
Abstract
Background
AL amyloidosis (AL) results from the misfolding of immunoglobulin light chains (IG LCs). Aim of this study was to comprehensively analyse kappa LC sequences from AL patients in comparison with multiple myeloma (MM).
Objective
We analysed IGKV/IGKJ usage and associated organ tropism and IGKV1/D-33 in terms of mutational analysis and theoretical biochemical properties.
Material and Methods
cDNA and bulk RNA sequencing of the LCs of AL and MM patients.
Results
We studied 41 AL and 83 MM patients showing that IGKV1 was most expressed among kappa AL and MM, with higher frequency in AL (80% vs. 53%, p = .002). IGKV3 was underrepresented in AL (10% vs. 30%, p = .014). IGKJ2 was more commonly used in AL than in MM (39% vs. 29%). Patients with IGKV1/D-33 were associated with heart involvement (75%, p = .024). IGKV1/D-33-segments of AL had a higher mutation count (AL = 12.0 vs. MM = 10.0). FR3 and CDR3 were most frequently mutated in both, with a median mutation count in FR3 being the highest (AL = 4.0; MM = 3.5) and one mutation hotspot (FR3 (83I)) for IGKV1/D-33/IGKJ2 was associated with cardiac involvement.
Conclusion
This study confirmed that germline usage has an influence on AL amyloidosis risk and organ involvement.
Introduction
AL amyloidosis (AL) is caused by monoclonal plasma cells that produce immunoglobulin light chains (IG LCs), which misfold and deposit in form of amyloid fibrils in the extracellular matrix of different organs [Citation1]. Heart and kidney are the most commonly affected organs. However, other organs, such as the liver, gastrointestinal tract and nervous system can be affected as well [Citation2]. Serious consequences of the fibril deposition are – among others and depending on the affected organ – heart failure, nephrotic syndrome, hepatomegaly with cholestasis, peripheral neuropathy and gastrointestinal mobility alterations. Especially advanced heart involvement is responsible for the very short median survival rate of about seven months after diagnosis. This is mainly attributed to the fact that patients are often not diagnosed until a late/advanced stage of disease since the first symptoms are often unspecific [Citation3].
To date, only little is known about why and how the LCs of AL patients form amyloid deposits in-vivo and why free LCs in other plasma cell dyscrasias, e.g. in multiple myeloma (MM), do not. Immunoglobulins are highly variable in their primary structure. This variability originates from the high germline genetic variability and complex somatic recombination processes that combine the variables (V) and the joining segments (J) of antibodies (V/J recombination) [Citation4]. Somatic hypermutations introduce point mutations preferentially into the variable regions of IG genes, thereby increasing the Ig diversity even further [Citation5]. There are two different types of IG LCs – kappa and lambda [Citation6] – and in healthy individuals and in MM patients the kappa LCs predominate with a 2:1 ratio. Interestingly, in AL the kappa to lambda LC ratio is 1:3 [Citation7]. A complete antibody results from the linkage of two heavy chains (HCs) and two LCs, but in AL as well as in MM, unbound/free LCs also occur in the blood.
Aim of this study was a detailed sequence analysis of the immunoglobulin kappa (IGK) family usage combined with an in silico biochemical characterisation of the less common kappa AL in comparison to MM. We investigated three clinically distinct kappa AL subgroups with dominant heart (AL_H), dominant kidney (AL_K), or diverse organ involvement (AL_D) and compare them with the LC of MM patients. We analysed the complete kappa IGKV-IGKJ-IGKC assembly of AL patients and MM patients and performed a detailed analysis of the most common IGKV AL-subfamily – IGKV/1D-33.
Materials and methods
AL amyloidosis cohort
This study included 41 AL amyloidosis patients from the Amyloidosis Centre of the University Hospital Heidelberg (sample collection from January 2019 to May 2022) and was approved by the Ethics Committee of the University Heidelberg (S-123/2006, last time renewed December 7, 2021) following the Helsinki guidelines for research of human subjects. All patients provided written informed consent for the usage and analysis of their biomaterials and clinical data. Clinical data were collected based on the medical patients report. 36 patients underwent bone marrow (BM) aspiration at the time of diagnosis and five patients at the time of relapse. We defined patients having dominant heart involvement (AL_H) or dominant kidney involvement (AL_K). The remaining patients were classified as diverse (AL_D).
Multiple myeloma cohort
A total of 83 newly diagnosed MM patients fulfilling the International myeloma Working Group (IMWG) criteria for treatment and participating in the GMMG-HD6 clinical trial (Eudra CT No.: 2014-003079-40, start date: 2015-06-16) [Citation8] were studied. This study was performed in accordance with the Declaration of Helsinki and the European Clinical Trial Directive (2005) and had been approved by the local ethics committees of all participating institutions. All patients provided written informed consent for the usage and analysis of their biomaterials and clinical data. In this trial, simultaneous occurrence of AL at the time of study inclusion and intermediate occurrence (mean observation period 49.8 months) were defined as exclusion criteria. Therefore, two patients were excluded at the time of study inclusion, and one patient was excluded from the study during the study period [Citation9, Citation10].
Sequencing
For AL sequence analysis, BM aspirate was collected and CD138-positive cells were extracted using magnetic beads-based positive selection (STEM-CELL Technologies, Vancouver Canada). RNA isolation and reverse transcriptase were done as previously described [Citation11, Citation12]. AL sequences were generated by Sanger Sequencing (Eurofins/GATC). For this purpose, LCs were amplified according to the following protocol [Citation11, Citation13] and kappa-specific primer were used (SI Table 1). MM cells were also enriched by magnetic beads-based positive selection (Milteny) and RNA was isolated using the same methods (Allprep kit, Qiagen, Hilden, Germany) used for AL cells. MM sequences were generated by bulk RNA-sequencing. Sequencing libraries were prepared using the Illumina TruSeq stranded mRNA (San Diego, USA) kit. Sequencing was performed on the Illumina NovaSeq 6000 PE 100 S1 platform. For each sample, MIXCR (version 3.0.13) was run in the “analyze shotgun” mode by using the FASTQ-files as input. The following parameters: “–species hs; –starting material rna; –receptor-type bcr; –contig-assembly and –only-productive” were specified to extract the full sequences of the IG kappa receptor [Citation14]. Sequences from the IG lambda or heavy chain receptor were not considered in this study. From the list of clonal sequences, the IG kappa sequences with the most assigned counts was defined as clonal sequence.
Table 1. Characteristics of 41 AL amyloidosis and 83 multiple myeloma patients.
Sequence alignment and germline usage
Ab1-files from forward and reverse Sanger sequencing were checked for inconsistencies using MEGA and sequence ambiguities, which means heterozygous signals without a clear dominant major signal, were defined according to the IUB code. For assignment of the IGKV- and IGKJ-gene families, VBase2 [Citation15] was used. Translation of the nucleotide to an amino acid (AA) sequence was done with Expasy [Citation16] and to confirm IGKV-and IGKJ-gene families Ensembl BLAST [Citation17] was used. In case of inconsistent results within the family assignment, the sequence was defined as non-evaluable. For mutation analysis of the IGKV-segment, the Vbase2 reference and the corresponding Ensembl references were used. IMGT references were used for the IGKJ-segment [Citation18]. For the IGLC-segment, the Ensembl reference was used. Because of the undefined AA in the first position of the IGKC reference, the UniProt reference (P01834) was used at this point [Citation19]. The complementary-determining regions (CDRs) and the framework regions (FRs) were aligned according to Kabat using abYsis [Citation20].
Verification bulk RNA-sequencing data
Because the sequences of both cohorts were generated with different methods, random samples of all five main IGKV-family-members of the MM sequences were verified with the protocol used for the AL sequences (SI Figure 1).
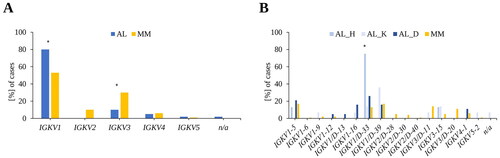
Figure 1. Variable region gene usage in AL amyloidosis and multiple myeloma patients. (A) IGKV-family usage in AL and MM. (B) IGKV-subgroups in AL (organ tropism) and MM. AL: AL amyloidosis; MM: multiple myeloma; AL, n = 41; MM, n = 83, AL_H: AL patients with dominant heart involvement; AL_K: AL patients with dominant kidney involvement; AL_D: AL patients with diverse organ involvement; AL_H, n = 8; AL_K, n = 14; AL_D, n = 19.
Mutation-analysis, amino acid composition, isoelectric point and potential N-glycosylation site
In order to create comparability despite the varying sequence lengths resulting from the different sequencing methods, the AL and the MM sequences were shortened to the same length at the N- and C-terminus. At ambiguous positions, the AA of the reference was assumed. This affected only one AL sequence at two positions; therefore, a bias and influence on the following analysis could be excluded. We defined positions as mutation hotspots when they were mutated to or more than 50% compared to the reference sequence. The median mutation count was calculated using only the mutated sequence regions or segments. To evaluate the isoelectric point (pI), the Expasy Tool: Compute pI/MW [Citation21] was used. The AA composition was calculated with the ProtParam-Tool from Expasy [Citation21]. The analysis of N-glycosylation was done with the bioinformatic tool NetNGlyc 1.0 (https://services.healthtech.dtu.dk/service.php?NetNGlyc-1.0) with default settings N-Xaa-S/T [Citation22]. We compared the whole AL cohort with the MM patients; moreover, we investigated the AL patients with respect to the presence or absence of a HC of the antibody in the serum. For complete sequence alignment, see SI Figure 2.
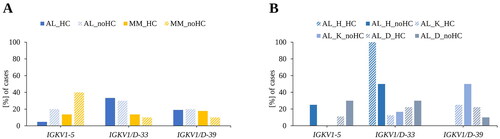
Figure 2. Influence of the presence of a heavy chain in serum on the most frequent IGKV-subgroups. (A) Comparison of the most abundant IGKV-subgroups with respect to a heavy chain in serum in AL and MM. (B) Influence of organ tropism on the expression of the most abundant IGKV-subgroups with respect to a heavy chain in serum. AL: AL amyloidosis; MM: multiple myeloma; AL, n = 41; MM, n = 83. HC: heavy chain in serum, no_HC: no heavy chain in serum; AL_HC n = 21; AL_no HC n = 20; MM_HC n = 73; MM_noHC n = 10. AL_H = AL patients with dominant heart involvement; AL_K = AL patients with dominant kidney involvement; AL_D = diverse AL patients; AL_H n = 8; AL_K n = 14; AL_D n = 19.
Statistics
Statistical analysis was carried out using IBM SPSS Statistics, version 29.0.0.0. Association of family usage, organ tropism and biochemical properties were tested for statistical significance. Data were initially tested for normal distribution using the Shapiro–Wilk test. T-test was applied in case of normal distribution, otherwise non-parametric Mann–Whitney U test was used. For nominal data testing Fisher’s exact test was used. All p values presented are two-sided and a p values ≤ .05 were considered to be significant and indicated at appropriate position. Multiple test correction was done. For data visualization, R/R-studio with ggplot packages was used.
Results
Patients and clinical data
The clinical characteristics of the four patient groups, AL patients with dominant heart involvement (AL_H), dominant kidney involvement (AL_K), AL patients with other, diverse organ involvement (AL_D) and MM patients are shown in . No differences in the median age between the different patient groups were noted. Patients with dominant kidney involvement presented a lower dFLC compared with the other groups, as expected [Citation23].
Family and germline usage
Our data indicate that members of the IGKV1-family are frequent in AL and MM but in AL the frequency was higher (AL: 80%, MM: 53%, p = .002) (). IGKV2 could only be detected in MM (10%). In AL, IGKV3 was underrepresented compared to MM (AL: 10%, MM: 30%, p = .014), most notably IGKV3-11 (AL: 2%, MM: 14%) and IGKV3/D-20 (AL: 0%, MM 11%, p = .030) (SI Figure 3). Five percent of the sequences from patients with AL were assigned to IGKV4 and 6% with MM. IGKV5 was detected in 2% of the AL cases and in 1% of the MM. In one (2%) of the 41 AL patients, no clear assignment of the IGKV-gene family was possible and defined as non-evaluable.
Regarding organ tropism in AL, differences in the IGKV1-subgroups could be determined (). For instance, IGKV1/D-33 was mainly detected in AL patients associated with dominant heart involvement (6/8, 75%, p = .024), whereas IGKV1/D-39 was found more frequently in patients with dominant kidney involvement (5/14, 36%). And three of the AL patients with IGKV1/D-33 and heart involvement were also diagnosed with a concomitant MM. Analysing the AL patients with diverse organ involvement, no clear main representative of the IGKV1-subgroup could be detected. IGKV1-16 could only be detected in AL (10%, p = .010, SI Figure 3) with one patient with dominant kidney involvement and three AL-diverse patients. Considering IGKV3, IGKV3/D-11 could be detected in 7% (1/14) of AL patients with dominant kidney involvement and 14% of the MM patients and IGKV3/D-20 could only detected in MM (11%). 11% (2/19) of the AL patients with diverse organ involvement had IGKV4-1, which was found in 6% of the MM patients. IGKV5-2 was assigned in 7% (1/14) of the AL patients with dominant kidney involvement and in 1% of the MM patients.
Figure 3. Comparison of the amino acid amount between AL amyloidosis and multiple myeloma sequences. (A) Comparison of AL and MM assigned to IGKV1/D-33, AL n = 13, MM n = 11. (B) Stratification in the presence or absence of a heavy chain in serum, AL_HC n = 7, AL_noHC = 6, MM_HC = 10, MM_noHC = 1. AL: AL amyloidosis; MM: multiple myeloma; HC: heavy chain in serum; noHC: no heavy chain in serum.
Kappa AL (in comparison to lambda) was reported to be related to liver involvement [Citation24]. Therefore, we also examined AL patients and liver involvement with respect to their IGKV assignment separately (SI Table 2). In our cohort of 41 AL patients, 11 had liver involvement, nine of those were in the AL diverse group. Here, we observed a trend towards IGKV1-16 (27% vs. 3%). Furthermore, IGKV1-12 and IGKV1/D-13 were only detected in AL patients with liver involvement (9%). IGKV1-5 was only detected in AL patients without liver involvement (17%).
Table 2. Analysis of the IGKJ-usage in AL amyloidosis and multiple myeloma.
We also examined the influence of the presence of a HC in serum on IGKV usage of the most common subgroups in AL (). Twenty of the AL patients had no HC (vs. 21) while ten of the MM patients had none (vs. 73). Differences for IGKV1-5 could be noticed. In AL with IGKV1-5, the percentage of patients without a detectable HC (no_HC) was four times higher than the patients with a detectable HC (AL_noHC= 20%, AL_HC= 5%). For MM, a threefold difference was found (MM_noHC= 40%, MM_HC= 14%). The difference in AL between HC and no_HC was based on the patients with dominant heart involvement and the diverse AL patients ().
We further analysed the IGKJ germline usage () in all patients. Overall, IGKJ2 was most frequently observed in the AL cohort (39%), whereas in MM both IGKJ2 (29%) and IGKJ1 (30%) were highly represented. In addition, the two diseases might also differ in the expression of IGKJ3 and IGKJ5. The expression of IGKJ3 (13%) was higher in MM than in the AL cohort (5%). IGKJ5 showed a twofold higher frequency in AL (10%) than in MM (5%). Regarding organ involvement in AL, dominant heart involvement was mainly related to IGKJ2 (5/8, 63%) whereas IGKJ1, IGKJ2 and IGKJ4 were equally represented (4/14, 29%) in patients with dominant kidney involvement.
Analysis of the linkage between IGKV1 subgroups and IGKJ (SI Table 3) showed that the most prominent IGKV1 representative in AL, specifically IGKV1/D-33, was most frequently combined to IGKJ2 (7/13, 54%), with two patients having AL and concomitant MM. In MM, the top IGKV1 members, herein IGKV1-5 (7/14, 50%) and IGKV1/D-39 (5/14, 36%), were also most frequently associated with IGKJ2. IGKV1/D-33 is linked equally frequent to IGKJ2 (4/11, 36%) and IGKJ4 (4/11, 36%) in MM. For the remaining IGKV1 subgroups, the sample number was too small to make conclusions about the preferred association between IGKV1 and IGKJ.
Table 3. Median mutation count and mutation frequency of IGKV1/D-33 sequences.
Analysis of IGKV1/D-33 – mutations distribution, amino acid composition, isoelectric point and potential N-glycosylation site
Given that IGKV1/D-33 is the most common IGKV1 family in AL (32%), a comparative mutation analysis was performed (MM = 13%). For alignment of all IGKV1/D-33 sequences see SI Figure 2. First, the sequences were analysed with respect to the distribution of the mutations in the corresponding regions and segments and the mutation frequency (). Concerning the IGKV-regions of the both cohorts a difference in the median mutation count could be observed without being significant (median mutation count: AL= 12.0 vs. MM= 10.0, mutation frequency AL and MM= 100%). In the IGKJ-region, the mutation frequency was 77% of the AL patients and 64% of MM patients, but the median mutation count of the mutated MM sequences seemed to be higher (median mutation count: AL = 1.0 vs. MM = 2.0). No mutations could be detected in the sequences of the C-regions covered by both cohorts. Beyond this range, a mutation at position 198 from V to L was detected in one sequence from a patient with dominant kidney involvement (SI Figure 2). Focusing on the mutation frequency at the level of the different segments, the most obvious differences were found in FR1. 69% of AL patients showed at least one mutation in FR1 (median mutation count: AL and MM = 1.0) whereas only 36% of MM patients did. The highest mutation count could be observed in FR3 for both diseases (AL = 4.0; MM = 3.5) with a mutation frequency of approximately 90% for both. Comparing the AL sequences with respect to the presence or absence of a HC in the serum, the AL sequences with a HC present in the serum tended to have a higher mutation count in the V segment (12.0 vs. 10.5) with the same mutation frequency, whereas the mutation frequency of the J-segment of the AL sequences without a HC was higher (83% vs. 71%; median mutation count: AL_HC and AL_noHC= 1.0).
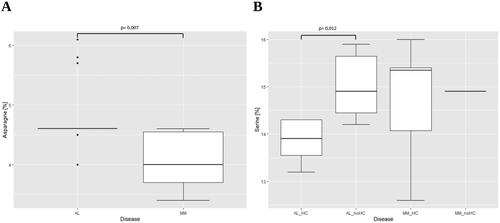
To investigate the effects of the mutations on the complete LC, the overall composition of the AA (SI Tables 4 and 5) was calculated. Small differences between AL and MM with respect to the median proportion of different AA could be detected. The AL sequences displayed a significant higher median percentage of asparagine (4.6% vs. 4.0%, p = .007, ).
By again stratifying the sequences according to a possible binding partner for the LC, another significant difference in the AA composition of the AL cohort could be detected. Comparing the AL sequences for the presence or absence of a HC, the amount of serine was significantly lower in AL with detectable HC in serum (13.9% vs. 14.9%, p = .012, ).
Besides the AA composition, the pI of the sequences was also calculated. No difference in the pI of both cohorts could be detected (median pI: AL= 4.90 MM= 4.87). Also, when they were grouped by HC and no HC, no major difference could be found (median pI: AL_HC= 4.80, AL_noHC= 4.99) (SI Table 6).
Because the presence of glycosylation is discussed as a potential cause for LC aggregation [Citation25, Citation26], bioinformatical analysis of the protein sequences for glycosylation was performed. We identified in 61.5% of the IGKV1/D-33 AL sequences a potential N-glycosylation site and only in 9.0% of the IGKV1/D-33 MM sequences. This was also reflected in the whole cohort, where more AL sequences showed a potential N-glycosylation site (42.5% vs. 16.9%, p = .004).
Mutation analysis of IGKV1/D-33 joined with IGKJ2
In a more detailed mutational analysis, we studied IGKV1/D-33 sequences which are most linked to IGKJ2 at the level of individual mutated positions (). This analysis showed mutation hotspots (mutations ≥50% of sequences) in the CDR1 and CDR3 and in the FR3 in AL. More specifically: In CDR1 and CDR3, one position was mutated more than 50% in each case (30S and 93 N). In FR3, there were even three positions (70D, 80P, 83I). The MM sequences showed mutations in 50% in CDR3 and in FR3 and in one position in the J-segment. In CDR3, this was one position (93 N), as well as in FR3 (70D) and in the J-segment (112E).
Figure 4. Extract of the IGKV1/D-33 and IGKJ2 alignment in AL amyloidosis and multiple myeloma patients. FORx = sequences from AL amyloidosis patients, MMx = sequences from multiple myeloma patients. H = dominant heart involvement, K = dominant kidney involvement, D = diverse organ involvement, red = nonsynonymous substitutions, green = linker-region, purple = insertions and deletions, highlighted in green = positive charged amino acids, highlighted in blue = negative charged amino acids. The first position of the IGKC-Ensembl reference was completed by the uni prot reference (P01834). The amino acids were numbered according to the Vbase2 reference. Complementary-determining regions (CDRs) were aligned according to Kabat using abYsis.
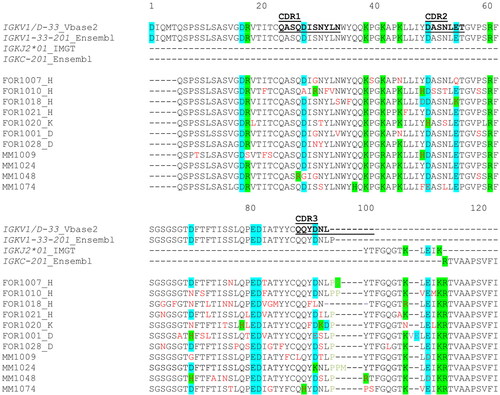
In four out of seven AL cases and in two out of four MM cases a nonsynonymous substitution was detected on position 70D. Interestingly, this exchange caused a loss of charge or a reversal of charge from negative to positive. Position 80P and 83I accumulated nonsynonymous substitutions only in the AL cases and the mutations at position 83I were associated with dominant heart involvement in all cases (4/4) and diverse organ involvement in one case. Interestingly, this AL patient had also heart in addition to kidney involvement.
In 26 positions, only the AL sequences are mutated (19V, 32Y, 33L, 34N, 36Y, 40P, 45K, 51A, 55E, 65S, 67S, 72T, 73F, 78L, 79Q, 80P, 83I, 85T, 86Y, 91Y, 94L, 105Q, 107T, 108K, 109/110ins, 113I), whereas mutations in nine positions could only be observed in MM cases (9S, 18R, 22T, 27Q, 74T, 87Y, 89Q, 90Q, 112E).
Discussion
In the recent years, lambda LC have been studied in detail in AL, but little is known about kappa sequences, especially structural data are limited [Citation27]. In this study we provided a systematic overview of the IGK family distribution in AL in comparison to MM, theoretical biochemical properties of the protein sequences of the most common IGKV-type, as well as mutational analysis, allowing us to identify the underlying somatic differences in a series of patients with AL or MM. We used two very well-defined clinical cohorts. Forty-one AL patients were consecutively enrolled in this study and sequence analysis was not possible in only one patient. MM patients were clinically well characterised under the GMMG-HD6 study guidelines to exclude a concurrent AL (median follow-up of 48.9 month) [Citation9, Citation10] and consequently, three patients with MM and AL were excluded from the study, which make our control group quite unique.
We show that IGKV1 dominates in AL as well as in MM. In 2003, Abraham et al. [Citation28] also detected the IGKV1 family as the most common gene usage in their cohort of 26 AL patients and in this group, most patients showed IGKV1/D-33, with IGKV1/D-39 being the second most prevalent. Therefore, we were able to confirm IGKV1/D-33 and IGKV1/D-39 as the most frequent IGKV1 family members in AL. This was also reflected in the data of Kourelis et al. [Citation29], where IGKV1/D-33 was the most common IGKV1 family.
For further analyses, AL patients were defined in terms of their clinical presentation, i.e. their predominant organ involvement like it has been previously shown for lambda [Citation11]. Three AL patient groups were defined, 34% presented dominant kidney involvement and 20% dominant cardiac involvement. The remaining 46% of patients were defined as diverse. Analysis of IGKV utilisation in AL patients showed predominance with regard to IGKV1/D-33 and dominant heart involvement; in dominant kidney patients, IGKV1/D-39 was mostly assigned. Kourelis et al. [Citation29] also analysed the organ involvement according to the IGKV-region gene usage in 176 kappa patients using proteomics. In their study IGKV1-5 was associated with cardiac involvement. For renal involvement there was no prevalent association detectable. Regardless of cardiac or renal involvement, a correlation of IGKV1/D-33 and liver involvement was found in their study. Our data showed a trend towards IGKV1-16 usage associated with liver involvement. In the study of Comenzo et al. [Citation24] with 12 AL patients, cardiac involvement was also most commonly associated with IGKV1/D-33, as well as renal involvement. IGKV1/D-39 was not detected in that study, which may be due to the small number of samples.
Research into the variability of kappa LC sequences has usually focused on the V-segments and ignored the J-segment [Citation30, Citation31]. However, our sequencing approach allowed us not only the identification of the IGKV and IGKJ-related segments but also the analysis of the different connections of those. Accordingly, our study analysed for the first time the combination of IGKV and IGKJ and shed light on the complex process of IGKV/J recombination in AL and MM, even though the sample size is relatively small and further analysis would be of interest. In the AL cohort, IGKJ2 was the most abundant, compared with MM, where both IGJK2 and IGKJ1 were prominent. The expression of IGKJ3 and IGKJ5 also differs across the two diseases. The presence of IGKJ3 was more frequent in the MM cohort. In AL the expression of IGKJ5 was higher. With respect to organ tropism, a preferred IGKJ use could be shown in addition to the already discussed IGKV association. It was noted that IGKJ2 was most frequently associated with dominant cardiac involvement, while dominant renal involvement was equally associated with IGKJ1, IGKJ2 and IGKJ4.
In terms of mutational analysis of IGKV1/D-33, as the most abundant IGKV representative, our analysis revealed a higher median mutation count for the IGKV-segment of the AL sequences compared to MM (AL = 12.0 vs. MM = 10.0) without being significant probably due to small numbers. We showed differences in the occurrence of mutations in the J-segment in both diseases, however, the median mutation count of the MM sequences was higher (median mutation count: AL = 1.0 vs. MM = 2.0). FR3 and CDR3 were most frequently mutated in both, with a median mutation count in FR3 being the highest (AL = 4.0; MM = 3.5). Our data indicated differences in AA composition of IGKV1/D-33 sequences with respect to asparagine. Compared with the MM sequences, the amount of asparagine in AL was higher. Analysis of the presence of a HC or no HC also revealed differences in the serine concentration in AL. Since these two AAs are polar, uncharged AAs, no difference in the pI of these sequences could be detected. Accordingly, the explanation of the amyloidogenic potential of the studied kappa LCs cannot be explained by the comparison of the pI and might be due to the presence of single mutations. Poshusta et al. [Citation32] postulates that not only the number of mutations provides sufficient information for amyloidogenicity, but rather the position of mutations that plays an important role. In their study they found accumulation of a large number of somatic hypermutations in the CDR1, CDR2, CDR3 as well as FR3. Our analysis of the IGKV1/D-33 sequences associated with IGKJ2 revealed also mutation hotspots in the CDR1 (30S), CDR3 (93N) and FR3 (70D, 80P, 83I) for AL. For MM we found mutation hotspots in the CDR3 (93N) and FR3 (70D). 70D was mutated in 4/7 AL and in 2/4 MM sequences and associated with a loss or reversal of charge. More precisely, in 3 AL sequences the mutation towards asparagine and in one case towards histidine could be detected. One MM sequences showed the D70H mutation. Randles et al. [Citation33] also detected the mutation on position 70 towards histidine and described it as not being part of the dimer interface but as potential driver of the overall stability of the protein. In another study, Conners et al. [Citation30] describes the replacement of D70 with asparagine as an introduction of an N-glycosylation site. Nevone et al. [Citation34] also found an association between kappa AL and the N-glycosylation of the variable region, mostly in the FR3. In our entire cohort, the AL sequences had significantly more potential glycosylation sites than the MM sequences, which was also reflected in the most abundant AL subfamily IGKV1/D-33, with one predicted N-glycosylation site in eight of the 13 AL sequences, but only in one of the 11 MM sequences. Accordingly, our results of the N-glycosylation analysis provide validation of the findings of Nevone et al. [Citation34] describing an N-glycosylation hotspot in the FR3 region of kappa LCs and associated with AL. In their study, a predicted N-glycosylation site was found in 32%–42% of AL and 12%–14% of MM cases, with most located in the FR3 region (strand D and E) of AL but not MM kappa LCs. The mutation at position 83I was detected only in AL and, interestingly, it occurred in all patients with dominant cardiac involvement and in one patient with both cardiac and renal involvement. To compare our data, we used sequences already published in AL-Base. Among them one AL sequence was associated with the linkage of IGKV1/D-33 and IGKJ2, as well as 21 MM sequences. The previously described mutation site 83I in AL was also detectable in the sequence published in AL-Base, this sequence originated from an AL patient with multiple organ involvement, including the heart. In the 21 MM annotated sequences, a mutation was detected in eight cases. However, information on the clinical presentation of the MM patients is missing, which makes a comparison with our data difficult. Also, the possibility of a later development of a AL cannot be excluded.
In conclusion our data provide additional evidence for favoured IGK gene usage in relation to organ tropism in AL. We were able to demonstrate preferential use for both, IGKV and IGKJ in patients with dominant cardiac involvement. Patients with dominant kidney involvement showed also a preferred IGKV association. If we hypothesise that certain mutations favour fibril formation and finally promote their deposition in-vivo, the analysis of mutational exchanges of LCs is of particular interest. In this regard, our analysis may provide the basic for further studies addressing structural alternations and dynamic consequences. This might result in the future into a better understanding of the pathogenesis, improvement of earlier diagnosis and development of new treatment options for patients with AL.
Abbreviations:
| AA | = | Amino acid |
| AL | = | AL amyloidosis |
| AL_D | = | Diverse organ involvement |
| AL_H | = | Dominant heart involvement |
| AL_K | = | Dominant kidney involvement |
| BM | = | Bone marrow |
| CDR | = | Complementary-determining region |
| FR | = | Framework region |
| HC | = | Heavy chain |
| IGK | = | Immunoglobulin kappa |
| IG LCs | = | Immunoglobulin light chains |
| J | = | Joining |
| MM | = | Multiple myeloma |
| pI | = | isoelectric point |
| V | = | Variable |
Supplemental Material
Download MS Word (101.6 KB)Acknowledgement
We would like to thank the patients for their support to participate in our study and the clinical Myeloma-Registry and the GMMG Central Lab and Biobank Multiple Myeloma; University Hospital Heidelberg & GMMG e.V.
Disclosure statement
EKM Consulting or Advisory Role, Honoraria, Research Funding, and Travel Accommodations and Expenses—Bristol Myers Squibb/Celgene, GlaxoSmithKline, Janssen-Cilag, Sanofi, Stemline and Takeda. The other authors declare no conflict of interests.
Data availability statement
The data that support the findings of this study are available from the corresponding author, SS and SoS, upon reasonable request. IGKV1/D-33 AL and MM sequence data were stored in the European Nucleotide Archive (accession: PRJEB65847).
Additional information
Funding
References
- Buxbaum JN, Dispenzieri A, Eisenberg DS, et al. Amyloid nomenclature 2022: update, novel proteins, and recommendations by the international society of amyloidosis (ISA) nomenclature committee. Amyloid. 2022;29(4):213–219. Dec doi: 10.1080/13506129.2022.2147636.
- Merlini G. AL amyloidosis: from molecular mechanisms to targeted therapies. Hematology Am Soc Hematol Educ Program. 2017;2017(1):1–12. doi: 10.1182/asheducation-2017.1.1.
- Wechalekar AD, Schonland SO, Kastritis E, et al. A European collaborative study of treatment outcomes in 346 patients with cardiac stage III AL amyloidosis. Blood. 2013;121(17):3420–3427. Apr 25 doi: 10.1182/blood-2012-12-473066.
- Schroeder HW, Jr., Cavacini L. Structure and function of immunoglobulins. J Allergy Clin Immunol. 2010;125(2 Suppl 2):S41–S52. doi: 10.1016/j.jaci.2009.09.046.
- Hoehn KB, Fowler A, Lunter G, et al. The diversity and molecular evolution of B-cell receptors during infection. Mol Biol Evol. 2016;33(5):1147–1157. doi: 10.1093/molbev/msw015.
- Lefranc MP, Lefranc G. Immunoglobulins or antibodies: IMGT(®) bridging genes, structures and functions. Biomedicines. 2020;8(9):319. doi: 10.3390/biomedicines8090319.
- Gertz MA, Lacy MQ, Dispenzieri A. Immunoglobulin light chain amyloidosis and the kidney. Kidney Int. 2002;61(1):1–9. doi: 10.1046/j.1523-1755.2002.00085.x.
- Rajkumar SV, Dimopoulos MA, Palumbo A, et al. International myeloma working group updated criteria for the diagnosis of multiple myeloma. Lancet Oncol. 2014;15(12):e538-48–e548. Nov doi: 10.1016/S1470-2045(14)70442-5.
- Salwender H, Bertsch U, Weisel K, et al. Rationale and design of the German-speaking myeloma multicenter group (GMMG) trial HD6: a randomized phase III trial on the effect of elotuzumab in VRD induction/consolidation and lenalidomide maintenance in patients with newly diagnosed myeloma. BMC Cancer. 2019;19(1):504. doi: 10.1186/s12885-019-5600-x.
- Goldschmidt H, Mai EK, Bertsch U, et al. Elotuzumab in combination with lenalidomide, bortezomib, dexamethasone and autologous transplantation for Newly-Diagnosed multiple myeloma: results from the randomized phase III GMMG-HD6 trial. Blood. 2021;138(Supplement 1):486–486. doi: 10.1182/blood-2021-147323.
- Berghaus N, Schreiner S, Granzow M, et al. Analysis of the complete lambda light chain germline usage in patients with AL amyloidosis and dominant heart or kidney involvement. PLoS One. 2022;17(2):e0264407. doi: 10.1371/journal.pone.0264407.
- Baur J, Berghaus N, Schreiner S, et al. Identification of AL proteins from 10 λ-AL amyloidosis patients by mass spectrometry extracted from abdominal fat and heart tissue. Amyloid. 2022; 30(1):27–37. doi: 10.1080/13506129.2022.2095618.
- Huhn S. ELDA qASO-PCR for high sensitivity detection of tumor cells in bone marrow and peripheral blood. Method Mol Biol. 2018;1792:1–14.
- Bolotin DA, Poslavsky S, Mitrophanov I, et al. MiXCR: software for comprehensive adaptive immunity profiling. Nat Methods. 2015;12(5):380–381. doi: 10.1038/nmeth.3364.
- Retter I, Althaus HH, Münch R, et al. VBASE2, an integrative V gene database. Nucleic Acids Res. 2005;33(Database issue):D671–4. doi: 10.1093/nar/gki088.
- Duvaud S, Gabella C, Lisacek F, et al. Expasy, the swiss bioinformatics resource portal, as designed by its users. Nucleic Acids Res. 2021;49(W1):W216–w227. doi: 10.1093/nar/gkab225.
- Howe KL, Achuthan P, Allen J, et al. Ensembl 2021. Nucleic Acids Res. 2021;49(D1):D884–d891. doi: 10.1093/nar/gkaa942.
- Giudicelli V, Chaume D, Lefranc MP. IMGT/GENE-DB: a comprehensive database for human and mouse immunoglobulin and T cell receptor genes. Nucleic Acids Res. 2005; 33(Database issue):D256–61. doi: 10.1093/nar/gki010.
- Consortium U. UniProt: the universal protein knowledgebase in 2023. Nucleic Acids Res. 2023; 51(D1):D523–d531.
- Swindells MB, Porter CT, Couch M, et al. abYsis: integrated antibody sequence and structure-management, analysis, and prediction. J Mol Biol. 2017;429(3):356–364. 3 doi: 10.1016/j.jmb.2016.08.019.
- Gasteiger E, Hoogland C, Gattiker A, et al. Protein identification and analysis tools on the ExPASy server. In: Walker JM, editor. The proteomics protocols handbook. Totowa, NJ: Humana Press; 2005. p. 571–607.
- Gupta R, Brunak S. Prediction of glycosylation across the human proteome and the correlation to protein function. Pac Symp Biocomput. 2002;7:310–322.
- Dittrich T, Bochtler T, Kimmich C, et al. AL amyloidosis patients with low amyloidogenic free light chain levels at first diagnosis have an excellent prognosis. Blood. 2017;130(5):632–642. doi: 10.1182/blood-2017-02-767475.
- Comenzo RL, Zhang Y, Martinez C, et al. The tropism of organ involvement in primary systemic amyloidosis: contributions of Ig V(L) germ line gene use and clonal plasma cell burden. Blood. 2001;98(3):714–720. doi: 10.1182/blood.v98.3.714.
- Bellotti V, Mangione P, Merlini G. Review: immunoglobulin light chain amyloidosis–the archetype of structural and pathogenic variability. J Struct Biol. 2000; 130(2–3):280–289. doi: 10.1006/jsbi.2000.4248.
- Dispenzieri A, Larson DR, Rajkumar SV, et al. N-glycosylation of monoclonal light chains on routine MASS-FIX testing is a risk factor for MGUS progression. Leukemia. 2020;34(10):2749–2753. Oct doi: 10.1038/s41375-020-0940-8.
- Hora M, Sarkar R, Morris V, et al. MAK33 antibody light chain amyloid fibrils are similar to oligomeric precursors. PLoS One. 2017;12(7):e0181799. doi: 10.1371/journal.pone.0181799.
- Abraham RS, Geyer SM, Price-Troska TL, et al. Immunoglobulin light chain variable (V) region genes influence clinical presentation and outcome in light chain-associated amyloidosis (AL). Blood. 2003;101(10):3801–3808. doi: 10.1182/blood-2002-09-2707.
- Kourelis TV, Dasari S, Theis JD, et al. Clarifying immunoglobulin gene usage in systemic and localized immunoglobulin light-chain amyloidosis by mass spectrometry. Blood. 2017;129(3):299–306. doi: 10.1182/blood-2016-10-743997.
- Connors LH, Jiang Y, Budnik M, et al. Heterogeneity in primary structure, post-translational modifications, and germline gene usage of nine full-length amyloidogenic kappa1 immunoglobulin light chains. Biochemistry. 2007;46(49):14259–14271. doi: 10.1021/bi7013773.
- Sternke-Hoffmann R, Pauly T, Norrild RK, et al. Widespread amyloidogenicity potential of multiple myeloma patient-derived immunoglobulin light chains. BMC Biol. 2023;21(1):21. doi: 10.1186/s12915-022-01506-w.
- Poshusta TL, Sikkink LA, Leung N, et al. Mutations in specific structural regions of immunoglobulin light chains are associated with free light chain levels in patients with AL amyloidosis. PLoS One. 2009;4(4):e5169. doi: 10.1371/journal.pone.0005169.
- Randles EG, Thompson JR, Martin DJ, et al. Structural alterations within native amyloidogenic immunoglobulin light chains. J Mol Biol. 2009;389(1):199–210. doi: 10.1016/j.jmb.2009.04.010.
- Nevone A, Girelli M, Mangiacavalli S, et al. An N-glycosylation hotspot in immunoglobulin κ light chains is associated with AL amyloidosis. Leukemia. 2022;36(8):2076–2085. doi: 10.1038/s41375-022-01599-w.