
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The objectives of option hedging/trading extend beyond mere protection against downside risks, with a desire to seek gains also driving agent's strategies. In this study, we showcase the potential of robust risk-aware reinforcement learning (RL) in mitigating the risks associated with path-dependent financial derivatives. We accomplish this by leveraging a policy gradient approach that optimizes robust risk-aware performance criteria. We specifically apply this methodology to the hedging of barrier options, and highlight how the optimal hedging strategy undergoes distortions as the agent moves from being risk-averse to risk-seeking. As well as how the agent robustifies their strategy. We further investigate the performance of the hedge when the data generating process (DGP) varies from the training DGP, and demonstrate that the robust strategies outperform the non-robust ones.
1. Introduction
Option hedging is a foundational issue in the field of mathematical finance, tracing back to the groundbreaking work of Black and Scholes (Citation1973) and Merton (Citation1973). While exact replication of options is achievable in frictionless and complete markets, real-world markets entail transaction costs and necessitate discrete-time trading, rendering perfect replication unattainable. Notably, even under continuous trading conditions, delta hedging ceases to be optimal when trading costs are considered, and it is impossible to replicate arbitrary payoffs. Various studies have addressed the influence of market frictions on option hedging, including those by Whalley and Wilmott (Citation1997) and Martinelli (Citation2000).
Contemporary research has increasingly focussed on developing more robust, model-agnostic approaches to option hedging, with a growing interest in machine learning techniques (see Ruf and Wang Citation2020 for an overview). For instance, Cao et al. (Citation2021) and Kolm and Ritter (Citation2019) have proposed hedging strategies that involve solving mean-variance optimization problems using neural networks, Lütkebohmert, Schmidt, and Sester (Citation2022) study pricing under parameter uncertainty, and Gierjatowicz et al. (Citation2020) find robust bounds for prices of derivatives using neural stochastic differential equations. Recently,Footnote1 Limmer and Horvath (Citation2023) study robustification by selecting sample paths from a bank of models and penalize models by the amount they deviate from a reference model.
As perfect replication is unattainable, agents must bear some risk exposure when buying/selling options. The agent's risk tolerance and appetite dictate the profit and loss (P&L) profile they are willing to accommodate. Rather than aiming to replicate option payoffs, our approach, drawing upon the work of Ilhan et al. (Citation2009) and Buehler et al. (Citation2019), seeks to minimize measures of risk. We propose employing rank dependent expected utility (RDEU) to more comprehensively represent agents' risk preferences, as suggested by Yaari (Citation1987). RDEU enables agents to incorporate the utility associated with outcomes and account for distortions in the probability of those outcomes, thereby facilitating both risk-averse and gain-seeking behaviour concurrently.
Existing literature on option hedging using machine learning largely neglects model misspecification and potential market condition changes. To safeguard agents against such uncertainties, we capitalize on advances in robust reinforcement learning (RL) as outlined by Rahimian and Mehrotra (Citation2019). Specifically, we employ the framework presented by Jaimungal et al. (Citation2022) to robustify RDEU-based strategies and apply them to the option hedging problem.
In this framework, agents assess a strategy not by the RDEU of terminal wealth, but by distorting its distribution within a predefined ambiguity set. The ambiguity set comprises all distributions of terminal wealth situated within a Wasserstein ball surrounding the terminal wealth. Agents subsequently select actions that are optimal under the worst-case scenario within this ambiguity set. Given the absence of additional assumptions, this approach offers protection against various forms of model uncertainty, including those stemming from underlying asset process misspecification or alterations in market frictions. A similar approach for infinitesimally small uncertainty sets was investigated by Bartl et al. (Citation2021) where they consider sensitivity of a generic stochastic optimization problem to model uncertainty – in a perturbative fashion.
To approximate the agents' strategies, we employ neural networks. At each trading time, the neural network receives features representing the state and produces the hedge and we take a policy gradient approach to improve the policy.
We apply our algorithm to hedge barrier options, demonstrating its capacity to generate sound hedges for stochastic volatility models such as Heston, in the presence of market frictions. Importantly, our algorithm is not contingent upon a specific model and can be applied to any price process or derivative. Moreover, we illustrate that our robust models surpass the classic complete-market outcomes provided by Black–Scholes formulas for pricing barrier options.
The remainder of this article is organized as follows. We provide the relevant mathematical background such as RDEU in Section 2 and Wasserstein distances in Section 3. Section 4 formalizes the robust and non-robust option hedging problems. Section 5 provides policy gradient formulae for solving the optimization problems. We present results for hedging barrier call options in Section 6, where we also investigate how robustness changes optimal strategies. Further examples demonstrate that robust hedges outperform non-robust hedges under model misspecification.
2. Risk Measures
This section provides the basic definitions of the risk measures that we study and their key representation in terms of the distortion and quantile functions. We work on a probability space , moreover, let
represent the set of
-measurable,
-integrable, random variables. Let
be interpreted as random costs imposed on the agent.
Definition 2.1
A risk measure is a mapping and is said to be
Monotone if
implies
Translation Invariant if for
Positive Homogeneous if for
Subadditive if
Coherent if and only if conditions 1–4 are satisfied
In this work, we focus on measuring risk using RDEU risk measures (Yaari Citation1987). These measures fall outside the class of coherent risk measures (Artzner et al. Citation1999) but also include many special cases such as distortion risk measures and expected utility. Agents value wealth according to a utility function, but also consider probabilities of the events subjectively through a distortion function. Formally, RDEU is defined as follows.
Definition 2.2
Let g be an increasing function with g(0) = 0 and g(1) = 1. Let U be a non-decreasing concave an differentiable almost everywhere utility function. The RDEU of a random variable Z is defined as
Under suitable conditions, has a more convenient representation as shown in Theorem 2.1.
Theorem 2.1
Representation of RDEU
If the distortion function g is left-differentiable, the RDEU can be rewritten as
where γ is given by
,
denotes the left hand derivative, and
denotes the quantile function of the random variable Z.
By utilizing the agent's utility function and allowing for distortions in probabilities, the RDEU framework enables us to consider the agent's risk/gain seeking behaviour and ultimately provide a more comprehensive representation of their risk preferences. As option payoffs are not replicable outside of complete market settings, we utilize risk measures to quantify the agent's preferences when hedging.
2.1. Risk Avoiding While Profit Seeking: Risk Measures
In this subsection, we provide a prototypical example of an RDEU risk measure that we utilize in the hedging constructions. We employ them as they allow us to showcase how the investor reacts to avoiding risk while seeking gains with only a few parameters. Henceforth, we call such risk measures simply as risk measures.
Definition 2.3
risk measure Jaimungal et al. Citation2022
Let
for
and
.
is a normalizing constant s.t.
. The
risk measure of a r.v.
is defined as:
(1)
(1)
where f is the identify function, i.e.,
.
Figure provides a visual representation of for select parameters. Different values of α, β and p result in U-shaped distortion functions, which model agents who are concerned about profits below the α quantile and above the β quantile. Moreover, if
, the investor emphasizes losses over gains. The opposite is true for
.
Figure 1. Depictions of for
and
as p varies.
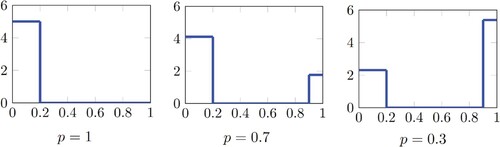
The risk measures contain several notable special cases, such as expected utility and Conditional-Value-at-Risk (CVaR). For example, when p = 1, as shown on the leftmost panel of Figure , the RDEU reduces to CVaR at level α. Furthermore, such risk measures are translation invariant and positive homogeneous. These properties play a role when analyzing the optimal hedging strategies.
3. Wasserstein Distances
In this section, we present a brief overview of Wasserstein distances, which help establish a metric on the set of probability distributions and allow us to define our ambiguity set. For a more detailed coverage of the topic, the reader is referred to, e.g., Santambrogio (Citation2015). In many settings, and in particular for option hedging, the asset price process may be estimated using past data. Once estimated, we can select a strategy and determine its terminal P&L distribution. A natural way to protect the agent from model uncertainty is to consider a family of distributions within a neighbourhood, almost like a confidence interval, of our estimated distribution. Wasserstein distances provide a way to do so. Let be the space of probability measures on
, and define:
with
, i.e., the space of probability measures with bounded pth moment.
Definition 3.1
Given measures , the Wasserstein distance of order p is defined as
(2)
(2)
where
denotes the set of transport plans and contains all measures π such that
and
, for all measurable sets
and
.
Intuitively, the Wasserstein distance measures the cheapest way to transport mass between distributions. The constraints on the transport plans ensures that the total mass removed from a measurable set is equal to
, and total mass transferred to
is equal to
.
We focus on the single asset hedging problem which leads to a univariate P&L random variable. In one-dimension, the optimal coupling that attains the inf in (Equation2(2)
(2) ) is the comonotonic coupling. This leads to a tractable representation of the Wasserstein distance. Consider two measures
having cumulative distribution functions (cdf) F and G, respectively. Define the generalized inverse of a function F on
as
, i.e., when F is a cdf then
is the quantile function. The Wasserstein distance is given by (see, e.g., Ambrosio et al. Citation2003, Chap. 2)
4. Problem Formulation
In this section, we provide an overview of the option hedging problem and how robust methods can be used to protect against model uncertainty.
Consider an agent who shorts an option with payoff at maturity date. The price earned from selling the option at t = 0 is denoted by
. We assume that the asset does not pay dividends, but this may be easily incorporated into the setup. Let
denote the underlying asset price process and – with a slight abuse of notation – let
represent the asset price at time points
. At each
, the agent observes the stock price and chooses the amount
of the asset to hold. For convenience, let
represent the series of actions, and φ represent the set of all hedging strategies.
In some examples, we include market frictions in the form of proportional transaction costs. Formally, given a constant , if the stock price is
and q shares are purchased, we impost a cost of
. Then, given a sequence of trades ϕ the agent's terminal wealth is given by
(3)
(3)
where
represents the asset holdings before any trading.
For simplicity, we set interest rates to 0, however, positive or even stochastic interest rates can be easily incorporated. Furthermore, as risk measures are translation invariant, we can safely ignore
in (Equation3
(3)
(3) ) when optimizing
.
4.1. Non-robust Formulation
We first provide the non-robust formulation of the problem. The agent seeks to minimize the risk of their terminal wealth over the parameter set
. Assuming the agent is certain that the model is correctly specified (i.e., the distribution of
is known with certainty for all actions ϕ), then the their optimization problem may be stated as
(4)
(4)
where the strategy ϕ is parametrized by a neural network that takes observed states as inputs and provides the strategy as output – e.g., a natural choice of states would be the current time and asset price. Thus, the goal is to adjust the weights of the neural net to select the actions that induce the lowest risk.
4.2. Robust Formulation
We also provide a robust formulation of the problem, as agents often do not have full knowledge of the model that drives the asset prices. Even if the agent uses historical data, they should robustify strategies to avoid obtaining strategies that are tuned to the historical price dynamics and work poorly out of sample. If agents use parametric models, then there is uncertainty in the value of those parameters, and even uncertainty whether they chose the correct parametric class of models. A third example of model uncertainty stems from financial markets not being stationary, hence a model that is well calibrated to some slice of historical data may not explain the dynamics well in the future.
As before, we use neural networks to learn the optimal mapping between observed states to ϕ. To build robustness into the model, we consider all probability distributions in an ambiguity set. Specifically, let parameterize the ambiguity set, and
be a
-valued random variable parameterized by
. When the agent considers model uncertainty,
from the previous section serves as an approximation to the true wealth random variable. Thus, the agent builds uncertainty around this base model and uses an ambiguity set
defined below. To protect against uncertainty, the agent picks actions to minimize the risk associated with the worst case distribution in
. Under this framework, we define the agent's optimization as
(5)
(5)
This formulation may be viewed as an adversarial attack. The agent picks actions
which induces a terminal wealth of
. The adversary then distorts
to
that corresponds to the worst performance within a Wasserstein ball around
. To model this relationship, we set
where
is an neural network parameterized by θ. If
and
are both continuous r.v., then, there always exists a neural network θ that achieves equality in distribution – which is all that we need as the risk measures we employ are law invariant. Specifically, let
denote the cdf of
, then the r.v.
has cdf
and, as under the assumption that
and
are continuous r.v., we have that
is continuous and hence there exists a neural network that approximates it (on a finite domain) arbitrarily well.
This formulation allows for uncertainty on the r.v. . Thus, it incorporates potentially both uncertainty in the underlying processes that generate
, transaction costs, and the strategy itself.
5. Optimization Algorithm
In this section, we derive policy gradients for solving the non-robust and robust problems. The robust formulation reduces to the non-robust problem as . However, solving the non-robust version is less computationally intensive, so we present separate algorithms for the two cases.
5.1. Non-robust Problem
We optimize over the possible actions by using batch gradient descent where the gradient is taken with respect to the parameters of the policy. However, many risk measures such as CVaR yield a derivative with discontinuities. Naïve back-propagation leads to inaccuracies and we provide a different gradient formula.
Theorem 5.1
Let and
be the cdf and pdf of
, respectively. Under the assumptions in Theorem 2.1, and further assuming that
is a continuous r.v., we have that
Proof.
As , taking gradients on both sides and using the chain rule we have
and rearranging yields
Using the representation of
in Theorem 2.1, we have that
(6)
(6)
(7)
(7)
For any
, we have that
, and the theorem follows by interpreting the integral as an expectation over a uniform random variable.
The gradient formula requires knowing and
, but in general there is no analytical expression for these quantities. We instead take advantage of the mini-batch environment and use samples to generate a Gaussian kernel density estimator
to approximate
. Specifically, suppose we have a sample of N points of
given by
, then
where
denotes the cdf of a standardized Gaussian and h is a bandwidth selected, see, e.g., Gramacki (Citation2018) for discussions around selecting bandwidths. In our implementations we use Silverman's rule divided by two :
with
being the sample standard deviation. Using the chain rule, we then have
Substituting this expression into Theorem 5.1, and estimating expectation with the sample mean from the same mini-batch of data, the gradient can be approximated by
The remaining task is to obtain
. These may be computed using back-propagation numerically and there is no need for explicit formulae.
5.2. Robust Problem
The steps for solving the robust problem are derived in Jaimungal et al. (Citation2022). We briefly summarize the main results here. Denote the cdf and pdf of by
and
, respectively. Similarly, denote the cdf and pdf of
by
and
, respectively. We define
to denote a penalty for being outside of the desired Wasserstein ball. To enforce the constraints, the augmented Lagrangian approach (which utilizes both a Lagrange multiplier and a quadratic penalty, see, e.g., Birgin and Mario Martínez Citation2014, Chapter 4) may be used as the loss function, and we optimize
Here, µ is a penalty constant that is to be updated as one traverses the loss function along with the Lagrange multiplier λ.
Theorem 5.2
Inner Gradient Formula Jaimungal et al. Citation2022
Under the assumptions of Theorem 2.1, let be a reordering of the realisations of
so that
are comonotonic. Then the inner gradient is
(8)
(8)
where
is a constant.
Theorem 5.3
Outer Gradient Formula Jaimungal et al. Citation2022
Under the same assumptions as Theorem 5.2, the outer gradient is
(9)
(9)
The proof of these formula follow utilizes Theorem 5.1 coupled with the results from Jaimungal et al. (Citation2022). Similar to the previous section, we use kernel density estimation to approximate and
and use sample means in place of the expectation.
6. Numerical Experiments
6.1. The Hedged Options
In this section, we investigate the various hedging strategies of barrier call options under the risk measures defined in Section 2.1. In particular, let B represent the barrier, and K represent the strike price. Then the knock-in and knock-out option payoffs are
In our experiments, the option expires at T = 1, B = 8.5, and K = 10.
6.2. The Market Model
Asset prices S are modelled using the Heston model
(10)
(10)
where ν is the instantaneous variance satisfying the SDE
(11)
(11)
and where
are correlated Brownian motions under the physical measure
. The model parameters carry the following interpretations:
(initial asset price),
(initial variance), µ (drift), κ (the rate at which
reverts to the long run average), θ (long run average variance), η (the volatility of volatility) and ρ (the correlation between
and
).
We stimulate the Heston model using 200 time steps, however, the agent is only allowed to trade once every 4 steps, i.e., at where
. The model parameters in the simulation are as follows
When comparing the robust and non-robust models, we simulate prices from the Heston model, but where some parameters are modified.
6.3. The Black–Scholes Model
To evaluate the performance and interpret our neural network results, we compare to classical results derived from the Black–Scholes model. Recall that the model assumes asset prices are geometric Brownian motions. In particular, S satisfies the SDE
Strictly speaking, the Black–Scholes hedge is not for the purpose of minimizing a risk measure, nor does its derivation include transaction costs, however, the resulting hedge serves as a useful benchmark for evaluating our strategies.
It is well known that, when interest rates are zero, the price of a European call option at time t in the Black–Scholes model is given by
where
. As well, the price of knock-in and knock-out options, before asset prices touch the barrier are provided, respectively, by Westermark (Citation2009)
For knock-in calls, once the barrier is breached, the option becomes a regular call and has value
. For knock-out calls, once the barrier is breached, the option is worthless. For knock-in calls, the Black–Scholes delta hedge is given by
The Black–Scholes delta hedge for a knock-out call is
. In our experiments, when we hedge using the Black–Scholes hedge, we do so at the same set of discrete hedging times that the RL agent uses. Moreover, we use the σ estimated by stimulating price paths
under Heston to generate a distribution for
and computing its standard-deviation divided by
. Thus, obtaining a Black–Scholes model that matches the variance of the Heston model.
6.4. Hedging Features
We now consider the agent's problem as posed in Section 4. The strategy, , is parametrized by a fully connected feed forward neural network with 5 hidden layers each with 35 neurons and SiLU activation functions.Footnote2 The output layer has a tanh activation function that clips strategies to the range
to ensure the agent does not over-leverage. For test cases with no transaction costs, the neural net uses the following five features
where
. When we incorporate transaction costs, we add one more feature: the previous holdings
.
While can be determined through
, each serve a different purpose in the neural network. In most cases, the optimal strategies have a jump discontinuity once the barrier is breached, but, as activation functions are smooth, neural networks have difficulties modelling such discontinuities. Thus, we include the indicator of whether the barrier was breached or not. We include the minimum asset price up to that point in time, as under the
risk measures its effect on optimal strategies is a priori unclear. Under the Black–Scholes model, e.g., only time, price and the indicator matters.
For the robust problem, a second neural net distorts and it is parametrized by a fully connected feed forward neural network with 1 hidden layer of 10 neurons and SiLU activation functions. It takes in a realisations of
and outputs realisations of
. For all experiments, we use the Wasserstein-1 distance and set the radius of the ball to 0.02.
6.5. CVaR
In this section, let , p = 1. For these parameters, the
risk measure reduces to
.
6.5.1. No Transaction Costs
We first set transaction costs to zero to illustrate a few interesting effects that are present even in the case without transaction costs.
Figures and shows the optimal strategy learned by the agent. The top panels show the optimal hedge post knock-out (i.e., once the barrier is breached), while the bottom panels show the pre-knock-out (i.e., before the barrier is breached) hedges. While is a feature, the strategies for CVaR only depend on
but do not depend on the exact value of
. In the lower panels, the hedges stop at
corresponding to the option barrier. Figure shows that, for CVaR, the non-robust strategy are qualitatively and quantitatively fairly similar to the Black–Scholes' delta-hedging. Moreover, Figure shows that, for CVaR, the robust and non-robust are similar, but there are some notable differences. The robust agent does hedges more when the option is out-of-the-money and less when the option is in-the-money. By replicating the option payoff less closely, the agent is better able to handle market uncertainties.
Figure 2. A comparison between trained non-robust strategies (blue) and Black–Scholes delta hedging (orange) for the knock-in call option. The top panel shows post-knock in strategies, while the bottom panels shows pre-knock in strategies.
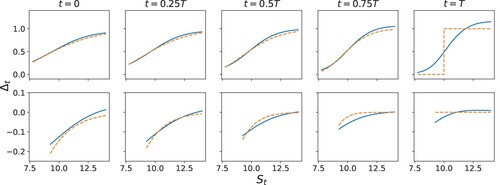
Figure 3. A comparison between robust (red) and non-robust (blue) strategies for the knock-in call option. The top panel shows post-knock in strategies, while the bottom panels shows pre-knock in strategies.
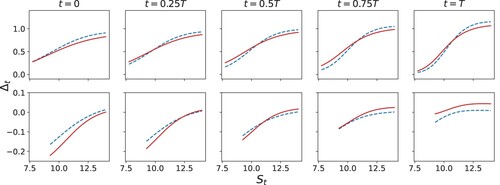
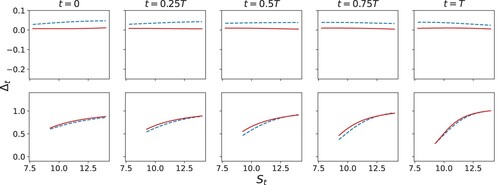
Figure shows the analogous strategies for knock-out call options for the robust and non-robust cases. They are very similar to Black–Scholes hedges (not shown). Naturally, the agent only hedges when the option has not yet been knocked-out, otherwise, once it is knocked-out, the agent holds no position in the robust case, but holds a small positive position in non-robust case. This is because the agent is hoping to gain some positive return from the asset.
Figure 4. A comparison between robust (red) and non-robust (blue) strategies for the knock-out option. The top panel shows post-knock out strategies, while the bottom panels shows pre-knock out strategies.
6.5.2. The Effect of Transaction Costs
Next, we introduce transaction costs and set c = 0.01 in Equation Equation3(3)
(3) . In this case, it is challenging to visualize the strategy as a function of features, as the strategy now becomes a function of t,
,
and
. Instead, we depict the optimal strategy for a few sample paths. To this end, Figure shows the optimal hedge along two sample paths of the asset process – both with and without the transaction costs. The two strategies co-move. The right most panel shows a histogram of total variation of hedge position across 5000 paths As the figure shows, the case with transaction costs has less total variation, indicating that the agent trades less in this case. Both total variations have spikes near zero because if the barrier is never breached the agent trades very few shares.
Figure 5. Strategies for hedging the down-and-in call option with transaction costs (TC) and with no transaction costs (NTC) built into the model. (a) Optimal for two sample asset paths and (b) Histogram of total variation of
across multiple asset paths.
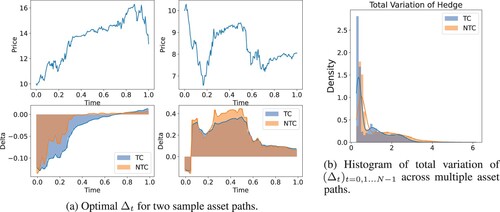
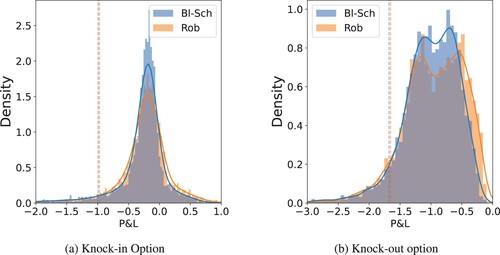
Figure shows a comparison of P&L between the robust strategy and the Black–Scholes option hedging strategy, under uncertainty. All training price paths are generated using the parameters , and
. For the Black–Scholes models, we ignore the transaction cost and estimate σ using the method described above. Furthermore, we assume that the model was misspecified with
and
in reality. When there is model uncertainty, the robust strategy outperforms in both cases.
Figure 6. Comparison of Black–Scholes option hedging (Bl–Sch) and robust (Rob) P&L with transaction cost when model is misspecified with and
in reality. CVaR
is also shown. (a) Knock-in Option and (b) Knock-out option.
6.5.3. Pricing
The methodology we develop may also be used to provide a robust price for options. Suppose the agent wishes to target a of
. As CVaR is translation invariant, after learning a strategy, the agent only needs to adjust the initial option price to reach the required target – the optimal strategy will not be altered – the result price is denoted
.
Next, we compare the price induced by the robust strategy to the price induced by the Black–Scholes strategy. We cannot, however, simply use the Black–Scholes option price as it does not target a CVaR, nor does it include transaction costs. Instead, we generate the P&L of the Black–Scholes and adjust the price until the P&L – we denote this price by
. As a benchmark comparison, we use the classical Black–Scholes barrier option price – denoted
.
Table shows the effect of robust pricing. We train our model with the same parameters as Section 6.5 and assume that in reality and
(instead of
and
). The agent, however, has no way of knowing the true σ, and must price using the misspecified model. From our results, targeting
is a reasonable target, and the generated prices are close to
. As the table shows, the classical Black–Scholes price is the lowest, the price induced by the Black–Scholes hedge (but, accounting for transaction costs, and s.t. CV aR = −0.5) is higher, and finally, as expected, the robust price is the highest.
Table 1. Comparison of different pricing schemes.
6.6. Risk Measures
We next consider risk measures with
,
, and p = 0.7 – see the middle panel of Figure . This corresponds to an agent who cares about gains to losses at a ratio of 3:7.
6.6.1. No Transaction Costs
First we consider no transaction costs. Figure shows the hedging portfolios for a knock-in call in the non-robust case. These strategies are best described as a combination of asset trading and option hedging. When the option is not yet knocked-in, the agent ignores the embedded call option and invests in the asset. In this case, when the asset price is significantly above the barrier, they long the asset, but the strategy has a built in stop-loss. As the minimum asset price drops, they start unwinding their position. If prices drop to around $9, for example, the agent refrains from taking a long position in the asset for the remainder of the session. This strategy allows the agent to take advantage of the positive drift in prices, but also places a cap on the losses incurred from trading the asset. If the barrier is breached, the agent quickly adjusts to option hedging.
Figure 7. Non robust hedging strategies for a down-and-in call option. The graph show total asset holdings at t = 0.5T.
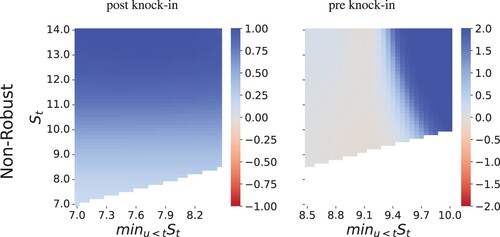
Figure shows the corresponding robust strategy. In this case, the agent becomes more conservative in seeking gains. They begin by buying a small number of shares. If the stock price rises, the agent has made a profit and seeks additional gains by purchasing more shares. Compared with the non-robust case, the agent sets a higher stop loss and generally exits from the long position earlier. Similar to the CVaR cases, when the option is knocked-in, the robust strategy holds less in the stock than the non-robust strategy in an attempt to mitigate model uncertainty.
Figure 8. Robust hedging strategies for a down-and-in call option. The graph show total asset holdings at t = 0.5T.
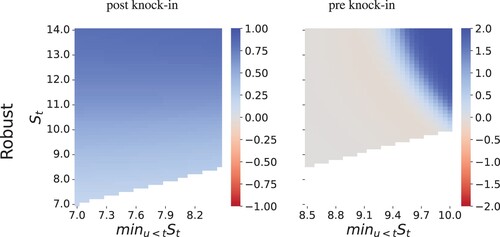
Figure shows analogous results for the knock-out call. When the option is knocked-out (the left panel), the strategy is to go long the asset, but as in the previous examples, it is paired with a stop-loss strategy. When we robustify the strategy, as shown in Figure , the risk in asset trading when knocked-out is greater than the agent can bear, and they simply hold nothing until the end of the trading horizon. In the region before being knocked-out, however, the agent focuses on option hedging. This is dramatic change is due to a phase transition that occurs in investor's behaviour as they change the balance between what is more important gains or losses. We discuss this phenomenon in more detail in Section 6.7.
Figure 9. Non robust hedging strategies for a down-and-out call option. The graph show total asset holdings at t = 0.5T.
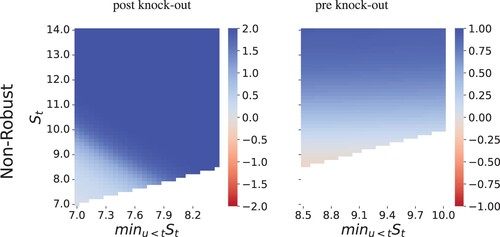
Figure 10. Robust hedging strategies for a down-and-out call option. The graph show total asset holdings at t = 0.5T.
6.6.2. Incorporating Transaction Costs and Robustness
Next, we consider transaction costs of c = 0.01. In Figure , we show the total variation of the position and compare with the no transaction case. Overall, when the agent incorporates transaction costs, they favour strategies with less variance. For example, in the knock-in case, the no-transaction-cost agent purchases close to 2 shares at t = 0. This strategy results in very little transactions when prices rise, however, it performs poorly performing when prices fall because the agent loses from both transaction costs and asset value. Instead, the transaction-cost agent, chooses to buy less shares at t = 0, and adjust shares as needed. Compared to CVaR risk measures, introducing transaction costs has a larger impact on the strategies. For both knock-in and knock-out options, the agent avoids paying the upper tail risk due to the transaction costs.
Figure 11. Comparison of total Variation of the hedge position across different asset price paths in cases with transaction costs (TC) and without transaction costs (NTC). (a) Knock-in option and (b) Knock-out option.
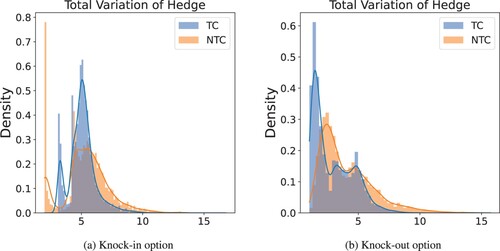
Figure compares the robust and non-robust strategies. Under our framework, uncertainty need not arise from the asset price process. For example, the strategy also protects against changes in transaction costs. Models were trained using the same parameters as before. However, for testing, we increase transaction costs to c = 0.07. In both cases the robust strategy forgoes the upper tail gain in order to minimize losses. Since losses are more valued than gains, the agent is better off in terms of the risk measure.
Figure 12. Comparison of non-robust(N-Rob) and robust (Rob) strategies. is shown as dotted lines in both plots. To help with visualizations, the x-axis uses a symmetric logarithmic scale, with values inside
displayed on a linear scale. (a) Knock-in Option and (b) Knock-out option.
![Figure 12. Comparison of non-robust(N-Rob) and robust (Rob) strategies. −RgU[Xθ] is shown as dotted lines in both plots. To help with visualizations, the x-axis uses a symmetric logarithmic scale, with values inside [−1,1] displayed on a linear scale. (a) Knock-in Option and (b) Knock-out option.](/cms/asset/56895f00-0f75-4a10-9366-1879662c0d5b/ramf_a_2301354_f0012_oc.jpg)
6.7. Phase Transition due to Agent's Preferences
In this section, we examine how the agent's risk preferences affect the optimal strategy and study the non-robust case (as the general features we observed remain similar when we robustify). In particular, we fix and
and vary p to examine how the strategy for the knock-in and knock-out call changes as the agent becomes increasingly risk seeking.
Figure shows the strategies for p = 1, 0.85 and 0.70 along two stock paths. We assume the same training parameters as before and include transaction costs. The strategies for p = 1 and 0.85 are almost identical, and the agent seeks a strategy similar to option hedging. When p decreases to 0.70, however, the agents strategy differs significantly when the embedded call option is not enforced (i.e., in the knock-out case after the barrier breached, while in the knock-in case before the barrier is breached). For example, let us focus on the left sample path for the knock-in option. In this sample path, the asset never went below the barrier, and the p = 0.7 agent kept a long position for the entire path, while the p = 1 and p = 0.85 agents held a very small short position. The more aggressive agent was seeking profits, while the more conservative was initially protecting against the potential of the option getting knocked-in, but then slowly unwound the position as the asset price grew. For the same sample path, but now looking at the knock-out option. The p = 1 and p = 0.85 agents took on a hedging position against the call option, and kept slowly increasing that hedge through time as the asset price grew. While the p = 0.7 agent initially ignored hedging the call option, but as time progressed they transformed their position into a hedge position for the call which appear more and more likely to not get knocked-out.
Figure 13. along two sample paths for knock-in (above) and knock-out (below) options. Strategies shown correspond to p = 1, 0.85 and 0.70.
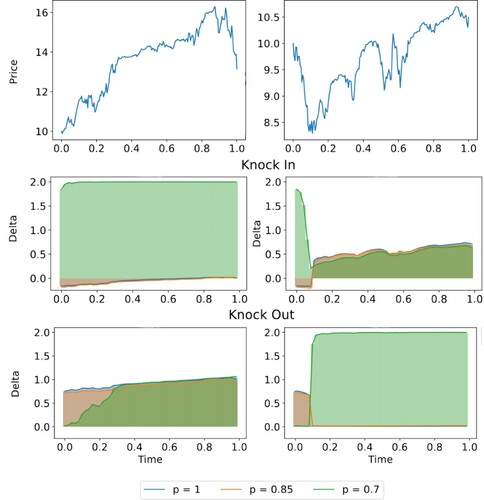
For risk measures, the transition between the agent performing option hedging (Section 6.5) to a mixed strategy of trading and hedging (Section 6.6) is not smooth. There seems to be a phase transition: after a critical point
, the agent changes strategies. We conjecture similar phase transitions persists with risk-reward criteria and is not specific to the
risk measures.
To investigate this observation, we use the non-robust model with no transaction costs as a baseline. Recall that the risk measure can be written as
. We refer to terms
and
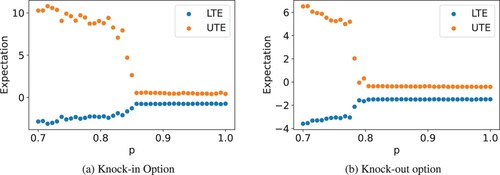
as lower and upper tail expectations (LTEs and UTEs), respectively. Figure shows the effect p has on the optimal strategy. The phase transition appears to occur near
and
for knock-in and knock-out options, respectively. For
, the agent strictly hedges the option. When
, it can be observed that the value of p has a negligible effect on the agent's strategy. Once the value of p falls below
, however, the agent commences a strategy targeting upper tail gains by engaging in both asset trading and option hedging. This critical level
depends on the details of the option being sold. For knock-in calls, a lower barrier makes it more likely that the option is never knocked in. It becomes easier for the agent to seek upper tail gains without the negative option payoff, and thus results in a higher
. The reverse is true for knock-out calls.
Figure 14. Comparison of lower tail expectation (LTE) and upper tail expectation (UTE) for and
while varying p. (a) Knock-in Option and (b) Knock-out option.
To provide additional insight into this phenomenon, we examine the optimal actions of the agent under risk measures in a scenario where there is no option exposure and inventory is subject to the constraint of being within the range of
. In this case, the agent's terminal wealth
is given by setting
in (Equation3
(3)
(3) ). If
, then
, for all
, is an optimal solution – irrespective of p. Not trading is an admissible strategy that attains
. If, however, there exists a strategy
(with parameters
) such that
, then, as
is positive homogeneous, the strategy
(for
) always results in lower risk. Therefore, the strategy is to either trade nothing or to leverage fully. The latter case leads to the large increases in the UTE and this is what results in the phase transition.
As we have observed, this phenomenon seems to apply to options hedging as well. For instance, given that knock-in options behave similarly to assets when the barrier is not breached, the agent employs a strategy akin to asset hedging. The size of the jump in LTE depends on the inventory constraints. Particularly, if there are no constraints on inventory, no optimal solution exists when . Furthermore,
depends on the remaining model assumptions. For example, transaction costs decrease
because transaction costs decrease the potential gains. Robustification also decreases
. This is due to the agent's higher risk aversion, as they aim to optimize the worst case scenario of
rather than
itself. The result of this effect is demonstrated by the dramatically different behaviours seen in Figures and .
7. Conclusion
Here, we extend the results of robust risk-aware optimization in Jaimungal et al. (Citation2022) to exotic barrier options. To contextualize the strategies, we choose to focus on barrier knock-in and knock-out call options. The methodology, however, is applicable to other options and even over the counter derivatives. This approach appears to produce results that are explainable and in line with intuition. Furthermore, robustification provides protection against uncertainty that can stem from many factors including misspecification in asset prices or changes in transaction dynamics. One issue worth noting is that while the strategies use dynamic decision making, the RDEU is not a time consistent risk measure, and the resulting optimizers should be viewed as precomit strategies. Although they are precomit strategies, they are not static in time or state. Nonetheless, it would be interesting to compare how the strategies for option hedging change when considering time-consistent dynamic risk measures using the methods developed in Coache and Jaimungal (Citation2021), Coache, Jaimungal, and Cartea (Citation2022) and Cheng and Jaimungal (Citation2022).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
1 In particular, Limmer and Horvath (Citation2023) appeared online after the current work was submitted for review.
2 The SiLU activation function is given by .
References
- Ambrosio, Luigi, Deckelnick, Klaus, Dziuk, Gerhard, Mimura, Masayasu, Solonnikov, Vsevolod A., Halil Mete Soner, and Ambrosio, Luigi. 2003. Lecture Notes on Optimal Transport Problems. Berlin/Heidelberg: Springer.
- Artzner, Philippe, Delbaen, Freddy, Eber, Jean-Marc, and Heath, David. 1999. “Coherent Measures of Risk.” Mathematical Finance 9 (3): 203–228. https://doi.org/10.1111/mafi.1999.9.issue-3.
- Bartl, Daniel, Drapeau, Samuel, Obłój, Jan, and Wiesel, Johannes. 2021. “Sensitivity Analysis of Wasserstein Distributionally Robust Optimization Problems.” Proceedings of the Royal Society A 477 (2256): 20210176. https://doi.org/10.1098/rspa.2021.0176.
- Birgin, Ernesto G., and Martínez, José Mario. 2014. Practical Augmented Lagrangian Methods for Constrained Optimization. Philadelphia: SIAM.
- Black, Fishcer, and Scholes, Myron. 1973. “The Pricing of Options and Corporate Liabilities.” Journal of Political Economy 81 (3): 637–654. https://doi.org/10.1086/260062.
- Buehler, H., Gonon, L., Teichmann, J., and Wood, B.. 2019. “Deep Hedging.” Quantitative Finance 19 (8): 1271–1291. https://doi.org/10.1080/14697688.2019.1571683.
- Cao, Jay, Chen, Jacky, Hull, John, and Poulos, Zissis. 2021. “Deep Hedging of Derivatives Using Reinforcement Learning.” Journal of Financial Data Science 3 (1): 10–27. https://doi.org/10.3905/jfds.2020.1.052.
- Cheng, Ziteng, and Jaimungal, Sebastian. 2022. “Distributional dynamic risk measures in Markov decision processes.” Preprint, arXiv:2203.09612.
- Coache, Anthony, and Jaimungal, Sebastian. 2021. “Reinforcement Learning with Dynamic Convex Risk Measures.” Mathematical Finance, Forthcoming.
- Coache, Anthony, Jaimungal, Sebastian, and Cartea, Álvaro. 2022. “Conditionally Elicitable Dynamic Risk Measures for Deep Reinforcement Learning.” SIAM Journal on Financial Mathematics, Forthcoming.
- Gierjatowicz, Patryk, Sabate-Vidales, Marc, Šiška, David, Szpruch, Lukasz, and Žurič, Žan. 2020. “Robust Pricing and Hedging Via Neural SDEs.” Preprint, arXiv:2007.04154.
- Gramacki, Artur. 2018. Nonparametric Kernel Density Estimation and Its Computational Aspects. Vol. 37. Cham, Switzerland: Springer.
- Ilhan, Aytaç, Jonsson, Mattias, and Sircar, Ronnie. 2009. “Optimal Static-Dynamic Hedges for Exotic Options Under Convex Risk Measures.” Stochastic Processes and Their Applications 119 (10): 3608–3632. https://doi.org/10.1016/j.spa.2009.06.009.
- Jaimungal, Sebastian, Pesenti, Silvana M., Sheng Wang, Ye, and Tatsat, Hariom. 2022. “Robust Risk-Aware Reinforcement Learning.” SIAM Journal on Financial Mathematics 13 (1): 213–226. https://doi.org/10.1137/21M144640X.
- Kolm, Petter N., and Ritter, Gordon. 2019. “Dynamic Replication and Hedging: A Reinforcement Learning Approach.” The Journal of Financial Data Science 1 (1): 159–171.
- Limmer, Yannick, and Horvath, Blanka. 2023. Robust Hedging GANs. Available at SSRN 4489029.
- Lütkebohmert, Eva, Schmidt, Thorsten, and Sester, Julian. 2022. “Robust Deep Hedging.” Quantitative Finance 22 (8): 1465–1480. https://doi.org/10.1080/14697688.2022.2056073.
- Martinelli, Lionel. 2000. “Efficient Option Replication in the Presence of Transaction Costs.” Review of Derivatives Research 4 (2): 107–131. https://doi.org/10.1023/A:1009632624999.
- Merton, Robert. 1973. “Theory of Rational Option Pricing.” The Bell Journal of Economics and Management Science 4 (1): 141–183. https://doi.org/10.2307/3003143.
- Rahimian, Hamed, and Mehrotra, Sanjay. 2019. “Distributionally Robust Optimization: A Review.” Preprint, arXiv:1908.05659.
- Ruf, Johannes, and Wang, Weiguan. 2020. “Neural Networks for Option Pricing and Hedging: A Literature Review.” Journal of Computational Finance 24 (1): 1–46.
- Santambrogio, Filippo. 2015. Optimal Transport for Applied Mathematicians. Progress in Nonlinear Differential Equations and Their Applications. Springer International Publishing.
- Westermark, Niklas. 2009. Barrier Option Pricing. Degree Project in Mathematics, First Level.
- Whalley, A. E., and Wilmott, P.. 1997. “An Asymptotic Analysis of an Optimal Hedging Model for Option Pricing with Transaction Costs.” Mathematical Finance 7 (3): 307–324. https://doi.org/10.1111/mafi.1997.7.issue-3.
- Yaari, Menahem. 1987. “The Dual Theory of Choice Under Risk.” Econometrica 55 (1): 95. https://doi.org/10.2307/1911158.