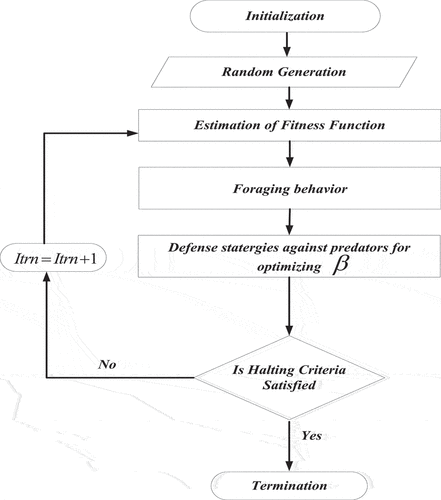
is satisfied. In the end, EVLS-DtwinWGAN-NLP produces efficient results by optimizing the parameters. Then finally EVLS-DtwinWGAN-NLP classifies the English learning vocabulary aid system with greater accuracy by diminishing the computational period. shows that JSOA for optimizing parameters from DtwinWGAN classifier.
Figure 2. JSOA for optimizing parameters from DtwinWGAN classifier.
Result and Discussion
The experimental outcomes of proposed EVLS-DtwinWGAN-NLP are discussed. The proposed technique is simulated utilizing Python using mentioned performance metrics. The obtained outcomes of the EVLS-DtwinWGAN-NLP are evaluated to the existing EVLS-BiLSTM-NLP (Wang, Su, and Yu Citation2020), EVLS-CNN-NLP (Chotirat and Meesad Citation2021), EVLS-SA-NLP (Maulud et al. Citation2021) models respectively.
Performance Measures
The performance metrics is evaluated to examine performance.
Accuracy
Accuracy measures the proportion of overall learning English vocabulary and calculated by the EquationEquation 22(22)
(22) ,
TP signifies true positive, TN implies true negative, FN symbolizes false negative, FP signifies false positive.
Precision
Precision determines the proportion of properly identified words out of all predicted words. This is calculated by EquationEquation 23(23)
(23) ,
Specificity
Specificity estimates the proportion of not learning English vocabulary reader. This is calculated by EquationEquation 24(24)
(24) ,
Sensitivity
Sensitivity finds the proportion of learning English vocabulary and it is given by the EquationEquation 25(25)
(25) ,
F1 Score
The harmonic mean of precision and sensitivity is F1 score. It is calculated using EquationEquation 26(26)
(26) ,
ROC
The ratio of false negative to the true positive area is ROC. This is expressed using EquationEquation 27(27)
(27)
Performance Analysis
depicts experimental outcomes of EVLS-DtwinWGAN-NLP technique. The EVLS-DtwinWGAN-NLP technique performance is analyzed with existing EVLS-BiLSTM-NLP (Wang, Su, and Yu Citation2020), EVLS-CNN-NLP (Chotirat and Meesad Citation2021), EVLS-SA-NLP (Maulud et al. Citation2021)models.
Figure 3. Accuracy analysis.
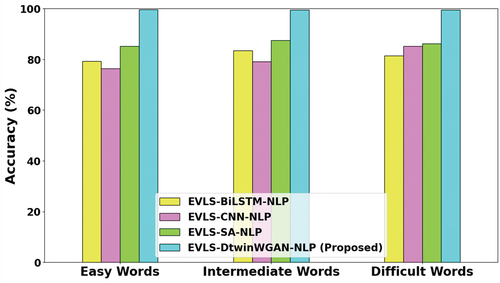
Figure 4. F1 score analysis.
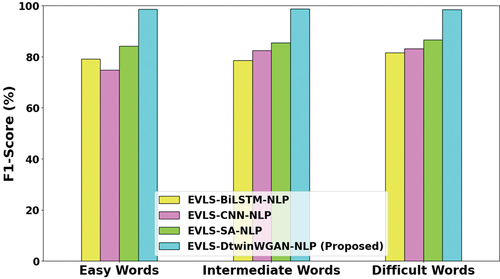
Figure 5. Precision analysis.
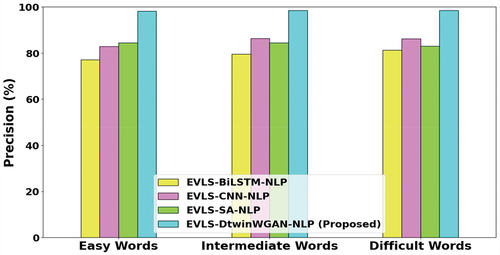
Figure 6. Sensitivity analysis.
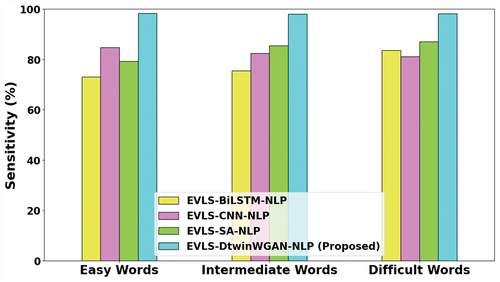
Figure 7. Specificity analysis.
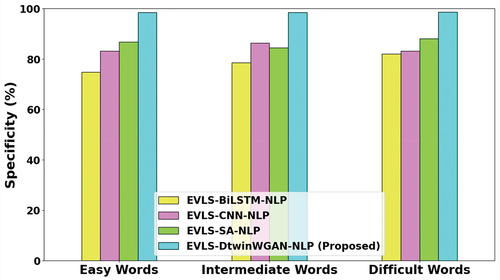
Figure 8. Computation time analysis.
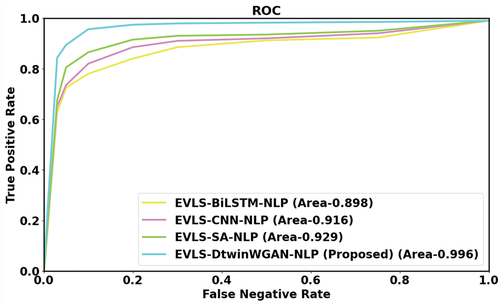
Figure 9. ROC analysis.
Accuracy, defined as the percentage of correctly identified or recalled meanings out of the total presented words, is illustrated in . The analysis reveals that EVLS-DtwinWGAN-NLP outperforms existing methods, including EVLS-BiLSTM-NLP, EVLS-CNN-NLP, and EVLS-SA-NLP. Specifically, for easy words, it achieves 3.88%, 5.75%, and 4.94% higher accuracy; for intermediate words, 2.31%, 8.47%, and 10.51% higher accuracy; and for difficult words, 1.32%, 33.2%, and 23.3% higher accuracy, respectively. These results underscore the superior performance of EVLS-DtwinWGAN-NLP across various difficulty levels compared to its counterparts.
The F1 score serves as a comprehensive metric, amalgamating precision to provide a well-rounded assessment of a system’s efficacy in identifying familiar words. This metric proves particularly valuable in scenarios where there exists an imbalance between the number of recognized and unfamiliar words. The F1-Score analysis depicted in reveals noteworthy results. Specifically, the EVLS-DtwinWGAN-NLP model outperforms existing counterparts, achieving a 12.43%, 8.5%, and 16.67% increase in F1-Score for easy words, a 6.6%, 12.07%, and 16.42% higher F1-Score for intermediate words, and a remarkable 12.3%, 15.6%, and 18.6% improvement in F1-Score for difficult words compared to the EVLS-BiLSTM-NLP, EVLS-CNN-NLP, and EVLS-SA-NLP models, respectively.
In , the Precision analysis reveals notable advancements achieved by the EVLS-DtwinWGAN-NLP method across varying word difficulty levels. Specifically, the method demonstrates a substantial improvement in precision for easy words, surpassing the existing EVLS-BiLSTM-NLP, EVLS-CNN-NLP, and EVLS-SA-NLP models by 5.42%, 12.81%, and 7.45% respectively. For intermediate words, the EVLS-DtwinWGAN-NLP method exhibits superior precision with increases of 9.98%, 6.19%, and 16.12% compared to the aforementioned models. Moreover, in the analysis of difficult words, the EVLS-DtwinWGAN-NLP method outperforms the existing models, achieving precision improvements of 11.2%, 10.9%, and 12.3% for EVLS-BiLSTM-NLP, EVLS-CNN-NLP, and EVLS-SA-NLP, respectively. These findings underscore the method’s effectiveness in precision enhancement across different word complexity categories.
Sensitivity, which gauges the accuracy of identifying known words among the learner’s overall vocabulary, is crucial for pinpointing positive instances in the dataset. illustrates the Sensitivity analysis for EVLS-DtwinWGAN-NLP, revealing significant improvements. The model achieves 8.71%, 13.44%, and 11.15% higher sensitivity for easy words, 3.36%, 8.05%, and 13.19% for intermediate words, and 12.3%, 15.6%, and 14.5% for difficult words compared to existing EVLS-BiLSTM-NLP, EVLS-CNN-NLP, and EVLS-SA-NLP models, respectively. These enhancements showcase the superior performance of EVLS-DtwinWGAN-NLP in accurately detecting known words across different difficulty levels.
Specificity, a measure of the system’s accuracy in identifying unknown words, is crucial for evaluating its performance. In , the specificity analysis is presented. Notably, EVLS-DtwinWGAN-NLP demonstrates superior specificity across difficulty levels. For easy words, it achieves 5.97%, 2.92%, and 10.16% higher specificity compared to EVLS-BiLSTM-NLP, EVLS-CNN-NLP, and EVLS-SA-NLP, respectively. The improvements extend to intermediate and difficult words as well, with increases of 4.57%, 5.68%, 8.22%, and 12.3%, 15.6%, 14.5%, respectively. This underscores the system’s enhanced ability to accurately identify unknown words, outperforming existing models in the specified categories.
The computation time in an English vocabulary learning system is subject to considerable variation, contingent upon factors such as the system’s complexity, vocabulary size, the quantity of words or questions presented to the learner, and the algorithms employed for learning and processing. The Computation Time analysis depicted in reveals noteworthy insights. Specifically, the EVLS-DtwinWGAN-NLP model demonstrates a substantial improvement, achieving a reduction of 51.136%, 59.04%, 44.51% in computation time evaluated to the existing EVLS-BiLSTM-NLP, EVLS-CNN-NLP, and EVLS-SA-NLP models. This indicates the superior efficiency of EVLS-DtwinWGAN-NLP in optimizing computational resources within the English vocabulary learning framework.
In , the RoC estimation is presented, showcasing the performance of EVLS-DtwinWGAN-NLP. Notably, it achieves AUC values 2.292%, 5.365%, and 1.551% higher than the existing EVLS-BiLSTM-NLP, EVLS-CNN-NLP, and EVLS-SA-NLP models, respectively. This demonstrates the superior performance of EVLS-DtwinWGAN-NLP in comparison to these established models across the evaluated metrics.
Discussion
This paper provides additional detail about the exact techniques utilized in the EVLS-DtwinWGAN-NLP technique. In this manuscript, an approach called EVLS-DtwinWGAN-NLP is proposed. The vocabulary learning experience for students could be greatly improved by an English Vocabulary Learning Aid System depending on Natural Language Processing (NLP) technology and DtwinWGAN. In different NLP tasks, deep learning models, particularly those built on the Parameterized Local Maximum Synchro squeezing Transform or its derivatives, have demonstrated amazing capabilities. Strong word embeddings that represent the links between words’ semantic properties can be learned by the proposed EVLS-DtwinWGAN-NLP models. By helping to represent words in a dense vector space, these embeddings make it simpler to comprehend word analogies, similarity, and context-specific meanings. This capacity can be used by an NLP-based vocabulary learning system to give students word definitions, usage examples, and synonyms that are contextually rich, facilitating a deeper comprehension of language in various situations. By allowing the system to create example sentences or workouts based on given words, it can be utilized for sequence-to-sequence learning. The learning process is more interesting and useful because to this interactive method. Natural language understanding features of the system improve student interaction and simplify the instructional process. The system may offer customized vocabulary exercises by examining learners’ interactions and performance. This ensures that each user receives the best possible challenges and learning paths. In conclusion, a deep learning-based scheme for English vocabulary acquisition that is depend on natural provides a language processing gives vocabulary learning cutting-edge capabilities. The system a highly personalized, dynamic, and effective learning experience by utilizing deep learning models, enabling learners to effectively improve their language proficiency and communication skills.
Conclusion
In this section, English Vocabulary Learning Aid system using Digital twin WGAN optimized with JFOA was successfully implemented for classifying the easy words, intermediate words and difficult words (EVLS-DtwinWGAN-NLP). The proposed EVLS-DtwinWGAN-NLP approach is implemented in Python under Wiki dataset. The EVLS-DtwinWGAN-NLP attains 7.69%, 9.504%, 11.786% high Precision; 6.04%, 10.749%, 12.17% high sensitivity; 5.23%, 4.305%, 9.19% high specificity compared with existing EVLS-BiLSTM-NLP, EVLS-CNN-NLP and EVLS-SA-NLP methods. Future research could take into account examining the effects of various feature extraction with feature selection approaches, also boosting the model’s capacity for learning. The proposed method not learns straight forwardly from raw data and treats each type of feature produced by various extraction techniques as an independent mode. There has to be more investigation to directly extract the lesser dimensional features multiple modal fusion from the original multi-modal data.
Acknowledgements
Hubei Vocational and Technical Education Society, Research on Curriculum Reform of “Design and Implementation of Kindergarten Educational Activities” for Preschool Major in Higher Vocational Colleges under the background of “1+X” Certificate System (Project No. : ZJGB2022029).
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
Data sharing does not apply to this article as no new data has been created or analyzed in this study.
Additional information
Funding
References
- Abreu, B., M. Grellert, and S. Bampi. 2022. A framework for designing power-efficient inference accelerators in tree-based learning applications. Engineering Applications of Artificial Intelligence 109:104638. doi:10.1016/j.engappai.2021.104638.
- Ait-Mlouk, A., and L. Jiang. 2020. Kbot: A knowledge graph based chatBot for natural language understanding over linked data. IEEE Access 8:149220–23. doi:10.1109/ACCESS.2020.3016142.
- Chen, X., H. Xie, and X. Tao. 2022. Vision, status, and research topics of natural language processing. Natural Language Processing Journal 1:100001. doi:10.1016/j.nlp.2022.100001.
- Chotirat, S., and P. Meesad. 2021. Part-of-speech tagging enhancement to natural language processing for Thai wh-question classification with deep learning. Heliyon 7 (10):e08216. doi:10.1016/j.heliyon.2021.e08216.
- Danenas, P., T. Skersys, and R. Butleris. 2020. Natural language processing-enhanced extraction of SBVR business vocabularies and business rules from UML use case diagrams. Data & Knowledge Engineering 128:101822. doi:10.1016/j.datak.2020.101822.
- Dessì, D., F. Osborne, D. R. Recupero, D. Buscaldi, and E. Motta. 2021. Generating knowledge graphs by employing natural language processing and machine learning techniques within the scholarly domain. Future Generation Computer Systems 116:253–264. doi:10.1016/j.future.2020.10.026.
- Hasan, M. N., S. U. Jan, and I. Koo. 2023. Wasserstein GAN-based digital twin inspired model for early drift fault detection in wireless sensor networks. IEEE Sensors Journal 23 (12):13327–39. doi:10.1109/JSEN.2023.3272908.
- Hasegawa, T., M. Koshino, and H. Ban. 2015. An English vocabulary learning support system for the learner’s sustainable motivation. Springer Plus 4 (1):1–9. https://www.kaggle.com/datasets/jacksoncrow/wikipedia-multimodal-dataset-of-good-articles.
- Huang, Z., D. Wei, Z. Huang, H. Mao, X. Li, R. Huang, and P. Xu. 2020. Parameterized local maximum synchrosqueezing transform and its application in engineering vibration signal processing. Ieee Access 9:7732–42. doi:10.1109/ACCESS.2020.3031091.
- Lauriola, I., A. Lavelli, and F. Aiolli. 2022. An introduction to deep learning in natural language processing: Models, techniques, and tools. Neurocomputing 470:443–456. doi:10.1016/j.neucom.2021.05.103.
- Lu, H., Y. Zhu, M. Yin, G. Yin, and L. Xie. 2022. Multimodal fusion convolutional neural network with cross-attention mechanism for internal defect detection of magnetic tile. IEEE Access 10:60876–60886. doi:10.1109/ACCESS.2022.3180725.
- Malathi, S. R., and P. Vijay Kumar. 2023. A high-performance low complex design and implementation of QRS detector using modified MaMeMi filter optimized with mayfly optimization algorithm. Journal of Circuits, Systems and Computers 32 (4):2350056. doi:10.1142/S0218126623500561.
- Martínez-Gárate, Á. A., J. A. Aguilar-Calderón, C. Tripp-Barba, and A. Zaldívar-Colado. 2023. Model-driven approaches for conversational agents development: A systematic mapping study. Institute of Electrical and Electronics Engineers Access 11:73088–103. doi:10.1109/ACCESS.2023.3293849.
- Maulud, D. H., S. R. Zeebaree, K. Jacksi, M. A. M. Sadeeq, and K. H. Sharif. 2021. State of art for semantic analysis of natural language processing. Qubahan Academic Journal 1 (2):21–28. doi:10.48161/qaj.v1n2a40.
- Nan, C., and L. Zhang. 2022. Multidimensional psychological Model construction of public English teaching based on deep learning from multimodal perspective. Mobile Information Systems 2022:1–11. doi:10.1155/2022/1653452.
- Senthilkumar, G., K. Tamilarasi, and J. K. Periasamy. 2023. Cloud intrusion detection framework using variational auto encoder Wasserstein generative adversarial network optimized with archerfish hunting optimization algorithm. Wireless Networks 1–18. doi:10.1007/s11276-023-03571-7.
- Shaheen, A. M., R. A. El-Sehiemy, M. M. Alharthi, S. S. Ghoneim, and A. R. Ginidi. 2021. Multi-objective jellyfish search optimizer for efficient power system operation based on multi-dimensional OPF framework. Energy 237:121478. doi:10.1016/j.energy.2021.121478.
- Shao, D., R. Ma, and J. Su. 2022. English long sentence segmentation and translation optimization of professional literature based on hierarchical network of concepts. Mobile Information Systems 2022:1–10. doi:10.1155/2022/3090115.
- Shen, B. 2023. Text complexity analysis of college English textbooks based on blockchain and deep learning algorithms under the internet of things. International Journal of Grid and Utility Computing 14 (2–3):146–55. doi:10.1504/IJGUC.2023.131016.
- Shen, C., Y. Zhang, X. Guo, X. Chen, H. Cao, J. Tang, J. Li, and J. Liu. 2020. Seamless GPS/inertial navigation system based on self-learning square-root cubature Kalman filter. IEEE Transactions on Industrial Electronics 68 (1):499–508. doi:10.1109/TIE.2020.2967671.
- Tai, T. Y., H. H. J. Chen, and G. Todd. 2022. The impact of a virtual reality app on adolescent EFL learners’ vocabulary learning. Computer Assisted Language Learning 35 (4):892–917. doi:10.1080/09588221.2020.1752735.
- Tseng, W. T., H. J. Liou, and H. C. Chu. 2020. Vocabulary learning in virtual environments: Learner autonomy and collaboration. System 88:102190. doi:10.1016/j.system.2019.102190.
- Wang, D., J. Su, and H. Yu. 2020. Feature extraction and analysis of natural language processing for deep learning English language. IEEE Access 8:46335–46345. doi:10.1109/ACCESS.2020.2974101.
- Wang, J., C. Pang, X. Zeng, and Y. Chen. 2023. Non-intrusive load monitoring based on residual U-Net and conditional generation adversarial networks. Institute of Electrical and Electronics Engineers Access 11:77441–51. doi:10.1109/ACCESS.2023.3292911.
- Yang, Q. F., S. C. Chang, G. J. Hwang, and D. Zou. 2020. Balancing cognitive complexity and gaming level: Effects of a cognitive complexity-based competition game on EFL students’ English vocabulary learning performance, anxiety and behaviors. Computers & Education 148:103808. doi:10.1016/j.compedu.2020.103808.
- Zhang, W., and K. Lakshmanna. 2022. An artificial intelligence-based approach to social data-aware optimization for enterprise management. Wireless Communications and Mobile Computing 2022:1–12. doi:10.1155/2022/7691586.