
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
We present a Monte Carlo approach to pairs trading on mean-reverting spreads modelled by Lévy-driven Ornstein-Uhlenbeck processes. Specifically, we focus on using a variance gamma driving process, an infinite activity pure jump process to allow for more flexible models of the price spread than is available in the classical model. However, this generalization comes at the cost of not having analytic formulas, so we apply Monte Carlo methods to determine optimal trading levels and develop a variance reduction technique using control variates. Within this framework, we numerically examine how the optimal trading strategies are affected by the parameters of the model. In addition, we extend our method to bivariate spreads modelled using a weak variance alpha-gamma driving process, and explore the effect of correlation on these trades.
1. Introduction
Many empirical studies have demonstrated examples of mean-reverting spreads in different markets. They can be generated by taking long and short positions in stocks and ETFs (Avellaneda and Lee Citation2010; Gatev, Goetzmann, and Rouwenhorst Citation2006; Huck and Afawubo Citation2015), futures contracts (CitationBrennan and Schwartz; CitationDai, Zhong, and Kwok), physical commodity and commodity ETFs (Kanamura, Rachev, and Fabozzi Citation2010; Leung and Li Citation2016), as well as cryptocurrencies (Leung and Nguyen Citation2019).
Another popular approach, the stochastic spread method captures the path behaviour of the spread through a stochastic process with mean reversion. Given a mean-reverting spread process, we consider the problem of pairs trading, that is, extracting trading signals from the model based on the idea that a trade should be entered when the spread is far from the mean, and exited when it returns to the mean, so that the trader profits based on the tendency of the process to mean revert. This is a form of statistical arbitrage. The construction of spreads and extraction of trading signals are derived from the analysis of the underlying model. For instance, Elliott, Van Der Hoek, and Malcolm (Citation2005) propose a mean-reverting Gaussian Markov chain model to describe spread dynamics. The model's estimates are compared with observations of the spread to determine appropriate trading decisions. They solve an optimal double-stopping problem to analyse the timing of entry and exit subject to transaction costs.
Most prominently, Ornstein-Uhlenbeck (OU) processes have been used to model spreads for pairs trading. For classical OU processes, which are driven by Brownian motion, closed-form solutions to the pairs trading problem were obtained in Leung and Li (Citation2015) and Lipton and López de Prado (Citation2020).
Lévy processes have been widely applied in finance to model price processes with jumps (Cont and Tankov Citation2004; Schoutens Citation2003), which leads us to model price spreads with jumps. These Lévy models often provide a better fit than models based on Brownian motion (Madan, Carr, and Chang Citation1998; Michaelsen and Szimayer Citation2018; Schoutens Citation2003), where the first two references focus on variance gamma-based models. Jumps can also arise from hard-to-borrow stocks (Avellaneda and Lipkin Citation2009) or illiquid stocks (Gardini, Sabino, and Sasso Citation2022). This motivates going beyond the classical OU processes to consider Lévy-driven Ornstein-Uhlenbeck processes (LDOUP) to model mean-reverting spreads with jumps in pairs trading.
LDOUPs have been applied to other areas of mathematical finance such as modelling stochastic volatility (Barndorff-Nielsen and Shephard Citation2001), energy prices and energy derivatives (Benth and Schmeck Citation2014; Cummins, Kiely, and Murphy Citation2018; Sabino Citation2020), credit risk (Cariboni and Schoutens Citation2009), among others. LDOUPs also have increased flexibility for capturing skewness, kurtosis, and dependence in the multivariate setting. Parametric estimation of LDOUPs using maximum likelihood has been considered in the univariate and multivariate cases by Valdivieso, Schoutens, and Tuerlinckx (Citation2009) and Lu (Citation2022), respectively, and these methods can be applied to fit LDOUPs to spreads. However, in the context of pairs trading, LDOUPs have been applied restricting the driving process to compound Poisson processes with double exponential jumps. This setup is used since Borovkov and Novikov (Citation2008) derived an analytic formula for the expected exit time which relies on the memorylessness property of the exponential jumps to deal with overshoots. Without this assumption, overshoots present a difficult technical hurdle to finding analytic formulas for the passage times of these processes in general, which requires Monte Carlo methods to overcome. Based on Borovkov and Novikov (Citation2008) and Wu, Zang, and Zhao (Citation2020) provide an analytic value function for pairs trading, while Endres and Stübinger (Citation2019) use the analytic formula of Borovkov and Novikov (Citation2008), while ignoring overshoots, to conduct an empirical study of optimal pairs trading.
In this paper, we discuss a framework for pairs trading using Lévy-driven Ornstein-Uhlenbeck processes to model the mean-reverting spread, which works with any LDOUP that can be simulated. Specifically, we focus on a variance gamma driving process, which is a time-changed Brownian motion and a pure-jump, infinite activity Lévy process with skewness and kurtosis parameters. By using this driving process, these properties extend to the LDOUP, allowing for more flexible models of the price spread than is available in the classical OU model, and in contrast to the finite activity processes considered previously. However, the generalization comes at the cost of not having analytic formulas. Hence, we develop a Monte Carlo method to evaluate the trading strategies and determine the optimal trading levels. In particular, we introduce an array of control variates to reduce the variance of the Monte Carlo estimator of the value function. We derive a formula for the variance reduction ratio when the control variate is used to estimate the mean and variance of the profit simultaneously, which extends the usual approach where only one parameter is estimated by control variates. Furthermore, in our numerical implementation, we examine how the parameters of the model affect the optimal trading levels and optimal expected profit in various scenarios. Specifically, we demonstrate numerically how skewness in the distribution of the spread leads to asymmetry in the optimal trading levels, how the optimal exit level can differ from the stationary mean when the process starts sufficiently far away from it and the discount rate is large, and it is otherwise difficult to find other situations where this occurs. And lastly, we demonstrate how the jumps can increase the optimal entry level and optimal expected profit.
We note that all the studies mentioned above focus on the trading performance of a single spread. The recent paper by Lee, Leung, and Ning (Citation2023) introduces a framework for trading multiple mean-reverting spreads simultaneously, where capital is dynamically allocated among different spreads based on their statistical characteristics. In this paper, we also consider the trading problem involving two mean-reverting spreads modelled by an LDOUP driven by a weak variance alpha-gamma process, which is a multivariate generalization of the variance gamma process introduced in Buchmann, Lu, and Madan (Citation2019). For bivariate pairs trading, we estimate the expected profit via Monte Carlo simulation and examine the effect of the correlation between spreads on the optimal trading levels and optimal expected profit. We demonstrate an example where the optimal strategy is to effectively pick the best spread mostly ignoring correlation, and an example where having low absolute correlation is more profitable when monitoring multiple spreads with marginal components that follow the same law.
The rest of the paper is structured as follows. In Section 2, we review Lévy-driven Ornstein-Uhlenbeck processes and required properties used in this study. The trading problem is formulated in Section 3. We discuss our Monte Carlo estimation framework in Section 4 and present the numerical results in Section 5. In Section 6, we examine the trading problem involving two mean-reverting spreads. Concluding remarks are provided in Section 7.
2. Lévy-Driven Ornstein-Uhlenbeck Process
Let denote an n-dimensional Lévy process with characteristic triplet
, where
,
is a covariance matrix and
is an n-dimensional Lévy measure. See Bertoin (Citation1996), Sato (Citation1999), and Schoutens (Citation2003) for references on Lévy processes.
A Lévy-driven Ornstein-Uhlenbeck process (LDOUP) is defined by the stochastic differential equation
(1)
(1)
where
is the background driving Lévy process (BDLP),
, and
is a random vector independent of
. Note that there is no loss in generality in using the drift term
instead of
for some
, since the stationary mean of
is controlled by
. Also, there is no loss in generality in using the BDLP
, where I is the identity function, instead of
, since any Lévy process
can be written in the form
, where
. However, the former is more convenient since it leads to a stationary distribution that does not depend on λ. The exposition on LDOUP here follows Lu (Citation2022), while some additional references for LDOUPs include Masuda (Citation2004), Sato and Yamazato (Citation1983), and Sato and Yamazato (Citation1985).
The solution of (Equation1(1)
(1) ) is
(2)
(2)
For
, at the observation time
, we have
The stochastic integral term is iid, and we let
be the random vector with this distribution, so it is interpreted as the innovation term, up to a factor
, of an AR(1) process. Specifically, we define
The random vector
is infinitely divisible, so it is determined by its characteristic exponent, which is given by
(3)
(3)
where
is the characteristic exponent of the BLDP
. Combining these results, the LDOUP can be written as
(4)
(4)
where
is iid with the distribution of
.
Next, we consider specific examples of LDOUP processes where the BDLP is a tractable pure-jump infinite activity Lévy process to model price spreads for pairs trading. We consider both the univariate and multivariate cases, where the BDLP is a variance gamma and a weak variance alpha-gamma process, respectively.
2.1. Univariate LDOUP Driven by a Variance Gamma Process
The variance gamma process was introduced in Madan and Seneta (Citation1990) and additional details can be found in Madan, Carr, and Chang (Citation1998). Let denote a gamma subordinator with shape a>0 and rate b>0, and
denote a Brownian motion with drift
and covariance matrix
. A Lévy process
is a variance gamma (VG) process if
where
and
are independent,
, and I is the identity function. The parameter
adds a drift.
We call the univariate LDOUP an
process if its BDLP is
.
2.2. Multivariate LDOUP Driven by a Weak Variance Alpha-Gamma Process
The weak variance alpha-gamma (WVAG) process was introduced in Buchmann, Lu, and Madan (Citation2019). Let , a>0,
,
,
and
. Let
and
. We define
as a weak variance alpha-gamma (WVAG) process if
(5)
(5)
where
and
,
, are independent. This formulation gives a direct method of simulating the WVAG process in terms of VG processes, and seeing that the process has common and idiosyncratic jumps.
The original definition of the WVAG process (with ),
(6)
(6)
where
,
an n-dimensional alpha-gamma subordinator, and ⊙ is the weak subordination operation, gives a multivariate time-change interpretation to the process, generalizing the univariate VG process. Indeed, the marginal components of the WVAG process are general univariate VG processes with
.
We call a multivariate LDOUP an OU-WVAG process if its BDLP is
.
Based on the moment formulas (see Michaelsen and Szimayer Citation2018), the parameters of the WVAG process can be interpreted as follows. The marginal parameters are kurtosis, skewness, variance, and location parameters, respectively, that affect the marginal component distribution, while
, are joint parameters. In particular, as
(equivalently, the VG parameter
in the kth component), the kth marginal component of the WVAG process converges in law to Brownian motion so the sample paths become closer to continuous.
2.3. Moment Formulas
For a random vector , denote the mean by
, and the kth central moment of
by
,
.
For a general BDLP , Lu (Citation2022, Lemma 1) gives formulas for the moments of
in terms of the moments of
. Combining this with (Equation2
(2)
(2) ) and conditional on
(or assuming it is constant), the moments of the LDOUP
are given by
The stationary distribution
of
is the distribution such that if
, then
for all
. Thus, the stationary mean, which is the mean of the stationary distribution, is
. This is the level that we expect the process to return to in pairs trading.
Now specializing to the case where , and using the moment formulas for the WVAG process in Michaelsen and Szimayer (Citation2018, Remark 4 and Appdendix A.1), we have
(7)
(7)
(8)
(8)
(9)
(9)
(10)
(10)
Furthermore,
. These formulas will be used for control variates in the Monte Carlo method. Note that (Equation7
(7)
(7) ) to (Equation9
(9)
(9) ) apply to OU-VG processes with
.
3. Pairs Trading Problem
Suppose the spread of a pair of assets or the price of a portfolio of assets is mean-reverting and follows a univariate LDOUP X.
Now we proceed to determine the levels at which trades should be entered or exited. Consider the following pairs trading strategy on the spread X: Enter a short position in X when it is above , and close the position by buying when it is below
, where
. Enter a long position when it is below
, and close the position by selling when it is above
. Fix a terminal time T>0, where the trade is closed by time T if it has not been closed already. Thus, d and c are the entry and exit levels relative to the mean reversion level
.
This trading strategy is depicted for a sample path of X in Figure . Note that the price at which the trade enters and exits is not the same as the entry and exit levels due to the presence of jumps. In this model when X is an OU-VG process, there is always some degree of overshoot.
Figure 1. For the spread process X (black line), a trade is entered when the price passes , whichever happens first (red lines), and exited when it passes
(blue line). The value of the spread at the entry (red point) and exit (blue point) times are shown. Here,
.
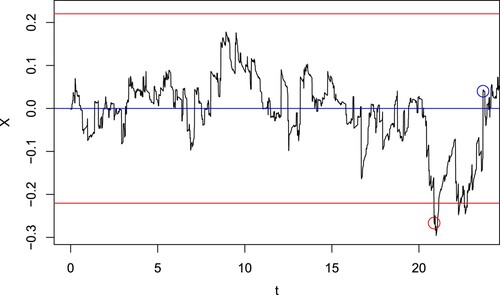
More generally, we can consider possibly different entry levels ,
from above and below
, and their respective exit levels
. These satisfy
.
The relevant passage times are
Let
be a discount rate, then P is the discounted profit over one trade cycle given by
(11)
(11)
For convenience, we will refer to this simply as the profit. The value function is
(12)
(12)
where
is a parameter which penalizes trading strategies with high variance. If
, the value function is the expected profit.
We want to find the optimal levels for the pairs trading strategy to maximize the value function, that is,
We develop a Monte Carlo approach to simulate sample paths of the LDOUP X, to estimate
on
, and in turn numerically solve the maximization problem for the optimal trading levels. Given the use of simulation, we also discuss control variates for variance reduction.
4. Monte Carlo Method
Let m be the number of Monte Carlo simulations. For a spread process following a univariate LDOUP X, suppose we have m simulations of with a small stepsize
. Then we can compute the random variable P, and hence obtain the Monte Carlo estimate of
and
to estimate the value function V in (Equation12
(12)
(12) ). The same sample paths are used for all evaluations of the same value function. While the Monte Carlo method presented here works for any LDOUP that can be fitted and simulated, we specifically focus on the OU-VG process.
4.1. Simulating the Spread
Let the spread process be . We assume that the parameters are known. For example, they may be estimated using maximum likelihood as in Valdivieso, Schoutens, and Tuerlinckx (Citation2009) and Lu (Citation2022).
It is possible to exactly simulate for the OU-VG process, and hence
by (Equation4
(4)
(4) ), using the method of Sabino (Citation2020) and Qu, Dassios, and Zhao (Citation2021). For
, define the random variable
, where
is gamma where the parameters are the shape and rate, respectively, and
is compound Poisson where the parameters are the rate and jump distribution, respectively. Here,
is the probability law of J such that
where the parameter is the rate, and
. Then
where
,
, and
4.2. Control Variates
Next, we use control variates to reduce the variance of the Monte Carlo estimators of the value function. We refer to Glasserman (Citation2003, Chapter 4) for the details of the method. Specifically, to estimate , the method of control variates defines the random variable
, where C is the control variate for which
has an analytic representation, and β is chosen to minimize
, resulting in an unbiased estimator with reduced variance. Since the true value of β is unknown, the control variate estimator
is the sample mean of
with β estimated by
, the least squares estimator (LSE) of the slope in a linear regression where C is the regressor and P is the response variable. Note that
is also the sample estimate of the true β.
This method can be extended to multiple control variates, and the control variate estimator is equivalent to the prediction of a linear regression. See Appendix for details.
We apply the control variate method to estimate both and
in the value function (Equation12
(12)
(12) ). Consider the control variates
, where
are equally spaced points on
. When estimating
, we include the additional control variates
. Note that
and
can be analytically computed using (Equation7
(7)
(7) ) and (Equation8
(8)
(8) ).
Further, we may want to consider the event of entering and exiting a trade, and the event of entering and not exiting over the observations as additional control variates to approximate the indicator variable appearing in the profit function (Equation11
(11)
(11) ). But the event that
passes some level cannot be computed analytically for use as a control variate. Instead, the probability of a related event using the iid sequence of innovations
,
can be. Specifically, this motivates the inclusion of two additional control variates
and
. Define A as the event that
“enters a trade” (even though there is no actual trading on this sequence) by passing the level
or
and then “exits the trade” by passing the level
or
, respectively.
The modified levels for are the levels such that
passes the entry levels
when
, and similarly for the exit levels. Further, B is the same as A except without exit. Thus, A and B are the events that
,
, enters and exits these modified levels, and enters and does not exit, respectively. Due to collinearity, the complementary event that the sequence does not enter is not included, and if p = 1, the event A, which has probability 0, is also not included. We have expressed this for symmetric levels
and
, but this can be modified in an obvious way for the asymmetric case.
Since ,
, are iid, we can compute the probabilities of A and B since we can compute
by applying the Fourier inversion to the characteristic function of
determined by (Equation3
(3)
(3) ). The Fourier inversion methodology is described in Michaelsen and Szimayer (Citation2018, Section 4.1).
4.3. Variance Reduction
Consider the two separate linear regression models,
(13)
(13)
where
and
are the vector of m simulated values of P and
, respectively. In this section only, we let
and
be the design matrices, including an intercept. As outlined in Section 4.2,
includes the control variates
,
,
,
, and
includes the control variates in
in addition to
,
. Since each simulated sample path of the LDOUP is independent, we have
, i = 1, 2 and
for some
covariance matrix
, where I is the identity matrix.
For each of the linear regression models, i = 1, 2, let be the mean vector of the control variates computed as outlined in Section 4.2, then the predictions
are
. As explained in Appendix, the control variate estimators of
and
are the predictions
and
, respectively. Thus, for each argument, the control variate estimator of the value function in (Equation12
(12)
(12) ) is
where
Let
be the sample mean of
respectively, then
is the corresponding Monte Carlo estimator of the value function.
Given that our approach involves parameters that are estimated by a function of two control variate estimators, rather than the usual situation of only one, we now derive the variance reduction factor in this context. For a large number of Monte Carlo simulations m, the asymptotic normality of the LSE gives approximately for some
and
. Using results on multivariate linear regression, and the law of total variance, noting that
and
are random, we have
where
denotes the rest of the matrix is completed by symmetry. By the plug-in principle, these parameters are estimated using
where
is estimated using
and
are the residuals from the linear regressions in (Equation13
(13)
(13) ),
for i = j = 1, and
otherwise.
Now since is a quadratic form in
, and
holds approximately for large m, by Rencher and Schaalje (Citation2008, Theorem 5.2c–d), the variance of the control variate estimator is
(14)
(14)
Then estimated variance
is obtained by replacing
and
with
and
, respectively. By the asymptotic normality of
, (Equation14
(14)
(14) ) is also used to compute
by replacing
and
with
and
, respectively, where
with the sample covariance
as its
-entry.
Thus, the estimated variance reduction factor of using control variates relative to Monte Carlo without control variates is
In the context of a single parameter estimated using control variates, while the true variance reduction factor using the true value of
is no greater than 1, when using LSE
instead, R>1 is possible. This topic is discussed in Glasserman (Citation2003, Section 4.1.3).
5. Numerical Implementation and Analysis
In this section, we implement the Monte Carlo method outlined above for various scenarios. The spread is simulated with stepsize
and terminal time T = 50. In all cases,
, and any changes to μ adjusts η accordingly to ensure that the stationary mean is
. Unless otherwise stated, the initial value is
,
, the discount rate is r = 0.01, and it is assumed for simplicity that the entry level
is symmetric and the exit level is fixed at
. Thus, we optimize for the entry level d. All results use m = 10, 000 Monte Carlo simulations.
5.1. Effect of Control Variates
Consider two examples using control variates.
Example 5.1
Suppose the spread X has parameters , and
. The number of time points p used in the control variate method can be chosen to obtain the optimal variance reduction factor, however, this also depends on the entry level d. We optimize this iteratively by using no control variates to optimize d, then use this value of d to optimize p with the resulting optimal value denoted
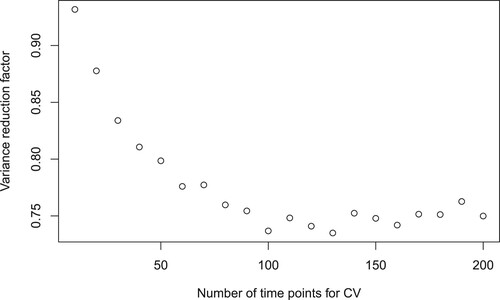
. Doing this, Figure shows that for d = 1.086, the optimal number of time points for the control variates is
when searching over
. This gives a moderate optimal variance reduction factor of
.
Figure 2. Estimated variance reduction factor R as a function of the number of time points for the control variates p. The parameters are ,
,
, r = 0.01.
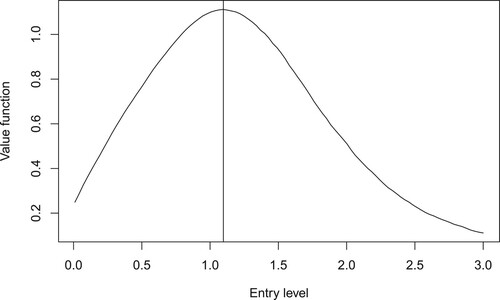
Using , Figure shows the estimate of the value function
, which has optimal entry level
. The control variate reduces
, however, it does not change the optimal entry level
in this example because the variability is already quite low, in fact, the coefficient of variation of
, the estimate of
conditional on
, is 0.0038 after control variates.
Figure 3. The estimate of the value function
and the optimal entry level
. The parameters are
,
,
, r = 0.01.
Different choices in the parameters result in different variance reductions. In Table , results are shown varying (which also affects η), and for the parameters, decreasing b>0 increases
, while decreasing
reduces and then increases
.
Table 1. For various values of , the optimal number of time points for the control variates
(searching over
) and the optimal variance reduction factor
are shown.
Consider the case shown in the second row of Table where and
. Surprisingly, for large γ, such as
, it is possible that the control variate method reduces the variance of the estimator of
with an estimated variance reduction factor 0.910, and
with estimated variance reduction factor 0.816, but increases the variance of the estimator of
with variance reduction factor 1.139. In comparison, when
, this does not occur, and those estimated variance reduction factors are 0.892, 0.793, 0.904, respectively.
Example 5.2
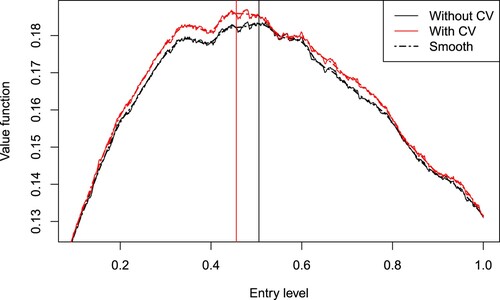
We use the same setup as Example 5.1, except X now has parameters . Since
, this process has little mean reversion, and is close in law to a variance gamma process, so the value function is estimated with a relatively large amount of simulation error as shown in Figure . To address this, a locally estimated scatterplot smoothing (loess) smoother is applied to the estimated value function before maximizing it. Then the optimal entry level is
without using control variates, and
using the optimal number of control variates, which is
. The optimal variance reduction factor is
and the coefficient of variation of
is 0.0281, which is consistent with the much larger variability of the estimated value function compared to Example 5.1, Figure . Unlike in Figure , using control variates here has an effect on the estimate of
, the size of this effect varies with the simulation. Note that
is the variance reduction of estimating
for fixed d using control variates, and the method is not designed to reduce the standard error of
, although reducing the former should be expected to reduce the latter. For these optimal values, only 63.91% of simulations resulted in a trade that is entered and exited before the terminal time due to the slow mean reversion, compared to 90.88% in Figure .
Figure 4. The estimate of the value function (solid lines) and the corresponding loess smooth (dashed lines) with (red lines) and without (black lines) control variates. The optimal entry level is
without using control variates, and
using the optimal number of control variates
. The parameters are
,
,
, r = 0.01.
5.2. Asymmetry of Optimal Trading Levels
From now on, we set and do not include control variates. In the previous examples, we fixed
for simplicity. The parameter μ controls the asymmetry of the stationary distribution Y of the LDOUP X. If
, then the stationary distribution is symmetric and hence the optimal levels are equal,
. However, under asymmetry, we may want to optimize both
and
separately.
Here, we consider the optimal level in four cases: from a large negative skew to no skew. The other parameters of X are . The results are shown in Table , where
is the skewness of the stationary distribution, which by (Equation9
(9)
(9) ), is
The results in Table show how
and
may differ due to skewness. For negatively skewed spreads, the trade is more likely to enter from the negative level, and so the positive level is slightly lower to compensate. Figures and show the sample paths of the spread when
(large negative skew) and
(no skew), respectively.
Figure 5. A sample path of the spread using the optimal entry levels in the first row of Table .
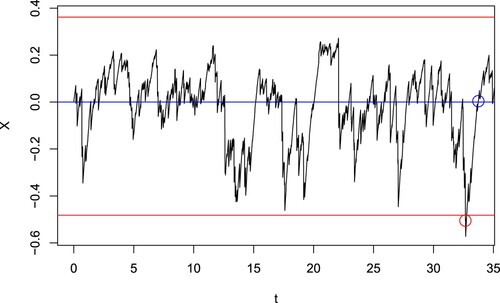
Table 2. For various value of μ, the optimal entry levels and
are shown.
In the classical OU spread model, which has no skew, Leung and Li (Citation2015) derive the optimal entry and exit levels with transaction costs, where the two levels can also be asymmetric.
5.3. Exit Level Different From the Mean
Recall that we set for simplicity. So far, we have set c = 0. However, it is possible to find examples where
is much greater than 0. Such a situation can occur when
and the discount rate r is very large. Let
and r = 1 while the other parameters are as before with
. We optimize c, d for 0<c<d, and find that the optimal exit level is
, while the optimal entry level
is any value
as shown in Figure , which plots the estimate of the value function
.
Figure 6. The estimate of the value function with entry level d and exit level c. The parameters are
,
,
, r = 1.
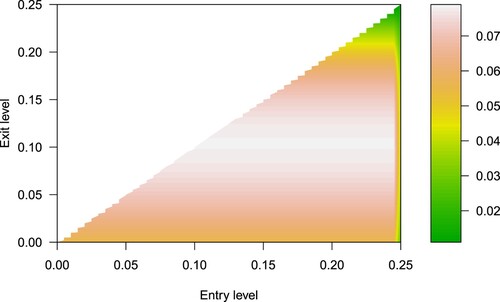
Thus, the pairs trading strategy is to enter the trade immediately, and because the large discount rate greatly reduces the profit if the trade is not exited quickly, the trade is exited at above the stationary mean
rather than waiting for it to fall to
.
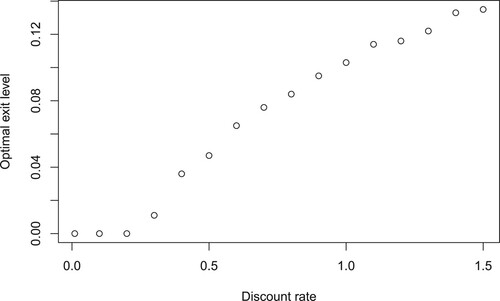
Figure shows how the optimal exit level changes for different values of the discount rate r. For the plotted values, the point at which
(to 3 decimal places) is r = 0.3. For all these plotted values of r, if the initial value is instead set to
, then the optimal exit level would be
. This demonstrates how having an initial value different from the stationary mean and a large discount rate can make the optimal exit level
different from 0. It is difficult to find other situations where this occurs, which suggests optimizing c may have little benefit beyond this, and fixing c = 0, which corresponds to exiting the trade when the spread passes
, simplifies the optimization.
Figure 7. The optimal exit level for various value of discount rate
. The other parameters are
,
,
.
5.4. Effect of Jumps
Now we consider the effect of the parameter b, which affects the jumps of the LDOUP X, on the optimal entry level . As before, let
. As
, the OU-VG process for the spread converges in law to a classical OU process driven by Brownian motion, and the sample paths are closer to continuous. As
, roughly speaking, the sample paths become more jumpy (specifically, for each t, the BDLP
converges in distribution to a constant while its kurtosis diverges). Define the overshoot for the entry level d as the random variable
Table shows the effect of the sample paths of the spread, roughly speaking, being very jumpy (b = 1), moderately jumpy (b = 5), and approximately continuous
. A plot of a sample path in each of these cases is given in Figures (a), and (b), respectively. The results show that the more jumpy the sample path, the higher the level at which the trade is entered to compensate for overshooting. When b = 1, the mean overshoot is relatively large (0.0640) compared to the optimal entry level
(0.246). This demonstrates the importance of accounting for jumps by using LDOUPs compared to the classical OU process. Both Figure and Table show that as the sample path becomes closer to continuous, the mean of the overshoots becomes smaller and the optimal expected profit
becomes close to
as expected, although they do not converge since r is nonzero. In this example,
increases as b decreases. Note that the stationary variance remains constant, so the increased profitability is not due to changes in the variance.
Figure 8. A sample path of the spread , where (a) b = 1 and (b) b = 100, using the optimal entry levels in the first and third row of Table .
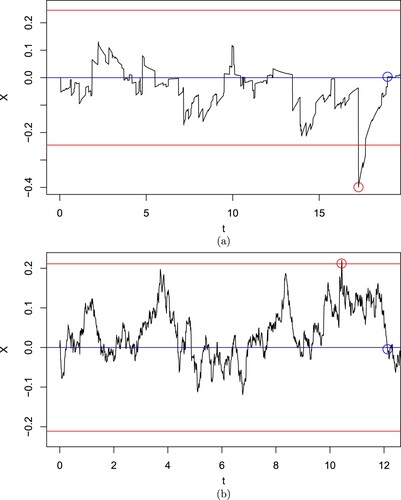
Table 3. For various values of b, the optimal entry level d, the estimate of the optimal expected profit, and overshoot statistics are shown.
6. Bivariate Pairs Trading
We now consider pairs trading in a bivariate setting, where the spread is a bivariate LDOUP with stationary mean
. While we focus on the 2-dimensional case, the concepts here can in principle be extended to the n-dimensional case.
6.1. Paris Trading Problem
While there are many ways to set up a pairs trading strategy on multiple spreads, we use the following setup to generalize the notion of one trade cycle used in the univariate setting. A trade is entered for the first time that either spread is above
or below
for k = 1, 2. If a trade on spread
is entered, then exit occurs when the spread passes
or
, respectively. When a trade is entered, no further trades can be initiated, even if the other spread later passes the entry level.
More generally, it is possible to have asymmetric entry and exit levels for both spreads, where ,
are the levels for entering a trade on spread
from the positive and negative sides, respectively, and similarly for the other entry and exit levels. For each spread k = 1, 2, there are 8 relevant passage times defined by
with
. However, we will not need to use this much generality in the examples below.
The nonzero probability of common jumps for the WVAG process used as the BDLP, and hence for , means that the event
also has nonzero probability, that is, both spreads can pass their corresponding entry levels simultaneously. In this case, we invest with 50% weight in each of the spreads. An alternative approach would be to invest fully in the spread furthest from the mean-reverting level. However, in the numerical examples we consider below, both approaches produce virtually the same results, since it is rare that both spreads pass the optimal entry levels simultaneously. Therefore, we will only consider the former approach.
Let ,
and
. The profit over one trade cycle is given by
where the weights are
and r is the discount rate.
The objective function is the value function
We want to find the optimal level
for the pairs trading strategy to maximize the value function, that is
6.2. Simulating the Spread
Now we specifically let the spread be . To simulate
, we use the Euler scheme approximation in Lu (Citation2022, Sections 4.2 and 5.1), which is based on taking a stochastic integral representation of
, which can be approximately simulated whenever
can be simulated, in this case using (Equation5
(5)
(5) ). This is in contrast to the univariate OU-VG process which was simulated exactly in Section 4 with a method that has no multivariate generalization. We now determine the optimal trading levels using Monte Carlo methods.
6.3. Numerical Implementation and Analysis
We consider two examples of bivariate pairs trading on the spread simulated using the approximate method above with stepsizes
and
, and terminal time T = 50. In all cases, the initial value is
,
, we do not consider control variates, and
so that
. Unless stated otherwise, we assume for simplicity that the entry levels are symmetric with
, k = 1, 2, and the exit levels are
, so we optimize the value function over
. We use m = 10,000 Monte Carlo simulations.
In our numerical examples, we explore the effect of correlation on the optimal entry level and the optimal expected profit. In the first example, the correlation has little effect, whereas in the second example, it has a larger effect. The correlation of the components of is in part controlled by the correlation parameter
. However, note that ρ is the correlation of the Brownian motion subordinate in (Equation6
(6)
(6) ), and is related to the correlation of the components of
by
(15)
(15)
for all t>0, due to (Equation10
(10)
(10) ) and (Equation8
(8)
(8) ).
Example 6.1
Let
(16)
(16)
and r = 0.01.
Table shows the optimal entry levels and
, the optimal expected profit
, and the estimated probability of which spread is traded, and each of these quantities is approximately equal across the values of ρ considered.
Table 4. For various values of ρ, the optimal entry levels , the estimate
of the optimal expected profit, and the estimated probability of which spread
is traded are shown.
When pairs trading on the univariate spreads and
, the optimal expected profit is 0.227 (see the second row of Table ) and 0.331 respectively, while it is 0.334–0.336 in this bivariate pairs trading example. Bivariate pairs trading is more profitable than univariate pairs trading on either spread, although it is approximately as profitable as trading only
since this accounts for 79–84% of trades. The optimal expected profit of the bivariate pairs trade must be at least that of the best univariate pairs trade, as the latter strategy can be implemented within bivariate pairs trading by setting the other spread to have an arbitrarily large optimal entry level. Indeed, this is happening to some extent here as the optimal entry level of the spread
has increased from 0.220 in the univariate case to 0.305–0.318 in the bivariate case. Thus, this decreases the probability of only
entering a trade from 96.79% to 11–16% in Table (the latter accounts for the probability that a trade on
fails to be entered because a trade on
is entered first, while the former is univariate pairs trading and does not include this). So in this example, the method has essentially identified that
is the more profitable spread, regardless of correlation, and has accordingly increased the optimal entry level of
to reduce the instances where it is traded.
Example 6.2
Now we consider an example where different values of the correlation parameter ρ can have a larger effect on the optimal entry level and optimal expected profit. Suppose the parameters are now
(17)
(17)
and r = 1.
Recall the parameter boundary . In Example 6.1, the upper bound of
as a function of
is 0.395 by (Equation15
(15)
(15) ). The upper bound converges to 1 as
while keeping
constant for all k. Since
here, this example represents monitoring two spreads
that are equal in law for each fixed ρ, with
and
converging pathwisely as
, since in the limit,
for all t with
. Also, appealing to the symmetry of
for each fixed t, all components of the optimal entry levels
are equal to
, say. Thus, we optimize over d, the symmetric entry level for all components.
Table shows the results for this example over different values of ρ. Here, the optimal expected profit increases from 0.032 to 0.040 as ρ decreases from 0.99 to 0, this represents a 26% increase in the optimal expected profit. The case where
is approximately the case of univariate pairs trading, which occurs in the limit as
. Since
is larger when ρ is much less than 1, the results demonstrate a situation where bivariate pairs trading is much more profitable than what is effectively pairs trading on a single spread, and where correlation has a larger effect.
Table 5. For various value of ρ, the optimal entry level and the estimate
of the optimal expected profit.
These results are consistent with intuition. Monitoring multiple spreads of the same law presents additional opportunities to enter into the trade sooner, which increases the optimal expected profit relative to monitoring only one spread, while having a larger discount rate r substantially rewards entering the trade sooner. Thus, in this example, using bivariate pairs trading by choosing pairs that are uncorrelated (as represented by the case) is much more profitable than either univariate pairs trading or choosing highly correlated spreads (both represented by the
case).
7. Conclusions
We have presented a Monte Carlo framework for evaluating pairs trading strategies where the mean-reverting spread follows an LDOUP. We numerically demonstrated how different parameters affect the optimal trading level and value function and capture various aspects of the trading strategy. The framework is flexible to accommodate a wide class of LDOUPs, provided that they can be fitted and simulated, as well as different ways of trading the spread. For instance, methods for fitting and simulating univariate LDOUPs with tempered stable and normal inverse Gaussian stationary distributions are provided in Valdivieso, Schoutens, and Tuerlinckx (Citation2009). Our proposed control variates for variance reduction, can also be applied to similar problems.
For future research, one useful direction is to incorporate transaction costs into the trading problems. To that end, Do and Faff (Citation2012) examine the profitability of pairs trading accounting for transaction costs, and Leung and Li (Citation2015) analyse an optimal stopping approach to pairs trading with transaction costs and stop loss, and this work could be extended to spreads following LDOUPs. Another possibility is to consider large jumps in stock prices that trigger immediate liquidation due to the need to return the stocks. This can also be incorporated into the stochastic model and value function. Additional extensions of our framework include portfolio optimization problems arising from trading multiple spreads and spread selection based on statistical and other characteristics. Theoretical results on pairs trading under LDOUP models are very limited, and additional work in this direction would be useful. However with LDOUPs, these problems are complicated and unlikely to admit analytic solutions, so simulation-based approaches can be both mathematically interesting and practically useful.
Acknowledgements
Kevin Lu thanks the Department of Applied Mathematics at the University of Washington, where the substantial majority of his work on this article was completed. We thank an anonymous referee for the useful comments which have helped improve the paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Avellaneda, M., and J.-H. Lee. 2010. “Statistical Arbitrage in the US Equities Market.” Quantitative Finance 10 (7): 761–782. https://doi.org/10.1080/14697680903124632.
- Avellaneda, M., and M. Lipkin. 2009. “A Dynamic Model for Hard-to-Borrow Stocks.” Risk 22 (6): 92–97.
- Barndorff-Nielsen, O. E., and N. Shephard. 2001. “Non-Gaussian Ornstein-Uhlenbeck-Based Models and Some of Their Uses in Financial Economics.” Journal of the Royal Statistical Society: Series B (Statistical Methodology) 63 (2): 167–241. https://doi.org/10.1111/1467-9868.00282.
- Benth, F. E., and M. D. Schmeck. 2014. “Pricing Futures and Options in Electricity Markets.” In The Interrelationship Between Financial and Energy Markets, edited by S. Ramos and H. Veiga, 233–260. Berlin-Verlag: Springer.
- Bertoin, J. 1996. Lévy Processes. Cambridge: Cambridge University Press.
- Borovkov, K., and A. Novikov. 2008. “On Exit Times of Lévy-Driven Ornstein-Uhlenbeck Processes.” Statistics and Probability Letters 78 (12): 1517–1525. https://doi.org/10.1016/j.spl.2008.01.017.
- Brennan, M. J., and E. S. Schwartz. 1990. “Arbitrage in Stock Index Futures.” Journal of Business 63 (1): S7–S31. https://doi.org/10.1086/jb.1990.63.issue-S1.
- Buchmann, B., K. W. Lu, and D. B. Madan. 2019. “Weak Subordination of Multivariate Lévy Processes and Variance Generalised Gamma Convolutions.” Bernoulli 25 (1): 742–770. https://doi.org/10.3150/17-BEJ1004.
- Cariboni, J., and W. Schoutens. 2009. “Jumps in Intensity Models: Investigating the Performance of Ornstein-Uhlenbeck Processes in Credit Risk Modeling.” Metrika 69:73–198. https://doi.org/10.1007/s00184-008-0213-4.
- Cont, R., and P. Tankov. 2004. Financial Modelling with Jump Processes. Boca Raton: Chapman & Hall/CRC.
- Cummins, M., G. Kiely, and B. Murphy. 2018. “Gas Storage Valuation Under Multifactor Lévy Processes.” Journal of Banking and Finance 95:167–184. https://doi.org/10.1016/j.jbankfin.2018.02.012.
- Dai, M., Y. Zhong, and Y. K. Kwok. 2011. “Optimal Arbitrage Strategies on Stock Index Futures Under Position Limits.” Journal of Futures Markets 31 (4): 394–406. https://doi.org/10.1002/fut.v31.4.
- Do, B., and R. Faff. 2012. “Are Pairs Trading Profits Robust to Trading Costs?” Journal of Financial Research 35 (2): 261–287. https://doi.org/10.1111/jfir.2012.35.issue-2.
- Elliott, R., Van Der Hoek J., and W. Malcolm. 2005. “Pairs Trading.” Quantitative Finance 5 (3): 271–276. https://doi.org/10.1080/14697680500149370.
- Endres, S., and Stübinger J.. 2019. “Optimal Trading Strategies for Lévy-Driven Ornstein-Uhlenbeck Processes.” Applied Economics 51 (29): 3153–3169. https://doi.org/10.1080/00036846.2019.1566688.
- Gardini, M., P. Sabino, and E. Sasso. 2022. “The Variance Gamma++ Process and Applications to Energy Markets.” Applied Stochastic Models in Business and Industry 38 (2): 391–418. https://doi.org/10.1002/asmb.v38.2.
- Gatev, E., W. N. Goetzmann, and K. G. Rouwenhorst. 2006. “Pairs Trading: Performance of a Relative-Value Arbitrage Rule.” Review of Financial Studies 19 (3): 797–827. https://doi.org/10.1093/rfs/hhj020.
- Glasserman, P. 2003. Monte Carlo Methods in Financial Engineering. New York: Springer.
- Huck, N., and K. Afawubo. 2015. “Pairs Trading and Selection Methods: Is Cointegration Superior?” Applied Economics 47 (6): 599–613. https://doi.org/10.1080/00036846.2014.975417.
- Kanamura, T., S. Rachev, and F. Fabozzi. 2010. “A Profit Model for Spread Trading with an Application to Energy Futures.” The Journal of Trading 5 (1): 48–62. https://doi.org/10.3905/JOT.2010.5.1.048.
- Lee, K., T. Leung, and B. Ning. 2023. “A Diversification Framework for Multiple Pairs Trading Strategies.” Risks 11 (5). https://doi.org/10.3390/risks11050093.
- Leung, T., and X. Li. 2015. “Optimal Mean Reversion Trading with Transaction Costs and Stop-Loss Exit.” International Journal of Theoretical and Applied Finance 18 (03): 1550020. https://doi.org/10.1142/S021902491550020X.
- Leung, T., and X. Li 2016. Optimal Mean Reversion Trading: Mathematical Analysis and Practical Applications. Modern Trends in Financial Engineering, World Scientific Publishing Company.
- Leung, T., and H. Nguyen. 2019. “Constructing Cointegrated Cryptocurrency Portfolios for Statistical Arbitrage.” Studies in Economics and Finance 36 (3): 581–599. https://doi.org/10.1108/SEF-08-2018-0264.
- Lipton, A., and López de Prado M.. 2020. “A Closed-Form Solution for Optimal Ornstein-Uhlenbeck Driven Trading Strategies.” International Journal of Theoretical and Applied Finance 23 (8): 2050056. https://doi.org/10.1142/S0219024920500569.
- Lu, K. W. 2022. “Calibration for Multivariate Lévy-Driven Ornstein-Uhlenbeck Processes with Applications to Weak Subordination.” Statistical Inference for Stochastic Processes 25 (2): 365–396. https://doi.org/10.1007/s11203-021-09254-4.
- Madan, D. B., P. P. Carr, and E. C. Chang. 1998. “The Variance Gamma Process and Option Pricing.” European Finance Review 2 (1): 79–105. https://doi.org/10.1023/A:1009703431535.
- Madan, D. B., and E. Seneta. 1990. “The Variance Gamma (v.g.) Model for Share Market Returns.” The Journal of Business 63 (4): 511–524. https://doi.org/10.1086/jb.1990.63.issue-4.
- Masuda, H. 2004. “On Multidimensional Ornstein-Uhlenbeck Processes Driven by a General Lévy Process.” Bernoulli 310 (1): 97–120.
- Michaelsen, M., and A. Szimayer. 2018. “Marginal Consistent Dependence Modeling Using Weak Subordination for Brownian Motions.” Quantitative Finance 18 (11): 1909–1925. https://doi.org/10.1080/14697688.2018.1439182.
- Nelson, B. L. 1990. “Control Variate Remedies.” Operations Research 38 (6): 974–992. https://doi.org/10.1287/opre.38.6.974.
- Qu, Y., A. Dassios, and H. Zhao. 2021. “Exact Simulation of Gamma-Driven Ornstein–Uhlenbeck Processes with Finite and Infinite Activity Jumps.” Journal of the Operational Research Society 72 (2): 471–484. https://doi.org/10.1080/01605682.2019.1657368.
- Rencher, A. C., and G. B. Schaalje. 2008. Linear Models in Statistics. Hoboken: John Wiley & Sons, Inc.
- Sabino, P. 2020. “Exact Simulation of Variance Gamma-Related OU Processes: Application to the Pricing of Energy Derivatives.” Applied Mathematical Finance 27 (3): 207–227. https://doi.org/10.1080/1350486X.2020.1813040.
- Sato, K. 1999. Lévy Processes and Infinitely Divisible Distributions. Cambridge: Cambridge University Press.
- Sato, K., and M. Yamazato. 1983. “Stationary Processes of Ornstein-Uhlenbeck Type.” In Probability Theory and Mathematical Statistics, edited by K. Itô and J. V. Prohorov, 541–551. Berlin: Springer.
- Sato, K., and M. Yamazato. 1985. “Completely Operator-Selfdecomposable Distributions and Operator-Stable Distributions.” Nagoya Mathematical Journal 97:71–94. https://doi.org/10.1017/S0027763000021267.
- Schoutens, W. 2003. Lévy Processes in Finance: Pricing Financial Derivatives. East Sussex: John Wiley & Sons Ltd.
- Valdivieso, L., W. Schoutens, and F. Tuerlinckx. 2009. “Maximum Likelihood Estimation in Processes of Ornstein-Uhlenbeck Type.” Statistical Inference for Stochastic Processes 12 (1): 1–19. https://doi.org/10.1007/s11203-008-9021-8.
- Wu, L., X. Zang, and H. Zhao. 2020. “Analytic Value Function for a Pairs Trading Strategy with a Lévy-Driven Ornstein-Uhlenbeck Process.” Quantitative Finance 20 (8): 285–1306. https://doi.org/10.1080/14697688.2020.1736613.
Appendix. Equivalence of control variates and linear regression
Suppose we have multiple control variate to estimate
, where
is jointly simulated as we want the control variates to be correlated with P. As explained in Glasserman (Citation2003, Section 4.1.2), the control variate estimator is
where
is the vector of m simulated values of P,
is its sample mean,
are the vectors of m simulated values of
, respectively,
is the vector of the sample means of
,
,
,
with the sample covariance
as its
-entry, and
with the sample covariance
as its ith entry. This generalizes the method of Section 4.2.
Consider the linear regression model , where
is the design matrix, which includes an intercept and the control variates
, and
with LSE
. The prediction of this linear regression at the point
is
where the second equality follows from the centred form of linear regression by Rencher and Schaalje (Citation2008, pg 156, Equations (7.36), (7.46)). This reference also provides that
, where
.
Thus, the control variate estimator is the prediction of this linear regression. This fact is well-known and mentioned in Glasserman (Citation2003, Section 4.1.1) for a single control variate, and it is unsurprising that it is also true for multiple control variates. Nelson (Citation1990) gives a different but equivalent statement where the regressors are
.