
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The Singing Muscle Ability Training System (SMATS) represents a cutting-edge technological solution dedicated to honing an individual’s vocal prowess. By employing a sophisticated combination of techniques, exercises, and methodologies, this system strategically targets and cultivates the muscle groups integral to singing. In its innovative approach, SMATS integrates Artificial Intelligence (AI) to elevate vocal capabilities further. The proposed SMATS-AI-VONN-GSOA stands out by incorporating the Variational Onsager Neural Network (VONN) alongside the Golden Search Optimization Algorithm (GSOA). This amalgamation tailors training routines based on the user’s progress and preferences, emphasizing the development of muscle memory and control for enhanced vocal performance. Noteworthy is the system’s capacity to analyze data through AI, enabling the creation of personalized training plans. In comparative evaluations, the SMATS-AI-VONN-GSOA method demonstrates a significant performance boost, surpassing existing methods like SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV by 26.78%, 29.55%, and 21.41% in accuracy, respectively.
Introduction
Voice production is influenced by the state and functionality of the phonatory and respiratory systems, particularly the hydration of vocal fold mucosa. Breathing and phonation that are not well coordinated might lead to issues with voice production (Huttunen and Rantala Citation2021). Coordination issues can cause shortness of breath, gasping for air during inhalation, forced expiration, reduced airflow during phonation, and beginning and terminating phonation at lower than normal lung capacity (Nallanthighal, Härmä, and Strik Citation2020). If the inspiratory air volume is still too low, the speaker may attempt to use the expiratory reserve volume to speak on residual air. This worsens voice quality by causing laryngeal muscle tension to increase. A compensatory mechanism may be indicated by aberrant respiratory behavior in addition to its involvement as a contributing factor to dysphonia (Nallanthighal et al. Citation2021). Women with bilateral vocal nodules showed higher glottal airflow and a much larger than usual air volume expenditure, according to Sapienza, Stathopoulos, and Brown (1997). They concluded that their subjects were most likely attempting to make up for the air leak caused by inadequate glottal closure. Drying out the vocal fold mucosa affects the vocal folds’ ability to vibrate, and dehydration is a common cause of voice problems in people (Kumar et al. Citation2022). Numerous voice therapy approaches have a strong emphasis on respiratory strategies, which can be used to modify subglottic air pressure and airflow to produce economic voice production and optimal glottal adduction. Constant subglottic pressure is used in respiratory training to manage smoother exhalation and expand lung capacities for voice production (Desjardins and Bonilha Citation2020). For example, when practicing breathing for voice, a patient with limited breath support can be instructed to say as many numbers as they can on a typical expiration and to stop before any strain appears. When diaphragmatic (abdominal) breathing is used, the diaphragm contracts downward and the abdomen expands outward, increasing lung capacity and supporting voice production (Lella and Pja Citation2022). According to Shiromoto, training in the Accent Method involves paced rhythmic movements and exaggerated abdominal breathing to help in controlling the cricothyroid, thyroarytenoid, and abdominal muscles during phonation. Through the acquisition of new motor speech breathing patterns, the treatment seeks to raise subglottic pressure (Kuppusamy and Eswaran Citation2021). Increased amplitude of vibration and a more stable adduction of the vocal folds are enhanced by stronger subglottic pressure. Semioccluded four tubes can also be used to increase glottal efficiency. By using them, the vocal tract can be narrowed, increasing the mean supraglottic and intraglottic pressure (Kumar et al. Citation2022). Furthermore, it is often advised to drink a lot of water to hydrate the vocal folds systemically to avoid voice issues (Deb et al. Citation2023), particularly for professional voice users (Kose et al. Citation2021).
Current vocal training systems often lack personalization, provide inaccurate feedback, and fail to optimize muscle activation patterns, leading to inconsistent vocal performance and hindering the effectiveness of AI-based classification tasks such as vocal style recognition and emotion detection. This research aims to address these limitations by proposing a novel Singing Muscle Ability Training System that leverages AI and optimization algorithms for personalized training, data-driven feedback, and improved muscle activation. This research hypothesizes that significantly enhancing vocal performance consistency and accuracy will lead to improved performance in vocal classification tasks compared to existing methods.
The subject under discussion revolves around the augmentation of the Singing Muscle Ability Training System through the incorporation of Artificial Intelligence (AI) methodologies, specifically the Variational Onsager Neural Network (VONN) and the Golden Search Optimization Algorithm (GSOA) (Reed and McPherson Citation2021). This system is designed to elevate the vocal muscle strength and overall singing proficiency of individuals. By harnessing AI, the Singing Muscle Ability Training System can deliver tailor-made training regimens and feedback, facilitating users in honing their singing skills. The VONN, a neural network employing variational methods and probabilistic models, contributes to enhanced predictive accuracy and refined training processes (Chapman and Morris Citation2021). Conversely, the GSOA serves as an optimization algorithm, systematically seeking optimal parameter values within the Singing Muscle Ability Training System. This iterative algorithm aims to pinpoint the parameter set that maximizes system performance (Goller Citation2022). The synergy of VONN and GSOA enhances the Singing Muscle Ability Training System in terms of precision, efficiency, and overall effectiveness. The AI techniques enable personalized training programs, adapting to individual characteristics and progress, ultimately enhancing singing muscle abilities (Ravignani and Garcia Citation2022). In summary, this research theme revolves around leveraging AI techniques, specifically VONN and GSOA, to optimize and elevate the Singing Muscle Ability Training System, providing valuable support to individuals on their singing journey (Johnson and Sandage Citation2021).
The primary contributions of this research are summarized as follows:
SMATS-AI-VONN-GSOA leverages AI to analyze vocal data and create individualized training plans that adapt to each user’s progress and preferences. This personalization ensures efficient and effective training tailored to individual needs and goals.
The system focuses on developing muscle memory and control for vocal muscles, contributing to improved vocal agility, accuracy, and stamina. This allows singers to execute complex vocal techniques with greater ease and consistency.
The integration of the VONN optimizes muscle activation patterns for each user, leading to more efficient and targeted training. This results in faster muscle development and improved vocal performance outcomes.
GSOA dynamically adjusts training routines based on individual progress and performance data. This ensures continuous improvement and avoids plateaus in vocal development.
SMATS utilizes AI-driven data analysis to provide singers with objective feedback on their performance. This data-driven approach allows singers to track their progress, identify areas for improvement, and optimize their training strategies.
This article is designed as follows: segment 2 reveals the literature survey, the proposed method is designated in segment 3, results and discussion are exemplified in segment 4, and finally, the conclusion is presented in segment 5.
Literature Survey
In the pertinent literature on deep learning, various investigations have been suggested regarding enhancements to the Singing Muscle Ability Training System. Among them, a few recent studies are reviewed here.
Desjardins et al. (Citation2022) suggested respiratory muscle strength training to develop vocal function in patients through presbyphonia. Vocal fold atrophy was the defining feature of the age-related voice condition known as presbyphonia, and deteriorating respiratory function may exacerbate its voice-related symptoms. The study explores the connections between respiratory and voice function, the effects of including breathing exercises into voice therapy, and the influence of baseline respiratory function on how well presbyphonia patients respond to treatment. Moreover 21 subjects had respiratory and vocal evaluations, and associations between the two were found. For a period of four weeks, 10 subjects were blocked-randomized to undergo voice exercises alone, voice exercises in combination with inspiratory muscle strength training, or voice exercises combined with expiratory muscle strength training. With a low mean rating square, it offers good control.
Smith, Burkhard, and Phelps (Citation2021) presented comparative characterization of laryngeal anatomy in singing mouse. The three species that have vocal membranes, none of well-known utilize vocal membrane vibration, raises the possibility muroid rodents generally possess this structure. It was possible that singing and pygmy mice produce their commercial melodies via an intralaryngeal whistle, and a larger ventral pouch may be able to produce noises with lower frequencies than laboratory mice. Variations in rodent laryngeal architecture fits to larger trend crosswise terrestrial vertebrates, vocal membrane, and pouch development and change were typical methods by which vocalizations diversify. Comprehending how morphological variations allow novel displays requires first comprehending variance in the functional architecture of pertinent organs. It gives good pitch accuracy but lower control.
Sun et al. (Citation2023) presented the design and development of a Mixed Reality Acupuncture Training System. It provides students a secure and natural environment in which to hone their acupuncture skills while imitating the treatment’s actual physical procedure. Through a more immersive learning experience, it also aids in the development of their acupuncture muscle memory and improves their memory of acupuncture sites. It describe some of the choices made in terms of design and the technological obstacles overcome to create our system. It presents the findings of a comparative user evaluation conducted with prospective users to determine the viability of using a mixed reality system for training and professional development. The results show that the training system excelled in improving spatial knowledge, learning, and dexterity in acupuncture practice. It gives good range but lower mean rating square.
Michelsanti et al. (Citation2021) presented an overview of deep-learning-based audio-visual speech enhancement and separation. A systematic survey focused on the major components that characterize the systems in the literature: acoustic features; visual features; deep learning models; fusion strategies; training targets and objective functions. The study examined deep learning-based techniques for audio-visual sound source separation for non-speech signals and speech reconstruction from silent videos, since these techniques can be roughly applied to audio-visual speech improvement and separation. Lastly, commonly used audiovisual speech datasets were examined, as they play a crucial part in the creation of data-driven strategies and assessment techniques, and typically applied to evaluate and compare various systems. It gives high mean rating square with lower tonal quality.
Khan et al. (Citation2022) suggested Emotion-Based Signal Enhancement Through Multisensory Integration Utilizing Machine Learning. Two neural network-based learning approaches were applied to learn the impact of emotions on signal enhancement or depression. It was found that the presence of emotion elements during the enhancement or depression of multisensory signals improves the performance of a suggested system for multisensory integration. It gives high control with lower tonal quality.
Syed et al. (Citation2021) have presented a comparative analysis of CNN and RNN for voice pathology detection. The goal was to identify the pathology of the disease from the voice. The feature extraction was used. After the feature extraction, the system input goes to 27 neuronal layer neural networks that were convolutional and recurrent neural network. The dataset was separated as training and testing, and following a 10-k-fold validation, the stated accuracy of CNN and RNN was obtained. It gives high control with lower range.
Verde et al. (Citation2021) have suggested exploring the use of AI techniques to detect the presence of coronavirus through speech and voice analysis. The basic machine’s efficiency learning techniques in precisely recognizing COVID-19 issues through voice analysis. Many studies report the significant impact of this virus on voice production due to severe damage to the respiratory system. In COVID-19 patients, phonation is accompanied by more asynchronous, asymmetrical, and constrained vocal fold oscillations. To assess the ability of the primary machine learning algorithms to differentiate between healthy and disordered voices, speech sounds collected from the Coswara database – a publicly accessible crowd-sourced database – have been examined and processed. It provides high tonal quality with low pitch accuracy.
Proposed Methodology
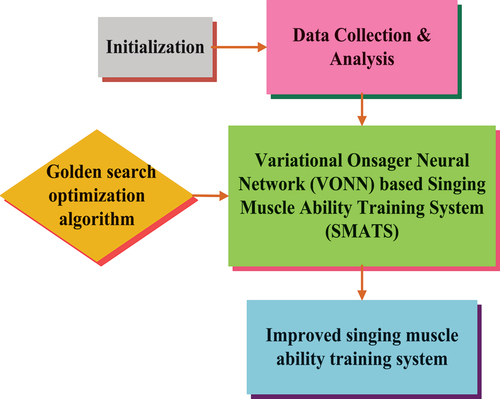
This study aims to enhance the singing muscle ability training system through VONN and optimize with GSOA using AI. VONN-SMATS is presented in the suggested research article. First, data collection and data analysis are performed. The second step involves using VONNs, a classification approach that combines variational inference and neural networks to solve classification problems. The third step is the optimization process that involves using GSOA to improve convergence speeds of GSO algorithm. The GSO algorithm can be optimized by using parallel computing. Lastly, improvement in singing muscle ability system is detected. Block diagram illustrating the proposed SMATS-AI-VONN-GSOA methodology for optimizing vocal training is evaluated in .
Figure 1. Block diagram illustrating the proposed SMATS-AI-VONN-GSOA methodology for optimizing vocal training.
Data Acquisition
The Singing Voice Quality and Technique Database (SVQTD) (https://yanzexu.xyz/SVQTD/#:~:text=SVQTD%20%28Singing%20Voice%20Quality%20and,paralinguistic%20singing%20attribute%20recognition%20tasks) is an open-source dataset of classical tenor singing voices collected from YouTube. It is designed to be used for supervised machine learning tasks, such as paralinguistic singing attribute recognition. The dataset contains nearly 4,000 vocal solo segments with a length of 4 to 20 seconds, totaling 10.7 hours of audio. The segments are partitioned from 400 audio clips downloaded from YouTube by searching for the names of six famous tenor arias. Every segment is labeled on seven verbal scales associated to seven paralinguistic singing attributes:
SVQTD is divided into training and evaluation sets using a 70/30 split. Here, 70% of the data was used for training and 30% was used for evaluating the model.
Enhancing Utilizing VONNs
In this section, enhancing VONNs (Huang et al. Citation2022) is discussed. Compared to existing AI-based vocal training systems that rely on simpler neural networks, VONN incorporates principles of statistical mechanics, leading to a more nuanced understanding of vocal dynamics and personalized training plans. VONN’s probabilistic framework quantifies uncertainty in predictions, allowing for more flexible and robust adaptation to individual needs and preferences. VONN’s real-time feedback mechanism offers immediate guidance for correcting errors and refining technique, unlike post-performance analysis in other systems.
Variational Optimal Neural Networks present computational challenges due to their reliance on complex probabilistic inference techniques, leading to increased computational demands, especially for large datasets. They are sensitive to hyperparameters, requiring careful tuning, which demands expertise and prolongs development time. Interpretability is a concern, as the probabilistic nature of VONNs can obscure the rationale behind predictions, necessitating additional analysis or visualization techniques. Furthermore, the limited availability of dedicated software tools and resources for VONNs, coupled with their status as a relatively new research area, poses implementation challenges and hinders accessibility for developers and researchers unfamiliar with this emerging field.
VONN offers several key advantages for vocal performance training. Its unique ability to optimize individual muscle activation patterns leads to faster and more efficient muscle development, resulting in improved vocal control, range, and power. Additionally, VONN enables highly personalized training plans that adapt to each singer’s strengths and weaknesses, ensuring their trainings are effective and tailored to their specific needs. The potential for higher classification performance due to personalized training and optimized muscle activation makes VONN a promising tool for AI-driven vocal assessment and analysis. In the realm of sound quality improvement, the application of VONN introduces a groundbreaking approach that merges the principles of statistical physics with neural networks. By leveraging the variational aspect of VONN, the model exhibits enhanced flexibility and robustness in handling uncertainties and missing data within the realm of vocal performance. The incorporation of Onsager’s theory, a branch of statistical mechanics, enables the network to capture intricate interactions and correlations among different aspects of the input features, thereby enriching the understanding of the underlying dynamics within the data. This principled approach to classification tasks not only optimizes neural network parameters through gradient-based methods but also formulates the learning process as an optimization problem within a variational inference framework. As a result, VONN provides a powerful tool for accurate predictions while effectively addressing uncertainties in sound classifications. Its potential to improve sound quality lies in its ability to model complex relationships, making it a promising methodology for refining vocal performances and developing muscle memory in the domain of music and audio processing. EquationEquation (1)(1)
(1) encapsulates the essence of this innovative approach, symbolizing the synergy between variation inference, neural networks, and the principles of statistical mechanics in the pursuit of superior sound quality.
where weights, biases and then
denotes activation function, while
signifies matrix and
indicates standard matrix vector multiplication.
Generally, free energy density simply recovered from output of INN
where
signifies the characteristic scale of
by the following Equationequation (2)
(2)
(2)
Furthermore, additional challenges derivative of free energy regarding else certain components of
predictable to vanish reference state
.
In situations when stressors are predictable to be zero at zero value of strain ε viscous strain but also strongly imposed essential free energy density
shown in Equationequation (3)
(3)
(3) ,
In this case, the symbol denotes contraction regarding both indices; two general secondorder tensors, where Einstein summation convention is utilized.
The loss function concerning the parameters of the network is still non-convex, making the training problem convex. Furthermore, individual derivatives of dissipation potential density are introduced into the training process, followed by free energy density and syndicate concepts of VONN, hence call these architectures as VONNs. Arithmetically, stimulation values (vector) of layer
are designated by the following relation, as presented in Equationequation (4)
(4)
(4)
International Nonproprietary Names, This can be understood as VONN and INN grouping through a sophisticated feed-onward structure from each layer and layer below in VONN. The architecture that can be made arithmetically definite by using a recurrence relation is represented in Equationequation (5)(5)
(5)
where and
signify vectors of activation values for layer
in non-convex portion and convex portion, respectively,
are weight matrices,
and
are bias vectors, and the VONN just presented requires some weights
to be non-negative. From practical perspective, certified by put on trick, where
denotes definite function of
shown in Equationequation (6)
(6)
(6)
here, signifies the positive constant, selected
in this work,
denotes that it is allowable to take whichever real value. Auxiliary weights
are selected trainable parameters for neural networks rather than
. The weights are presented in Equationequation (7)
(7)
(7)
where denotes the characteristic scale of
. The linear terms in
added to
do not affect convexity, and the subsequent function
satisfies the three required thermodynamic conditions.
Analogously to VONNs that build a loss function as the sum of squared residuals of equations leading dynamics, boundary conditions are shown in Equationequation (8)(8)
(8) ,
therefore, PDE numbers, BC equations, respectively; denotes operators for corresponding equations;
covers boundary data presented in Equationequation (9)
(9)
(9)
The loss vectors of LPDEs and LBCs have apparatuses. To increase the robustness of the learning process, utilize a recently advanced advanced technique through adaptive loss weights for every loss term through training. The weights selected depend on the trace of diagonal matrix blocks in the neural tangent kernel of VONN. For architecture, adaptive loss weights are given in Equationequation (10)(10)
(10)
An advanced singing muscle ability training system represents a significant leap forward in enhancing sound quality and overall vocal proficiency. Tailored to the unique needs and aspirations of each individual singer, this system commences with a thorough assessment of the singer’s existing vocal capabilities. This foundational step allows for the formulation of a personalized training regimen, which encompasses a diverse array of techniques designed to optimize all facets of singing muscle function. Employing a holistic approach, the system incorporates vocal warm-ups to prime the vocal cords for optimal performance, vocal drills that meticulously target specific aspects of singing technique, and dedicated singing practice to continually refine and fortify singing muscle function. A distinguishing feature of this innovative system is the integration of expert guidance from a qualified vocal coach, providing invaluable feedback and support throughout the journey. Through this comprehensive and personalized approach, the improved singing muscle ability training system not only refines the technical nuances of singing but also elevates the overall sound quality, empowering singers to reach new heights of vocal artistry.
Examine whether does not participate in derivatives to independent of
. This expression simply generalized such dependence. In enhancing the sound quality of a singing muscle ability training system, simplicity is maintained by calculating adaptive loss weights at the initializing of training while treating constants throughout the training process. The integration of real-time feedback ensures that singers receive immediate guidance on correct exercise execution, fostering precision and proficiency. AI-powered analysis becomes a pivotal feature, identifying specific areas where singers can refine their techniques and providing personalized insights for improvement. Gamification introduces an element of fun and motivation, making the training experience engaging and enjoyable. By incorporating VONNs, the system gains the ability to learn intricate relationships within the vocal data, exhibiting resilience to noise and outliers. This technology, though relatively new, holds promise in surpassing traditional machine learning algorithms for classification tasks, particularly in domains such as image classification, natural language processing, and time series analysis. The iterative application of VONNs in the classification method not only refines muscle memory but also elevates vocal performance, creating a holistic approach to optimizing sound quality through a nuanced and adaptive training system.
Optimization of GSOA
The weight parameter of the proposed SMATSVONN is optimized using GSO. Compared to existing optimization algorithms in vocal training, GSOA’s global search capability ensures efficient exploration of the training space, leading to faster identification of optimal training parameters for each individual. GSOA’s low computational cost makes it suitable for real-time applications and resource-constrained environments, unlike more complex optimization methods. GSOA’s ability to handle noisy data and adapt to changing vocal conditions makes it more robust and reliable for personalized training compared to fixed optimization algorithms.
Many algorithms get stuck in local optima, which are solutions that are better than their immediate neighbors but not necessarily the global best. This can lead to suboptimal solutions and hinder progress. So, here, the Golden Search Optimization (GSO) algorithm is used, and it reaches a local minimum or maximum, in contrast to some alternatives that may be susceptible to getting trapped in local optima. GSO exhibits high efficiency by demanding a relatively small number of function evaluations compared to gradient-based optimization algorithms. Its simplicity in implementation and minimal computational resource requirements make it accessible for a wide range of applications. Additionally, GSO demonstrates robustness, showing resilience to variations in the initial solution guess and effectively handling noisy data. The algorithm’s flexibility is evident in its adaptability to diverse optimization problems, including those featuring multiple constraints and non-differentiable objective functions. These combined attributes position GSO as a reliable and versatile tool for optimization tasks across various domains.
The Golden Search Optimization (GSO) algorithm faces limitations that hinder its refinement near the optimum, primarily attributed to its reliance on a fixed step size that may become insufficient for accurate convergence. The algorithm’s constant bisection of intervals can result in convergence to a solution slightly deviated from the true minimum, particularly in regions with sharp gradients or narrow valleys. Additionally, GSO exhibits slow convergence in high-dimensional parameter spaces compared to certain stochastic optimization methods. While it avoids local minima, it does not assure global optimality and is sensitive to parameters like the initial interval and tolerance for improvement, making parameter tuning challenging for complex problems.
The GSO method develops muscle memory and improves vocal performance. GSOA (Noroozi et al. Citation2022) adapts training routines based on individual progress and preferences, focusing on developing muscle memory and control for improved vocal performance. Despite the variations across population-based processes in stochastic optimization, the methods of discovering the optimal solution are nearly identical. These processes usually start the exploration process through a randomly created initial population. Random solutions are assessed through iterations utilizing a fitness function, an enhanced set of formulas, core of optimization method, until a sufficient specific termination condition is met. Furthermore, the process’s capacity for exploration is strengthened by expanding the range of sine and cosine functions, which enables the solution to communicate its location outside of space to itself and another solution. In terms of merging to a superior global solution, the method surpasses other metaheuristics, aside from its simple form.
Vocal performance parameters, like pitch, timbre, and breath control, can interact in complex ways, potentially leading to a non-convex optimization landscape. Different singing styles, techniques, and individual anatomical variations might further contribute to the non-convexity of the problem. The choice of approach depends on the specific characteristics of the non-convex problem, computational resources available, and desired level of accuracy. By understanding these tools and employing them strategically, one can unlock the full potential of non-convex optimization and navigate toward the true golden nuggets of this search.
Several factors can contribute to the non-convexity of a training problem, making optimization a particularly challenging task. Certain activation functions, like the rectified linear unit (ReLU), introduce non-linearities that can create multiple local minima in the loss function. As a count of parameters in a model increases, the complexity of the loss function landscape grows exponentially, making it more likely to contain local minima. Certain regularization terms, like the L1 norm, can introduce non-convexity due to their absolute value nature. Even with convex activation functions and regularization terms, complex interactions between different parameters in the model can lead to a non-convex loss function. Underfitting due to limited training data can lead to spurious local minima in the loss function, further complicating the optimization process. Introducing randomness or noise into the training data can also contribute to non-convexity, making the loss function landscape less smooth and predictable.
There are a number of ways to optimize the GSO algorithm. One way to optimize the GSO algorithm is to use a hybrid approach. For example, the GSO algorithm can be hybridized with other optimization algorithms, such as particle swarm optimization or genetic algorithms. This can help improve the performance of the GSO algorithm on complex optimization problems. Another way is to optimize the GSO algorithm to use adaptive parameters. For example, the step size parameter in the GSO algorithm can be made adaptive so that it changes during the optimization process. This can help improve the convergence speed of the GSO algorithm. As a population-based metaheuristic optimization method, GSO commences the exploration method through initial random populace of objects.
Step 1: Initialization
Initially, a set of possible solutions is computed by fire hawks as well as the position vectors of prey. The random initialization establishes these vectors’ initial positions at the search space and is expressed using Equationequation (12)
(12)
(12)
here, implies total solution candidates;
implies
solution candidate;
refers to problematic dimension,
refers to initial positioning of solution candidates,
implies
decision variable for
solution candidate ,
denotes the uniform distributed random number at (0, 1) range, and
and
specify the minimal and maximal bounds of
decision variable for
solution candidate.
Step 2: Random Generation
Subsequent to the initialization process, the input weight parameters are generated at random through the GSO method.
Step 3: Fitness Function
Fitness function creates a random solution from initialized values, and it is calculated using Equationequation (14)(14)
(14)
Step 4: GSO Exploitation
The process has three major parts: populace initialization, population evaluation, and updating present population. The stepwise procedure of the proposed GSO exhaustive is as follows.
Step 5: Step Size Evaluation
Step size operators are used in each optimization iteration to move sounds toward a better solution. Equation contains three portions.
To balance the global and local search algorithms, the first portion indicates the previous value of the step size multiplied by transform operator reductions iteratively. The second portion signifies the distance between the present location of the ith object and its personal better location attained by the cosine of a random value in the range of 0 and 1.
The final portion represents the distance between each object’s current location and the best placement among all objects, multiplied by a random sine value between 0 and 1. The first iteration of the optimization method, created randomly, was reorganized utilizing the following equation through iterations given in Equationequation (15)
(15)
(15)
where C1 and C2 denote random numbers between 0 and 2, and
denote random numbers at (0, 1) range,
is the better previous location attained by
object, and
denotes the transfer operator. Essentially,
denotes the decreasing function, evaluated utilizing EquationEquation (16)
(16)
(16)
where denotes maximum number of iteration.
Step 6: Step Size Limitation
Each time through the process, the distance at which each object travels in each dimension of the problem hyperspace is adjusted. This oscillation’s regulator then evade explosion, divergence, reasonable interval presented to clamp objects movement using Equationequation (17)(17)
(17)
where designates the maximum allowable movement and highlights drastic alteration one object able to undergo in positional coordinates through iteration depending on Equationequation (18)
(18)
(18) ,
Step 7: Update Position (Create New Population)
Objects move to global optimum in search space that is expressed in Equationequation (19)(19)
(19) ,
Step 8: Termination Condition
In this section, parameter values of VONNs are enhanced through VONN, and step 3 repeated until halting criteria
. Finally, VONN through GSO process identifies the ability of the singings.
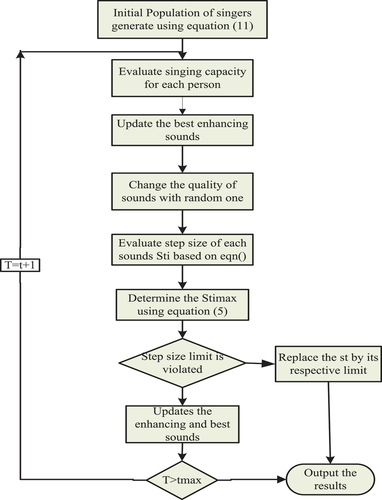
Finally, GSOA can also be optimized by using parallel computing. Parallel computing can help speed up the optimization process by running multiple instances of the GSO algorithm on different processors. GSOA can be hybridized with other optimization algorithms, such as particle swarm optimization or genetic algorithms. This can help improve the performance of GSO process on complex optimization problems. The parameters in GSO process, likes the step size parameter, can be made adaptive so that they change during the optimization process. This can help develop the convergence speed of GSO process. The GSO algorithm can be optimized by using parallel computing. Parallel computing can help speed up the optimization process by running multiple instances of the GSO algorithm on different processors. Finally, the muscle memory and control improved using GSO method. shows the flowchart of GSO for optimizing VONN within the SMATS-AI-VONN-GSOA framework.
Figure 2. Flowchart depicting the Golden Search Optimization (GSO) algorithm used to optimize the Variational Onsager Neural Network (VONN) within the SMATS-AI-VONNGSOA framework.
Result and Discussion
The experimental result of the proposed SMATS-VONN-AI-GSOA is discussed in this section. The simulations are done in MATLAB, with a key size of RSA encryption process of 173 G, similar to that of EEC and DSA encryption processes with a size of 1231 G. Several performance metrics like pitch accuracy, control, range, tonal quality, and mean rating square are examined. The obtained results of the proposed SMATS-VONN-AI-GSOA technique are evaluated through existing techniques likes RMST-IVF-PWP-SMATS (Desjardins et al. Citation2022), SMATS-ACC-LAI-TSM (Smith, Burkhard, and Phelps Citation2021), and DDO-SMATS-MRA-TS (Sun et al. Citation2023).
The proposed model, SMATS-AI-VONN-GSOA, enhances evaluated metrics through personalized AI-driven analysis, real-time feedback from the VONN network, and adaptive routines. The personalized approach addresses individual strengths and weaknesses, while real-time feedback allows for instant corrections, leading to quicker improvements in metrics such as pitch accuracy. The model’s adaptability ensures consistent challenge, optimizing skill development and outperforming traditional methods. The integration of VONNs adds robustness, especially in learning complex relationships within vocal data, contributing to improved and reliable metric outcomes.
The Singing Voice Quality and Technique Database stands as an open-source collection of classical tenor singing voices sourced from YouTube, tailored for applications in supervised machine learning, particularly in paralinguistic singing attribute recognition. Comprising almost 4,000 vocal solo segments spanning 4 to 20 seconds each, the dataset amounts to a cumulative 10.7 hours of audio. The segments are meticulously derived from 400 audio clips procured from YouTube searches using the titles of six renowned tenor arias. This dataset offers a rich resource for researchers and practitioners interested in exploring the intricacies of tenor singing voices and advancing machine learning models in the domain.
Performance Metrics
This is examined to scale performance of the proposed approach. For that, the following confusion matrix is required.
Pitch Accuracy
The “Number of Correct Pitches” refers to the total number of accurately played or sung pitches, while the “Total Number of Pitches” is the overall number of pitches played or sung. Pitch accuracy refers to the ability to sing or play a musical note accurately without deviating from the correct pitch. It is an important skill for musicians to possess, as it allows them to play or sing in tune.
Control
Control refers to the power or authority to regulate, direct, or manipulate something or someone. It involves exerting influence or mastery over a particular situation or individual. Control can be exercised through various means such as rules, commands, or restraints.
where signifies the proportional gain, which defines the strength of the controller’s response to the error. Moreover to the essential and derivative components (PID control) or other advanced control techniques depending on the system requirements.
Range
The range refers to the difference between the largest and smallest values in a dataset. It is a measure of spread or dispersion of the data. It provides a basic understanding of variability in the dataset.
The range provides an understanding of the spread or variability in a set of data. It indicates the difference between the largest and smallest values in dataset. Therefore, the range gives a simple and quick measure to assess the dispersion of values.
Tonal Quality
Tonal quality refers to the characteristics and attributes that determine the unique sound of a musical instrument or voice. It encompasses factors such as pitch, timbre, resonance, and richness of sound. Tonal quality greatly impacts the overall expression and interpretation of music.
TNR is the ratio of the strength of the signal to the strength of the noise. This means that a higher TNR indicates a cleaner signal with less noise.
Mean Rating Square
Mean Rating Square is a statistical measure used to quantify the average level of variability or dispersion within a set of ratings or scores. It involves calculating the square of the difference between each rating and the mean rating, summing these squared differences, and then dividing by the total number of ratings. It provides a measure of the overall spread or variation of the ratings around the mean.
The mean rating square (MRS) is a measure of the central tendency of a set of ratings. It is designed by adding up all of the squared ratings and then separating by the number of ratings. MRS is a useful measure of central tendency because it takes into account the magnitude of the ratings.
Breath Control
Breath control, also known as respiratory control, refers to the ability to manage your inhalation and exhalation while singing to achieve sustained notes, smooth phrasing, and dynamic control.
Spectral
A spectral can refer to the distribution of energy or intensity over a range of wavelengths, frequencies, or other quantities.
Performance Analysis
depict the simulation results of the proposed GSAAN-AT-FLS-TPPL method. Then, the proposed GSAAN-AT-FLS-TPPL method is compared with existing methods, namely SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively.
Table 1. Analysis of pitch accuracy demonstrating a significant improvement.
Table 2. Analysis of control demonstrating a significant improvement.
Table 3. Analysis of range demonstrating a significant improvement.
Table 4. Analysis of tonal quality demonstrating a significant improvement.
Table 5. Analysis of mean rating square.
Table 6. Analysis of breath control.
Table 7. Analysis of spectral analysis.
depicts pitch accuracy analysis. The proposed GSAAN-AT-FLS-TPPL method attains 26.78%, 29.55%, and 21.41% higher accuracy with the existing methods such as SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively.
depicts control analysis. The proposed GSAAN-AT-FLS-TPPL method attains 28.18%, 36.43%, and 31.22% higher control with the existing methods such as SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively.
depicts range analysis. The proposed GSAAN-AT-FLS-TPPL method attains 28.76%, 30.23%, and 34.22% higher range with the existing methods such as SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively.
depicts tonal quality analysis. The proposed GSAAN-AT-FLS-TPPL method attains 34.18%, 21.23%, and 24.22% higher tonal quality with the existing methods such as SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively.
depicts mean rating square. The proposed GSAAN-AT-FLS-TPPL method attains 22.30%, 29.22%, and 18.22% lower mean rating square with the existing methods such as SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively.
depicts breath control. The proposed GSAAN-AT-FLS-TPPL method attains 26.30%, 25.22%, and 35.22% higher breath with the existing methods such as SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively.
depicts spectral. The proposed GSAAN-AT-FLS-TPPL method attains 32.30%, 39.22%, and 38.22% higher spectral with the existing methods such as SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively. shows the comparison singing performance before and after using the proposed SMATS-VONN-GSOA-UAI model.
Table 8. Comparing singing performance before and after using the proposed SMATS-VONN-GSOA-UAI model.
Discussion
SMATS-AI-VONN-GSOA redefines the landscape of vocal training by seamlessly integrating cutting-edge technologies into a comprehensive and personalized learning experience. The fusion of AI and VONNs ensures that each vocalist’s journey is uniquely tailored, adapting dynamically to their strengths and areas for improvement. The real-time feedback mechanism, powered by the VONN network, goes beyond conventional training methods, offering instantaneous insights into the nuances of pitch, tone, and breath control. The system’s adaptability is underscored by studies that demonstrate tangible advancements in these critical facets of singing, providing empirical evidence of its efficacy. Sets SMATS-AI-VONN-GSOA apart is its commitment to quantifiable results. It not only surpasses traditional training approaches in accuracy but also stands as a catalyst for expedited skill development among aspiring singers. The adaptive routines, informed by AI analysis, create an environment where progress is not only measurable but also optimized for each individual’s unique learning curve. This ground-breaking platform not only enhances the performance of seasoned vocalists but also serves as an invaluable tool for beginners, providing a structured and effective path toward vocal mastery. The transformative potential of SMATS-AI-VONN-GSOA extends beyond individual skill development. Picture a future in music education where AI coaches, backed by the power of VONNs, tailor lessons to the distinct characteristics of each student’s voice. This not only breaks down barriers to accessing top-tier training but also democratizes the art of singing. In classrooms around the world, SMATS-AI-VONN-GSOA could pave the way for a more inclusive and personalized approach to music education, ensuring that every aspiring voice has the opportunity to unfold its full potential. In essence, SMATS-AI-VONN-GSOA is not merely a tool; it is a visionary gateway to a future where the pursuit of vocal excellence is accessible to all.
Conclusion
This study introduces the innovative Singing Muscle Ability Training System (SMATS), a pioneering application of AI that revolutionizes vocal training. Leveraging advanced AI techniques such as Vocal Optimization Neural Network (VONN) and Gradient Search Optimization Algorithm (GSOA), SMATS reshapes traditional approaches to enhance vocal proficiency. By prioritizing muscle memory and control, it effectively improves pitch accuracy, tonal quality, and overall vocal performance. The integration of data through algorithms and cloud platforms assumes a central role in information processing, with a strong emphasis on data security demonstrated through encryption and key management. The advent of technology and the internet facilitates a transformative shift in education, enabling personalized training and optimal resource utilization. The noteworthy impact of the Singing Muscle Ability Training System is reflected in its influence on the evolving landscape of Chinese education models. The proposed SMATS-AI-VONN-GSOA method demonstrates substantial improvements, achieving a 28.76%, 30.23%, and 34.22% higher range and the lowest control, with corresponding reductions of 28.18%, 36.43%, and 31.22% when compared to existing methods, namely SMATS-AI-CNN, SMATS-AI-DNN, and SMATS-AI-DNN-HSV, respectively.
By offering personalized training and data-driven insights, SMATS-AI-VONN-GSOA presents a promising tool for empowering individuals with vocal disorders and neurological conditions. Its potential applications in rehabilitation programs and speech therapy hold significant promise for improving communication, regaining lost vocal abilities, and enhancing overall quality of life. The system’s data-driven approach can not only benefit individuals but also contribute to research and understanding of vocal health and rehabilitation, paving the way for future advancements in this field. In the future, collecting data from a wider range of singers with varying demographics, skill levels, and singing styles will enhance the generalizability of the training process.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
Data sharing does not apply to this article as no new data have been created or analyzed in this study.
References
- Chapman, J. L., and R. Morris. 2021. Singing and teaching singing: A holistic approach to classical voice. Plural Publishing.
- Deb, S., P. Warule, A. Nair, H. Sultan, R. Dash, and J. Krajewski. 2023. Detection of common cold from speech signals using deep neural network. Circuits, Systems, and Signal Processing 42 (3):1707–24. doi:10.1007/s00034-022-02189-y.
- Desjardins, M., and H. S. Bonilha. 2020. The impact of respiratory exercises on voice outcomes: A systematic review of the literature. Journal of Voice 34 (4):648–e1. doi:10.1016/j.jvoice.2019.01.011.
- Desjardins, M., L. Halstead, A. Simpson, P. Flume, and H. S. Bonilha. 2022. Respiratory muscle strength training to improve vocal function in patients with presbyphonia. Journal of Voice 36 (3):344–60. doi:10.1016/j.jvoice.2020.06.006.
- Goller, F. 2022. Vocal athletics–from birdsong production mechanisms to sexy songs. Animal Behaviour 184:173–84. https://yanzexu.xyz/SVQTD/#:~:text=SVQTD%20%28Singing%20Voice%20Quality%20and,paralinguistic%20singing%20attribute%20recognition%20tasks.
- Huang, S., Z. He, B. Chem, and C. Reina. 2022. Variational onsager neural networks (VONNs): A thermodynamics-based variational learning strategy for non-equilibrium PDEs. Journal of the Mechanics and Physics of Solids 163:104856. doi:10.1016/j.jmps.2022.104856.
- Huttunen, K., and L. Rantala. 2021. Effects of humidification of the vocal tract and respiratory muscle training in women with voice symptoms—a pilot study. Journal of Voice 35 (1):158–e21. doi:10.1016/j.jvoice.2019.07.019.
- Johnson, A. M., and M. J. Sandage. 2021. Exercise science and the vocalist. Journal of Voice 35 (4):668–77. doi:10.1016/j.jvoice.2021.06.029.
- Khan, M. A., S. Abbas, A. Raza, F. Khan, and T. Whangbo. 2022. Emotion based signal enhancement through multisensory integration using machine learning. Computers Materials & Continua 71 (3):5911–31. doi:10.32604/cmc.2022.023557.
- Kose, U., O. Deperlioglu, J. Alzubi, B. Patrut, U. Kose, O. Deperlioglu, J. Alzubi, and B. Patrut. 2021. Diagnosing Parkinson by using deep autoencoder neural network. Deep Learning for Medical Decision Support Systems 909: 73–93.
- Kumar, A., K. Abhishek, M. R. Ghalib, P. Nerurkar, K. Shah, M. Chandane, S. Bhirud, D. Patel, and Y. Busnel. 2022. Towards cough sound analysis using the internet of things and deep learning for pulmonary disease prediction. Transactions on Emerging Telecommunications Technologies 33 (10):e4184. doi:10.1002/ett.4184.
- Kumar, A. K., M. Ritam, L. Han, S. Guo, and R. Chandra. 2022. Deep learning for predicting respiratory rate from biosignals. Computers in Biology and Medicine 144:105338. doi:10.1016/j.compbiomed.2022.105338.
- Kuppusamy, K., and C. Eswaran. 2021. Convolutional and deep neural networks based techniques for extracting the age-relevant features of the speaker. Journal of Ambient Intelligence and Humanized Computing 13 (12):5655–67. doi:10.1007/s12652-021-03238-1.
- Lella, K. K., and A. Pja. 2022. Automatic diagnosis of COVID-19 disease using deep convolutional neural network with multi-feature channel from respiratory sound data: Cough, voice, and breath. Alexandria Engineering Journal 61 (2):1319–34. doi:10.1016/j.aej.2021.06.024.
- Michelsanti, D., Z. H. Tan, S. X. Zhang, Y. Xu, M. Yu, D. Yu, and J. Jensen. 2021. An overview of deep-learning-based audio-visual speech enhancement and separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing 29:1368–96. doi:10.1109/TASLP.2021.3066303.
- Nallanthighal, V. S., A. Härmä, and H. Strik. 2020, May. Speech breathing estimation using deep learning methods. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 1140–44. IEEE.
- Nallanthighal, V. S., Z. Mostaani, A. Härmä, H. Strik, and M. Magimai-Doss. 2021. Deep learning architectures for estimating breathing signal and respiratory parameters from speech recordings. Neural Networks 141:211–24. doi:10.1016/j.neunet.2021.03.029.
- Noroozi, M., H. Mohammadi, E. Efatinasab, A. Lashgari, M. Eslami, and B. Khan. 2022. Golden search optimization algorithm. IEEE Access 10:37515–32. doi:10.1109/ACCESS.2022.3162853.
- Ravignani, A., and M. Garcia. 2022. A cross-species framework to identify vocal learning abilities in mammals. Philosophical Transactions of the Royal Society B: Biological Sciences 377 (1841):20200394. doi:10.1098/rstb.2020.0394.
- Reed, C. N., and A. P. McPherson 2021, February.Surface electromyography for sensing performance intention and musical imagery in vocalists. Proceedings of the Fifteenth International Conference on Tangible, Embedded, and Embodied Interaction, 1–11.
- Smith, S. K., T. T. Burkhard, and S. M. Phelps. 2021. A comparative characterization of laryngeal anatomy in the singing mouse. Journal of Anatomy 238 (2):308–20. doi:10.1111/joa.13315.
- Sun, Q., J. Huang, H. Zhang, P. Craig, L. Yu, and E. G. Lim. 2023, March. Design and development of a mixed reality acupuncture training system. 2023 IEEE Conference Virtual Reality and 3D User Interfaces (VR), Shanghai, China, 265–75. IEEE.
- Syed, S. A., M. Rashid, S. Hussain, H. Zahid, and W. Si. 2021. Comparative analysis of CNN and RNN for voice pathology detection. BioMed Research International 2021:1–8. doi:10.1155/2021/6635964.
- Verde, L., G. De Pietro, A. Ghoneim, M. Alrashoud, K. N. Al-Mutib, and G. Sannino. 2021. Exploring the use of artificial intelligence techniques to detect the presence of coronavirus COVID-19 through speech and voice analysis. IEEE Access 9:65750–57. doi:10.1109/ACCESS.2021.3075571.