
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Topic Modelling has established itself as one of the major text-as-data methodologies within the social sciences in general, and in communications science, in particular. The core strength of TM approaches is the fact that it is essentially a 2-in-1 method, as it both generates clusters into which the texts may fall as well as classifies the texts according to the clusters. Previous research has pointed out that pre-processing text corpora is as much a part of text analysis as the latter stages. Named Entity Recognition, however, is not often thought of when pre-processing texts for analysis and has thus far not received much attention in relation to the TM pipeline. If simply retaining or removing stop words can produce different interpretations of the outcomes of TM, retaining or removing NEs also has consequences on outcomes and interpretations. The current paper analyses the effects that removing/retaining NEs has on the interpretability of topic models. Both model statistics and human validation are used to address this issue. The results show differences in topics models trained on corpora with and without NEs. TMs trained on corpora where NEs are removed exhibit different structural characteristics, and, more importantly, are perceived differently by human coders. We attempt to formulate recommendations regarding the pre-processing of NEs in TM applications.
Topic Modelling (TM) has established itself as one of the major text-as-data methodologies within the social sciences in general, and in communication science, in particular. The core strength of TM approaches is the fact that they essentially are a 2-in-1 method, as a TM both generates clusters into which texts may fall and classifies the texts according to these clusters. Also, TM makes possible the classification of texts without a priori defining these categories, which allows for relatively fast exploration of textual data. It has been extremely useful for clustering and classification of large quantities of text, that would otherwise be unmanageable for conventional analysis approaches. The proliferation of software and dedicated packages made TM a popular choice for dealing with large text corpora.
Nevertheless, to make robust inferences from text-as-data methods, TMs require a substantial amount of validation (e.g., Grimmer & Stewart, Citation2013). Moreover, text-as-data methods in general, and TMs in particular, are quite sensitive to the input data and may result in different outcomes depending on what goes “in.” Within text analysis applications, much of the subsequent interpretation of the results strongly depends on the steps that researchers take at the beginning of the analysis (Maier et al., Citation2018). While such pre-processing is something that is thought of as a procedure that happens before the actual analysis begins (as is indicated by the etymology), in actuality, it may play a significant role in affecting the results, and thus should be considered as part of the analysis pipeline and hence should be given more substantial consideration when designing a study. Denny and Spirling (Citation2017), for example, point out 7 different binary pre-processing steps – Punctuation, Numbers, Lowercasing, Stemming, Stopwords, n-gram inclusion, and Removal of infrequently used terms, which result in combinations of text pre-processing. They further show that for unsupervised applications (Wordfish and LDA), these 128 combinations can produce drastically different results.
When analyzing the impact of word removal on topic modeling, it becomes evident that certain categories of words, which arguably contribute little to the overall meaning of the text, can significantly influence the outcomes of TM. As a result, careful consideration should be given to the inclusion or exclusion of these word categories based on the specific goals and desired outcomes. Stop words are generally disregarded due to their limited semantic value (such as articles, prepositions, and pronouns), their removal from the corpus, however, can lead to noticeable differences in the TM results. This suggests that even seemingly insignificant words can contribute to the overall coherence and structure of the identified topics. In contrast, Named Entities (NE), which encompass proper nouns like the names of people, places, organizations, and other specific entities, carry inherent meaning and context within the text. Therefore, their presence or absence in the TM process can exert a more pronounced influence on the resulting topic model that may produced undesired effects on the interpretations that researchers should be aware of.
Named Entity Recognition, however, is not often thought of when pre-processing texts for future analysis and has thus far not received much attention. This contribution argues that in particular for TM applications it may be important to be aware of the consequences of the inclusion or exclusion of NEs for the results that are generated. The current study aims to investigate how retention or removal of NEs in the corpus pre-processing influences different criteria that may affect the interpretation of topic models. First, this includes structural criteria that may guide model selection, namely the optimal number of topics, Coherence and Exclusivity scores. Semantic coherence is one of the metrics developed to assess the quality of topics within a topic model, and it was shown to closely correlate with expert opinions of the topic quality (Mimno et al., Citation2011). Exclusivity is a metric that measures the (im-)probability of top words in a topic to appear within top words of other topics (e.g., Roberts et al., Citation2014).
Both of the aforementioned quantities (i.e., Coherence and Exclusivity) can be thought of as quantitative metrics of “interpretability” (e.g., Mimno et al., Citation2011; Rijcken et al., Citation2022; Roberts et al., Citation2014). However, arguably the most important part of the validation procedure of TMs is human validation (e.g., Grimmer & Stewart, Citation2013; Grimmer et al., Citation2022), and we hold the same opinion. We thus focus on the human interpretation of topic models trained on the corpora with and without NEs. Crowdsourced validation of topic models has, for some time, been considered a good approach (e.g., Chang et al., Citation2009; Ying et al., Citation2021), while recent studies show that automated evaluation might be insufficient (Hoyle et al., Citation2021) for model evaluation. We follow these observations in our approach.
Named entities in topic models
Named Entity Recognition is an information extraction technique that identifies specific parts of a text as being “Named Entities,” i.e., parts of the language that carry specific, contextual information. NEs can potentially be people, countries, timeframes, organizations, amounts of money, etc. In fact, “named entity” is not a well-defined term, thus posing problems for the use and evaluation of named entity recognition tasks (Marrero et al., Citation2013). One of the widely used, inclusive definitions for Named Entities is that of “rigid designators” (Nadeau & Sekine, Citation2007), as defined by Kripke (Citation1972) – “a designator d of an object x is rigid if it designates x with respect to all possible worlds where x exists, and never designates an object other than x with respect to any possible world.”
Computer linguists have acknowledged that NEs “play a critical role in news articles” when estimating topic models (Hu et al., Citation2013) and have employed various strategies to account for them. Previous approaches applied some sort of weighting to topic models in order to increase the impact of NEs over the topic estimation (e.g., Hu et al., Citation2013; Krasnashchok & Jouili, Citation2018; Kuhr et al., Citation2021; Kumar & Singh, Citation2019). These strategies typically lead to a higher topic coherence. For example, Kuhr et al. (Citation2021) used a relational topic model (Chang & Blei, Citation2009) where they defined NEs as implicit links between documents. Their study revealed that combining NEs with TM improved the perplexity measures. However, the improvement was dependent on the type of corpus (e.g., Wikipedia or news) and also the NE types (i.e., persons, organizations, or locations).
The removal of certain word groups from corpora is an established pre-processing step for practical text analysis. From a theoretical standpoint, stop words (mostly function words that do not bear any meaning) should not have any impact on the performance of topic models, because they do not have a reference to a particular subject matter. They are rather functional elements that tend to be evenly distributed across the corpus and topics. However, practical research has shown (Denny & Spirling, Citation2017) that stop words introduce noise into the model and TMs such as LDA have shown to be susceptible to noise. If simply retaining or removing stop words can produce different interpretations of the outcomes of TM, we expect that retaining or removing NEs should have drastic consequences on outcomes and interpretations. NEs are not functional, but rather lexical units rich with context. And this additional context may be beneficial or detrimental to the estimation of topic models, because Topic Modeling relies on word co-occurrences. In particular, they might affect the clustering in broad samples as well as the interpretability of outcomes.
If a specific entity is being commonly referred to in the context of a single topic, the model could associate the NE with this topic, which may, in turn, produce bias in estimation. On the one hand, Kumar and Singh (Citation2019) highlight that event driven topics often have overlapping keywords (e.g., terrorist attacks). In such cases, applying weights based on NEs makes such topics distinguishable into single events. But on the other hand, this could potentially be problematic for other focused or time-specific corpora, where one topic/entity could dominate the space. For example, if a model is trained on news articles from May 2021, “Bill Gates” will likely be associated with the latent topic “Divorce.” Estimation problems could arise if there is an article mentioning Microsoft and Bill Gates. Would the topic of “Divorce” percolate to Microsoft in this case? These problems could complicate human validation, and since there are no be-all-end-all data-driven validation procedures for TMs, in turn, compromise the results.
Communication researchers often want to understand the relationships between actors and issues in public discourses (e.g., Eberl et al., Citation2017). Therefore, it is desirable to divorce topics (or issues) from actors in text-analysis and to investigate the interplay of actors and issues separately. For example, during election campaigns political parties and candidates sponsor particular issues that they believe are important and would appeal to their potential voters. In such application scenarios, TMs fitted on corpora with NEs are expected to yield topics where certain actors and issues are intertwined.
Furthermore, in this context different kind of newspapers also feature different content characteristics where NEs can potentially influence the TM estimation. Tabloid newspapers have a stronger focus on personification than the “quality” newspapers and tabloids often use celebrities as hooks for their news stories (Boukes & Vliegenthart, Citation2020; Jacobi et al., Citation2016). Hence, when estimating a TM on a corpus with a mixed newspaper sample, the outlets’ reporting styles could potentially contaminate the topics and thus make it more difficult for the researchers to interpret them and to find common topics across newspapers. Therefore, removing NEs beforehand could lead to cleaner and broader topics.
Finally, NEs reference particular elements in the world (Nouvel et al., Citation2016). This, in turn means that the interpretation of the TM’s output depends on the readers’ abilities to resolve NEs and make sense of them. Therefore, interpreting topic models without NEs would require less specific domain knowledge.
The decisions taken when pre-processing text should be treated as a measurement problem (Denny & Spirling, Citation2017), and ideally should be theoretically driven. However, the theoretical justification for these decisions is not readily available and very context-specific, and validation is therefore warranted. Studying how the decision to include or exclude NEs influences a bag-of-words approach (specifically, TM) therefore seems an important contribution to the social science methodological toolkit. This study proposes to systematically compare topic models that have been trained on corpora that include NEs with models that have been trained on the same corpora, but with NEs removed in the pre-processing step. First, the paper aims to examine whether there are observable differences in model statistics depending on the corpus used, and, more importantly, whether the two modes of pre-processing the corpora result in appreciably different outcomes as judged by humans. We aim at drawing recommendations as to in which instances NE removal in the pre-processing pipeline may be useful.
Data and methods
The current study uses the Newsroom dataset (Grusky et al., Citation2018), a dataset of around 1.3 million newspaper articles from 38 publications. Text processing was done with Python’s spaCy 3 moduleFootnote1 (Honnibal & Johnson, Citation2015) for Named Entity recognition, lemmatization, stopwords removal, etc., as well as the Gensim package (Rehurek et al., Citation2011) for additional processing, such as collocation extraction (e.g., Mikolov et al., Citation2013). The following steps were taken to pre-process the texts: first, NEs were identified and tagged. Named Entities that are categorized as: People [spaCy categorization: PERSON], Nationality/Religious/Political Groups [NORP], Buildings/Airports/highways [FAC], Companies/agencies/institutions [ORG], Countries/Cities/States [GPE], Non-country specific locations (e.g., mountain ranges, etc.) [LOC], Products/Objects/Vehicles/etc [PRODUCT] and Historical events [EVENT] were removed.
Second, texts were lowercased, lemmatized, and stopwords removed (unless part of named entity). Finally, collocations were identified using the mutual information score. This sequence allowed to retain as much useful information on Named Entities but also reduce the dimensionality of texts using the standard pre-processing procedures. Topics were estimated with stm (Roberts et al., Citation2019) package for R.
In order to assess the impact of NE removal on the interpretability of topic models, we tackle the question from three different angles, covering theoretical considerations as well as the human perception of topic modeling outcomes. First, we run a simulation scenario, in which we calculate optimization metrics of topic models. Second, we utilize an expert coding approach and third, we gave a similar task to non-experts through crowd coding. In each scenario, we compare two subsets of corpora, one for which NEs have been retained and one for which we removed NEs.
To create a simulation scenario that is generalizable to more than one specific text corpus, we created 30 random subsamples from the Newsroom data with texts each (this decision was taken for computational reasons). Each of the subsampled training corpora was then duplicated to create two sets:
corpora and
corpora. We have applied the same pre-processing procedure to all corpora in both sets: stop words removal, lemmatization, removal of non-alphabetic characters, and collocation extraction. However, from the RemovedNE set of corpora, we have additionally removed Named Entities as a pre-processing step. Details on the actual topic models that were estimated are given in further sections.
For assessing the consequences of NE removal for the human interpretation of topic models, we conduct two separate experiments. The first experiment contributes to understanding the impact of NE removal on topic models by researchers that are familiar with the methodology and have been using it in their research. Five expert coders (researchers that have worked with topic models previously) were tasked to code 750 randomly sampled topics from the models trained on the two different sets of corpora. The topics from all models were randomly shuffled and coders were presented with the top 10 terms per topic (arranged by FREX – a measure that looks at both frequent and exclusive words within a topic (Bischof & Airoldi, Citation2012)). It is important to note, that since collocation extraction was performed in the pre-processing step, top ten terms can be either individual words, or collocations (e.g., “Bill Gates” would be a single term, rather than “Bill” and “Gates”). Furthermore, the extracted collocations are linked with an underscore “_” symbol, which is explicitly retained in the punctuation removal step, so that “Bill Gates” would be represented as “bill_gates” in the final model output. The task was intentionally left vague: “Is the topic interpretable?” (i.e., a Bernoulli variable) reflecting the fact that the concept of “interpretability” of a topic model is a vague concept and may differ depending on the context/person/etc.
Finally, a crowdsourcing experiment was conducted to assess how people unfamiliar with topic modeling asses the interpretability of models estimated on text corpora with or without Named Entities. The experiment used a repeated measures design, with 1500 people tasked with rating 5 topic models each ( completed the procedure, resulting in
data points). Each person rated a random topic (represented by the top 10 words arranged by FREX) from a randomly sampled topic model (more information on topic models in the following sections). Similar to the previously described experiment, the main question remained: “Is the topic interpretable?”. However, in addition to this question, the participants were presented with a word deletion task. Participants were allowed to select any number of the top 10 presented words and “delete” them in order to make the whole topic more “interpretable.” This task allows us to measure whether one of the pre-processing steps (i.e., removal or retention of Named Entities) produces a more “coherent” top words list. For example, in a sequence [pear, watermelon, banana, orange, fruit, melon, asbestos, boeing, fig, cherry], words “asbestos” and “boeing” are not coherent with the rest, so
for this sequence, and
. The number of deleted words is thus a Binomial variable with
.
Results
Distribution of named entities in texts
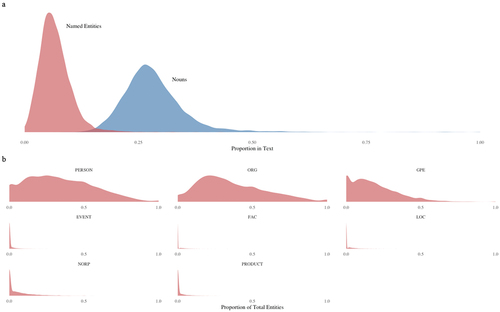
We first delve into the description of the distribution of Named Entities in texts. We base this description on a sample of texts without prior pre-processing. On average, Named Entities constitute around 7% of all words in texts, while nouns in general constitute around 30%, which corresponds to previous linguistics research (e.g., Hudson, Citation1994; Liang & Liu, Citation2013). shows the distribution of the proportion of Named Entities and Nouns in texts (Panel A), and the distribution of NE types as a proportion of total NEs (Panel B). Unsurprisingly, the most frequent types of NEs are PERSON, ORG, and GPE.
Figure 1. Distributions of named entities and nouns.
Optimal K topics
As mentioned previously, a useful place to start investigating the differences between corpora with or without NEs is to see whether the “optimal” of topics differs between the two. One way to do this is to use spectral initialization (Mimno & Lee, Citation2014), which is implemented in the stm package. This algorithm allows to automatically select the number of topics from a given corpus. While this is a stochastic method, that can result in different topics or a different number of topics (Roberts et al., Citation2019), it nevertheless provides some initial information to the researcher about how to fit the model. We have randomly sampled corpora 60 times from each of the two sets (RemovedNE vs. NE) and initialized the topic models with
with “Spectral” initialization for a single iteration of the Expectation-Maximization algorithm (in this scenario convergence is not required, the only interest lies in the proposed number of topics).
We have thus obtained a vector of 60 proposed “optimal” topics. A Welch’s t-test showed that there is indeed a difference in the proposed number of topics for RemovedNE
vs. NE corpora
,
. A simple visualization is presented in , initially providing evidence of the difference between the two corpora. We argue that this simple result is already a non-trivial difference, because choosing
for the model, can drastically change the interpretation of the results down the line.
Figure 2. Box plots showing the difference in the number of “recommended” topics.
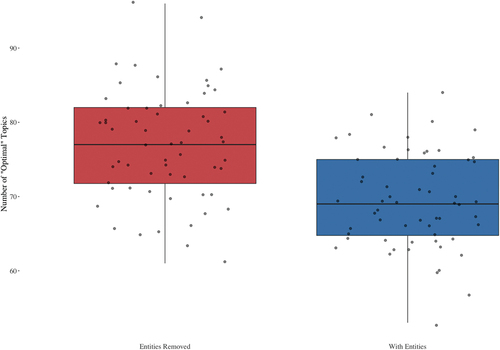
It could be argued that this difference can be attributed to the fact that by removing Named Entities, we decrease the number of terms in the corpus, therefore significantly changing the input data. However, if the reduction of terms was the main effect in the difference in the “optimal” number of topics, one would reasonably expect that the RemovedNE corpora would produce fewer optimal s since there are fewer terms. Instead, however, we see the opposite.
We further investigate model statistics that require full convergence.Footnote2
Distribution of named entities in topics
We now turn to the distribution of Named Entities in topics. We look at 30 separate models trained on corpora with Named Entities retained, resulting in 2250 individual topics. We look at the distribution of NEs in top 15 topic words by word probability, FREX (frequency and exclusivity), and lift (the ratio of a word probability within a topic to its marginal probability across the whole corpus (Sievert & Shirley, Citation2014; Taddy, Citation2012)). provides probabilities for at least one NE being included in the top-15 list, average number of NEs in the top-15 words, as well as the average proportion of NEs in the top-15 words. As can be seen, the average proportion of NEs in the top-15 words is around 18% for word probability and 39% for FREX and 37% for Lift. This is a substantial proportion, given that NEs constitute only around 7% of all words in the corpus. Therefore, NEs are more likely to be included in the top-n model output than by random chance.
Table 1. Average frequency of named entities in top-15 words lists.
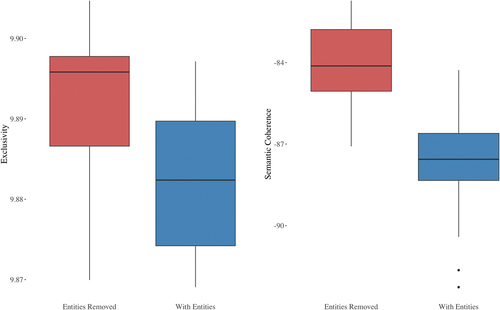
Semantic coherence and exclusivity
The differences between RemovedNE and NE are, once again, statistically significant. ,
;
for Exclusivity, and
,
;
for Semantic Coherence. Boxplots are provided in .
Figure 3. Box plots showing the differences in exclusivity and semantic coherence.
To ensure the robustness of our findings, we conducted an additional analysis using a set of NE that served as a “control” for the removed Named Entities. To create this control set, we first determined the proportion of NEs relative to the nouns in the original text. We then removed the same proportion of nouns from the NE texts. However, we found that the model performance was significantly worse for the “control” NE corpora. While the mean Exclusivity score (;
), was comparable to the original NE set, the mean Semantic Coherence score (
;
) was significantly worse. These results suggest that the difference in performance metrics between the NE and RemovedNE corpora can be attributed to the actual removal of Named Entities, rather than simply removing words. Therefore, we can be more confident in our conclusion that Named Entities have a significant impact on model performance. Since the “control” models performed worse than the base NE models, we do not consider them further.
Cross-model prediction
To evaluate the generalizability of models trained on both the NE and RemovedNE corpora, we conducted a test that measured how well models trained on one set could fit the opposite set of corpora. This test involved combining the Semantic Coherence metric, which measures how distinct and coherent the topics are, with the Held-Out Log-Likelihood metric (the Exclusivity metric is not used here since it is an intrinsic metric based solely on word distributions across topics). The held-out log-likelihood metric works by holding out a sample of words from the texts and then predicting their log-likelihood based on the model’s parameters (Roberts et al., Citation2014, Citation2019). However, in our test, we went one step further and attempted to predict the log-likelihood of held-out words from the opposite corpora.
By doing so, we aimed to determine which model could better predict missing words from the opposite set of corpora, indicating a more generalizable model that could capture (and anticipate) language better. This analysis provided us with additional insights into the performance of models trained on different sets of corpora and their ability to generalize to new datasets.
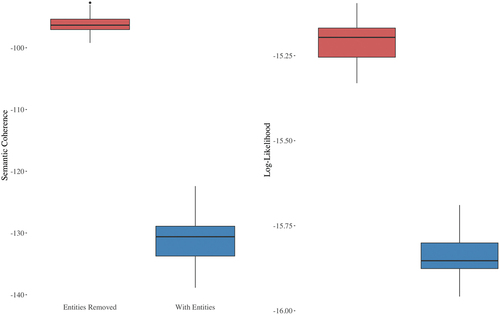
The results of the analysis, depicted in , indicate that both sets of models performed worse than when compared to the evaluation on their own corpora (i.e., Coherence of RemovedNE models with RemovedNE corpora, and vice versa). However, the RemovedNE models consistently outperformed the NE models in the cross-model prediction. Specifically, the average coherence score was higher for the RemovedNE models () than for the NE models (
), with a statistically significant difference (
). Additionally, the held-out log-likelihood was higher for the RemovedNE models predicting NE corpora (
,
), with a significant difference between the two sets of models (
).
Figure 4. Box plots showing the differences in semantic coherence and held-out log-likelihood on cross-model prediction.
These results suggest that Named Entities are not treated in a similar way as other nouns in human language in terms of their statistical distribution. Instead, Named Entities possess certain frequency characteristics that structurally change the composition of topics. If this were not the case, one would expect the NE models to perform better in the task, simply due to having access to more word tokens as a result of pre-processing choices. Overall, this analysis highlights the importance of carefully considering the treatment of Named Entities in natural language processing tasks.
Targeted corpora
Perhaps the performance metrics reported above are somehow biased by the fact that the corpora used contained a random selection of texts. In order to test whether this is the case, we performed a simple filtering of the texts into “targeted corpora:” corpora that contained only texts that were related to an overarching theme – “Sports,” “Politics,” “Economy,” “Science,” and “Celebrity” texts.Footnote3 The rationale behind this is that Named Entities may play a different role, or behave differently, in different contexts, especially when the context is a specific domain.
With thus end up with 30 (original corpora) 5 (separate themes)
2 (retained vs. removed NEs) separate topic models. For the interest of computational tractability, we only train models with
. We perform the same analysis, comparing the average coherence and exclusivity scores as before, but now for each of the 5 overarching themes. The results of this analysis can be seen in .
Figure 5. Box plot showing the differences in semantic coherence and exclusivity for each of the 5 overarching themes.
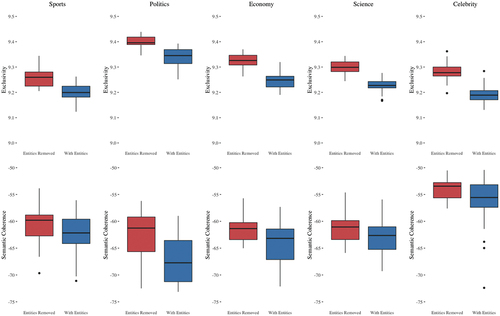
As can be seen from the figure, the patterns stays the same across all 5 themes. The RemovedNE models consistently outperform the NE models in terms of both coherence and exclusivity. All differences are statistically significant ().
Therefore, at least in terms of topic quality model metrics, it would seem that the models with removed Named Entities are “better.” Nevertheless, it is difficult to judge by how much, since it is really difficult to translate, e.g., a difference in Exclusivity to a real-world application. Therefore, the most important assessment is to determine whether humans can notice this difference.
Human validation
In this section, we try to determine the “interpretability” of topic models depending on whether they were estimated on corpora with or without NEs.
We follow the advice of Lundberg et al. (Citation2021) and explicitly state our target quantity of the analysis. Our theoretical estimand is the difference in “interpretability” of a topic model trained on a corpus with NEs removed in the pre-processing step and a topic model with NEs retained in the pre-processing step:
We are thus interested in the causal outcome. It should be noted that the main interest of this paper revolves around topic models, however, the population of interest are actual text corpora, rather than topic models trained on them, with topic models being merely a part of the estimation strategy. Empirically, since we don’t foresee any confounders within this approach, it is fairly straightforward to translate the theoretical estimand to the empirical estimand
, with
being the probability of an average topic being judged as “interpretable”. Finally, the empirical estimate
is defined as the average difference in regression prediction:
Expert experiment
The initial results show that the “interpretability” of topic models is not necessarily a general concept. Post-experiment feedback showed that people have different reasoning when it comes to determining whether a topic is “interpretable” or not. Krippendorff’s for the 5 coders was 0.58, while % agreement was 60.5, suggesting less than optimal intercoder reliability.
Nevertheless, with coders being odd, two types of “majority vote” were calculated: simple (i.e., if the majority of coders − 3 out of 5 – indicated that the topic is useful or not), and 80% supermajority (i.e., if 4 out of 5 coders agree, the topic is coded 0 or 1, other instances are coded as NAs).
There are several ways one can approach the analysis of these data. The first, since the number of coders is odd, is to calculate the majority vote for a given topic, and treat it as “interpretable” if the majority of coders agree. Using this method, 68% of all topics were coded as interpretable. The second option is to treat every topic coder pair as a separate observation. This is especially appropriate given the low reliability scores, indicating that each person approached the same topic with a different idea of what “interpretable” means. This is a more conservative view of the data but is possibly more true to the underlying data-generating process. Both of these approaches can be analyzed by a simple Bernoulli model predicting whether a model is “interpretable” based on the inclusion/exclusion of Named Entities, although random intercepts on coders are an appropriate addition in the second case. Stan (Carpenter et al., Citation2017) was used to estimate Bayesian regression models. Weakly informative priors were used on both models. All coefficients for both models had
scores not exceeding 1, indicating good convergence (Gelman & Rubin, Citation1992; Vehtari et al., Citation2021). shows the results of both models. shows posterior predicted probability (inverse logit of model coefficients) distributions for both models.
Figure 6. Posterior predicted probabilities for models I and II.
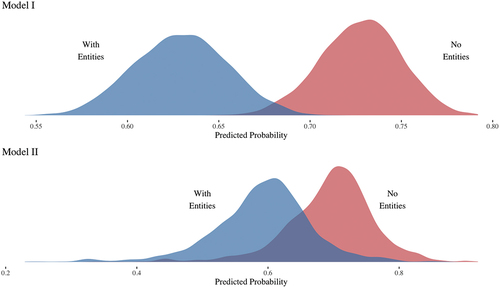
Table 2. Bernoulli model results predicting probability of a topic model to be judged as “interpretable”.
The values presented are posterior log-odds from a Binomial model. 95% Credibility Intervals are presented in brackets.
It is evident from the and that both models indicate that the RemovedNE corpus generally produces more “interpretable” topic models than those trained on the NE corpus. While the difference is more pronounced for the model predicting the “majority vote” (Model I), the model predicting a coder answered that the topic is “interpretable” for every coder topic pair (Model II) still produces statistically distinguishable results for the two training corpora. The results indicate that removing Named Entities from the corpus does indeed change how people working with topic models assess their quality.
Crowdsourced experiment
We now move to the large-scale crowdsourced, repeated measures experiment. Within this experimental set-up, there are two types of dependent variables of interest – whether the topic is “interpretable” or not (Bernoulli()) and how many words must be removed from the top 10 list in order to make the topic “interpretable” (Binomial(10,
)). The majority of coders found that the presented topics are, on average, more “interpretable” than not (70%, a figure very similar to the one designated by expert coders). presents the empirical distribution of “interpretable” vs. “Non-Interpretable” topics (Panel A) and the number of words to be deleted (word deletion task) in order to make the topic “interpretable.” Both figures are broken down by topics trained on the RemovedNE vs NE corpora.
Figure 7. Empirical proportions of “interpretable” topics (panel A) and number of deleted words (panel B) for models trained on NE and removed NE Corpora. Barcharts include 95% CIs for binomial proportions.
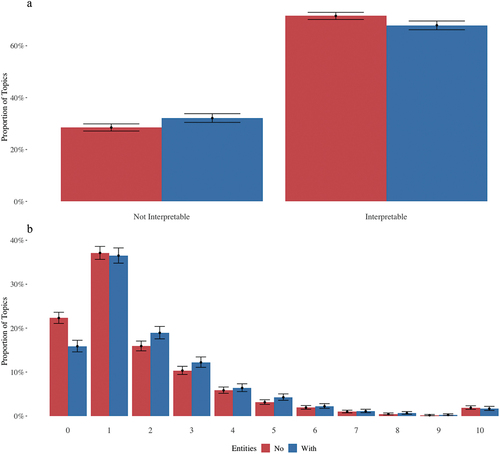
Judging from (Panel A), there are visible differences between topics trained on different corpora – the proportion of “Non-Interpretable” topics is slightly higher for topics trained on the NE corpus, while the topics trained on the same corpus are proportionally lower for “Interpretable” topics. Panel B shows a more complicated picture. First, the coders indicate that for the models trained on RemovedNE corpora, significantly more topics required exactly 0 words to be removed. Next, the results show that around 35% of all topics required one word to be removed (the difference is negligible for the two different sets of corpora). However, for every subsequently deleted word, the proportion is slightly higher for the models trained on the NE corpus. This is especially evident for topics that required 2 through 5 words to be deleted.
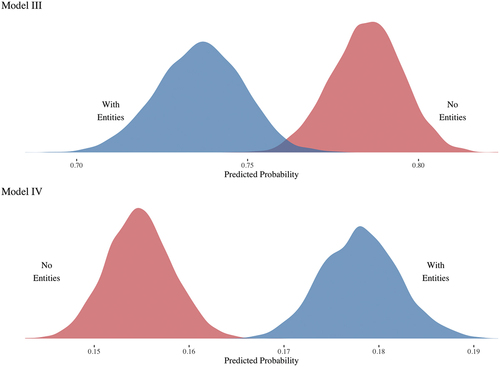
We estimate two separate models ( for both models) – one for the probability of a topic being judged “interpretable” by the crowdsourced coders depending on whether the model was trained on NE or RemovedNE corpus (Model III), and one for the probability of an additional word to be removed in order to make the topic “coherent” depending on whether the model was trained on NE or RemovedNE corpus (Model IV). Model III is a simple Bernoulli regression model with varying intercepts on individual coders. Model IV is a Binomial regression model also with varying intercepts on individual coders. Both models had weakly informative priors, their estimated parameters had
values of 1, indicating good convergence (Gelman & Rubin, Citation1992; Vehtari et al., Citation2021). shows the model outcomes.
Table 3. Bernoulli model results predicting probability of a topic model to be judged as “interpretable”.
The values presented are posterior log-odds from a Binomial model. 95% Credibility Intervals are presented in brackets.
presents posterior predictive probabilities (inverse logit of model parameters) for Models III and IV. As can be evident from and , topics estimated on RemovedNE corpora are more likely to be judged as “interpretable” by crowdsourced coders than those trained on NE corpora (Model III). Furthermore, Model IV indicates that topic models trained on the NE corpus are more likely to have additional words removed from the top-10 list in order to make the topic “interpretable.” As a robustness check, we have estimated a model exact in specifications to Model IV, but only on the subset of topics that were deemed “interpretable” (). The general pattern stays the same as in Model IV – topic models trained on NE corpora on average require more words to be removed than those trained on RemovedNE (Posterior predicted probabilities:
,
).
Figure 8. Posterior predicted probabilities of “interpretable” topics (panel A) and predicted binomial probabilities for an additional word to be removed (panel B) for models trained on NE and removed NE Corpora.
We now turn to the investigation of the effects of the position of words in the top-10 list on the “intrusion value” of the word. As explained earlier, the participants were presented with a list of top-10 words per topic and were asked to determine whether the topic is “interpretable.” They also had an opportunity to indicate which words they would remove from the list in order to make the topic “interpretable.”
We believe this investigation is important because it shows how word position influences the participants’ decision to enhance topic interpretability and would therefore be indicative of how Named Entities are treated in the context of word-removal tasks. If Named Entities are removed with a higher probability than non-NE words, this would indicate that they are more likely to be “intruders” in the topic model output, providing more rationale for removing NEs from the corpus to increase the interpretability of the topic model output.
In this section, we look only at the models that have been trained on the NE corpora (). The data were stacked by word position and by the type of word (NE/Non-NE), resulting in
observations (word position, word type, removed/non-removed triplets). We once again estimate a Bernoulli model with varying intercepts on individual coders (Model V) with the binary variable (word removed/not removed) as the dependent variable, and the position of the word in the top-10 list and word type (NE/Non-NE) as independent variables. Additionally, the model had an interaction effect word position
word type to understand the effect Named Entities have on the probability of a word being removed. The model had weakly informative priors, its estimated parameters had
values of 1, indicating good convergence. (Panel A) shows the conditional interaction effect of the model. The model outcomes are presented in .
Figure 9. Panel (A): conditional effect of interaction of word position and word type on the probability of a word being removed from the top-10 list. Panel (B): proportion of words removed from the top-10 list by word position and word type.
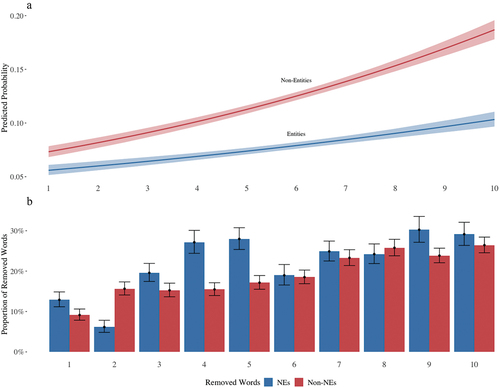
Table 4. Bernoulli model results predicting probability of a word being removed depending on its position and type.
The values presented are posterior log-odds from a Binomial model. 95% Credibility Intervals are presented in brackets.
The results indicate that the probability of a word being removed from the top-10 list increases with its position in the list. This is in line with expectations, since the list is, by definition, ordered by the probability of a word to belong to a certain topic; thus, the lower the probability (lower down the list), the higher the chance that it doesn’t belong. The effect of the word type (NE/Non-NE) is also positive, indicating that Named Entities are more likely to be removed from the top-10 list than non-Named Entities. This is, however, not very surprising since there are simply more non-named entity words in the topic model output. The interaction effect of the word type and position is also positive, indicating that the effect of the word type on the probability of a word being removed increases with its position in the list. The interaction effect is, in our opinion, the most interesting result of the model. The fact that the effect of the word type on the probability of a word being removed increases with its position in the list indicates that the participants are more likely to remove Non-NE words from the end of the word list rather than from the beginning. Nevertheless, this tendency is much less pronounced for NE words, which, in turn, indicates that the participants have more uniform preferences for NE words removal across the word list. Or, in other words, word intrusion probability of NE words is more uniformly distributed across the top-10 list than that of non-NE words.
This is also evident from (Panel B), which presents the proportion of words removed from the top-10 list by word position normalized by word type (i.e., out of all NEs presented to participants at position 1, how many were removed, and so on and so forth). As can be seen from the figure, the proportion of NE words removed from the top-10 list is higher than that of non-NE words. And while the proportion of removed Non-NEs get higher to the end of the list, the proportion of removed NEs is more or less uniform across the list. This is in line with the results of the model. Thus, NE words are “polluting” the list more uniformly than non-NE words, which, in turn, makes the topic less interpretable, since one of the frequent type of topic modeling validation methods is the manual inspection of the top words per topic (e.g., Maier et al., Citation2018).
Thus, the results based on the two experiments indicate that, in both cases, topic models are generally judged to be more “interpretable” when Named Entities are removed from the corpus beforehand. Interestingly enough, the experts that deal with topic modeling in their work, on average tend to judge a similar proportion of topic models to be interpretable (68%) to the coders from the crowdsourced experiment (70%). Nevertheless, the difference between NE and RemovedNE topics is more pronounced for the expert coders ( difference in predicted probability) than for the crowdsourced coders (
difference in predicted probability). Furthermore, looking at the distribution of the proportion of deleted (“intruding”) words based on the position in the top-10 list, we see that the NE words are more uniformly intruding in comparison to Non-NE words.
In the next section, we discuss the implications of these findings on topic modeling estimation.
Discussion and conclusion
The current study aimed to understand the effects of Named Entities – specifically, their retention or removal from the corpus – on topic modeling estimations and the interpretation of TM outcomes. Much attention is paid to pre-processing text corpora for further analysis; in particular removal of stopwords, lemmatizing, removal of in/frequently used terms, etc., are often thought of as important steps in the analysis of text data (Denny & Spirling, Citation2017). Nevertheless, to the best of our knowledge, there have been no attempts to systematically investigate how Named Entities influence topic models. Yet there are good reasons to assume the role of NEs in TMs for substantial communication research questions. To this end, the paper attempted to see whether a binary decision to include/exclude Named Entities influenced a) the structural characteristics of the models and b) the perception of the model output by humans.
In a semi-Monte-Carlo approach, 30 pairs of identical text corpora were created, with the only difference being that one set retained the Named Entities, while they were removed from the other. The first step was to understand whether this pre-processing decision has any impact on the number of “recommended” or optimal topics to be estimated. The RemovedNE set of corpora produced, on average, a higher number of “optimal” topics than the NE set. We argue that this may be a direct effect of Named Entities and not simply a function of corpora reduced in size. If the reduction of terms were the only effect at play here, one would rather expect lower than the NE corpora, but we see the opposite. This effect already arguably shows that removing/retaining NEs is an important pre-processing step that people should think about when preparing texts for topic modeling since the interpretation of the topic model output is rather sensitive to the initial
that was chosen. For example, in the same corpus lower
would presuppose more “general” topics, while higher
would presuppose more granular topics, which would affect both the clustering and the interpretation of texts.
Based on the “optimal” from both sets, we decided to estimate topics models with
(as the middle ground between the two), thus resulting, once again, in two sets of topic models, 30 models each, with a single distinction that one set was trained on the RemovedNE and the other on the NE sets of corpora. To further investigate the potential structural differences, we calculated the Semantic Coherence and Exclusivity of topics in both sets of models. These measures are very popular ways of determining the quality of topics in a model. Both measures were higher (i.e., higher “quality” of topics) for models trained on the RemovedNE corpora. Once again, this result points to a significant structural difference in the models and provides more evidence that removing/retaining Named Entities introduces non-trivial differences. However, since Exclusivity and Semantic Coherence are rather synthetic measures of topic quality, these differences are difficult to gauge from a real-world perspective. A much more important indicator would be whether humans actually notice a qualitative difference.
Both sets of trained topic models were used for two separate experiments. The first experiment involved 5 experts who deal with topic modeling methods professionally, while the second experiment employed crowdsourced coders. In both experimental settings, the subjects were asked about the quality of the topic model presented. Specifically, they were asked whether the topic was “interpretable.” The question was intentionally left vague since it is not immediately clear what qualities constitute a “high-quality topic.” This ambiguousness is further shown to be true by a moderate Krippendorff’s for the expert coders, indicating that the concept may mean different things to different people. In the case of the second experiment, the coders were also asked which words (if any) should be removed for the presented topic to become “interpretable.” This points to the larger problem of interpreting topic models simply based on top word lists. For an actual application it would probably be wise to consider additional points of reference for assessing the generated topics such as including sample documents (Maier et al., Citation2018). The results of both experiments show evidence that both the experts and the crowdsourced coders on average agree that the “interpretability” of a given topic is, at least to some extent, a function of the presence/absence of Named Entities. Experts and crowdsourced coders allocate a similar proportion of all topics as “interpretable,” however, the differences between topics trained on RemovedNE and NE corpora are more pronounced for the crowdsourced coders. Furthermore, the second experiment additionally showed that topics trained on NE corpora are more likely to need more words to be removed from the top-10 list to be interpreted as “interpretable” than those trained on RemovedNE corpora.
The results of this study indicate that Named Entities do indeed matter for topic modeling applications. They matter in both the structural, and intrinsic characteristics of the models themselves and the perception of the model output by humans. A single one of these two aspects is enough to change how researchers approach topic modeling applications and the interpretation of results. Our results suggest that semantic coherence and exclusivity are indeed aligned with human perception of the interpretability of estimated topics. Removing NE in news corpora also appears to improve the interpretability of topics in human judgment.
Paraphrasing the famous quote by George Box “all topics are wrong, but some are useful,” underscores the essential role of one’s interpretation and grasp of what truly constitutes a topic in determining its usefulness. This theoretical question has significant implications for the practical choice of the model (and the decisions that are made in the model estimation). This is somewhat reflected in the thought that there is no single model that completely represents text (e.g., Grimmer et al., Citation2022). Moreover, unlike more orthodox methods of data analysis, like regression models, where the researcher assumes a specific data-generating process and attempts to model it, topic modeling is an inherently inductive approach, where assumptions about a specific distribution that has generated the text data are inappropriate. All of these considerations compound making rigid, recipe-like suggestions about how to analyze text with topic models.
There are several other possible scenarios where removing NEs from the corpus is strongly advisable, or even crucial, for obtaining unbiased and meaningful results. Counter-intuitively, this becomes more crucial when Named Entities are not simply noise in the text, but actually a signal. One such scenario arises when comparing how two different sets of text diverge in their coverage of topics. If one set of texts contains a higher prevalence of Named Entities, these entities could inadvertently dominate certain topics, skewing the comparison. For instance, news articles about celebrities might heavily feature person names, which could lead to a biased representation of topics if Named Entities are not removed. By excluding Named Entities during pre-processing, researchers can ensure a fairer comparison between the topics emerging from different text sources.
Another example of when removing Named Entities becomes important is the possibility of inadvertently selecting on the dependent variable. This may for instance occur if the researcher is interested in coverage of a political party or a political candidate (e.g., what topics are more associated with the candidate), or agenda-setting dynamics. Not removing Named Entities in this scenario can lead to biased results since the model may overemphasize the topics connected to Party X. If Party X frequently talks about e.g., healthcare, education, and the economy, these topics might get grouped into a single Party X-dominated topic. Even if Party Y and Party Z also discuss these topics, the model might emphasize the Party X-dominated topic, assuming it’s a dominant theme in all speeches.
All of these considerations once again point to the idea that the default approach should indeed be to remove Named Entities, as it often leads to more accurate and insightful results. Stripping away Named Entities ensures that the identified topics are rooted in the intrinsic content of the text, free from the influence of specific names, brands, or entities that might disproportionately affect the outcomes. This approach aligns with the fundamental goal of topic modeling: to uncover latent thematic structures within the corpus.
Additionally, our results reveal that participants exhibited a consistent tendency to remove Non-NE words predominantly from the list’s end. However, this inclination was notably less pronounced for NE words, suggesting a more uniform removal pattern. This unique behavior has significant implications for topic interpretability. Our analysis demonstrated that NE words are uniformly distributed throughout the top-10 list, creating a consistent “pollution” effect. This uniformity signifies that NEs impact the list’s coherence consistently, making topics less interpretable. Given the common practice of validating topic models through manual inspection of top words, these findings underscore the importance of NEs in topic modeling output.
Nevertheless, there are scenarios where Named Entities carry crucial significance, and omitting them could lead to a loss of essential information. For instance, in analyzing political speeches, the names of politicians or specific organizations might be essential entities representing different viewpoints. Similarly, in studying sentiment analysis in customer reviews, brand names are integral to understanding consumer opinions accurately. In such instances, retaining Named Entities becomes imperative, as they directly contribute to the research question or topic under investigation.
Unfortunately, due to the nature of topic modeling, there is no way around the “polluting” effect of NEs on topic modeling output in situations where removing NEs from the corpus is not an option. Nevertheless, there are several potential ways researchers can mitigate this effect on topic model output interpretability. For instance, after obtaining the topic model output, researchers can use post-processing to help with interpreting the output. After obtaining the topic model output, they can create a custom stop-words list that removes Named Entities from the output (and not from the corpus itself). This will ensure that Named Entities are not polluting the output increasing the interpretability of topics, but will retain the implicit correlations between Named Entities and other words in the corpus. This nuanced approach ensures that the interpretability of topics is enhanced while still allowing for the classification of documents based on topics, even those rich in Named Entities.
Moreover, researchers can further extend their post-processing by using techniques such as co-occurrence analysis. By examining the contextual relationships between NEs and other words within the corpus, researchers can identify and preserve meaningful correlations. This nuanced understanding of word associations would allow researchers to refine the post-processed output, ensuring that NEs are neither entirely removed nor arbitrarily retained. Instead, these entities can be strategically incorporated into the interpretative framework.
However, this approach to measurement demands careful consideration and robust justification. Researchers must articulate why Named Entities are left in the dataset, detailing how these entities enhance the analysis and contribute to the research objectives. Transparent justifications not only validate the methodological choices made but also enhance the credibility and reproducibility of the research findings, ensuring that the measurement of topics is both accurate and contextually meaningful.
There are also several limitations that are associated with this study that should be addressed. The first limitation is the fact that the current study used a rather superficial criterion for the topic quality, namely its interpretability. While this allowed for a very broad description of the task, especially relating to the crowdsourced experiment, without overburdening the coders with a large number of criteria and multiple definitions of “quality,” this still leaves a lot of room for future researchers to investigate. Topic quality and validation remain a difficult and an ongoing question in related research (e.g., Doogan & Buntine, Citation2021; Grimmer et al., Citation2022; Grimmer & Stewart, Citation2013; Lau et al., Citation2014, etc.). The approach taken in this paper reflects that there is no “ground-truth” when it comes to text modeling (Grimmer et al., Citation2022), various conceptualizations may be valuable for different tasks in mind. This study assumes a rather simplified definition of “interpretability” (i.e., whether a cluster of words indicates a latent topic). While this is a necessary step in interpreting the output of a topic model, it is only one of the indicators. The next steps would be to look into whether and or how specific aspects of topic quality are influenced by the Named Entities, including a more fine-grained definition of “interpretability,” or “usefulness” of a topic. A qualitative study, where participants are prompted to provide in-depth descriptions of what specifically makes a topic “interpretable” could be a good starting point.
The second limitation of this study is that it does not explore the potential influence of specific factors on the effects of removing Named Entities on topic modeling interpretability. Factors such as content/source characteristics (e.g., tabloid vs. quality newspapers), time periods, etc., could play a role in shaping the outcomes. By not considering these factors, our study does not provide a comprehensive understanding of how the removal of Named Entities might interact with these variables and potentially modify the interpretability of topic modeling results. While we have attempted to provide a broad overview of the effects of Named Entity removal for Topic Model evaluation, future research should address this limitation by investigating the nuanced effects of these factors to gain a more nuanced understanding of the impact of named entity removal on topic modeling interpretability.
And finally, it is important to acknowledge that our research focused on the general presence of Named Entities within textual data, without distinguishing between different types such as persons, locations, organizations, and others. This broad categorization, while necessary for the scope of our study, presents a limitation in terms of topic interpretability. Named Entities encompass a wide array of information, ranging from individual names to specific geographic locations and organizational titles. Failing to differentiate between these distinct categories might result in topics that lack specificity and depth. For instance, a topic might include a mix of person names, locations, and organizations, leading to challenges in pinpointing the precise theme the topic represents. This limitation impacts the granularity of our findings. However, our study aimed to provide a foundational understanding of Named Entities’ influence on topic modeling in a broader context. While this limitation affects the depth of our interpretations, it also highlights an area for future research, where the nuances of various named entity types can be explored more comprehensively.
Nevertheless, notwithstanding the abovementioned limitations, if we were to formulate suggestions for the topic modeling practitioners based on the results of the current study, it would be one guideline: without any prior expectations, the default decision when pre-processing text for topic models should be the removal of Named Entities. Similar to the decisions about removing stopwords or lemmatizing words that are, more or less, automatic, removing Named Entities should be the default, too. Qualifying this statement, we would like to emphasize that obviously not every instance of topic model use should necessarily be estimated on a corpus that has the Named Entites removed (just like not always one removes stopwords or lematizes words). A large portion of applications in the communication and political sciences actually require Named Entities for the concept that they are trying to measure. However, in these instances, in our opinion, researchers should justify why Named Entities are required for their particular task at hand. An additional benefit of this approach would not only be more transparent reasoning on the trade-off of the model being more “interpretable” vs. more accurately capturing the quantity of interest, but also this additional transparency would be helpful to the readers as to better understand what exactly the authors intend to capture with topic models and provide more clarity on the estimated of interest.
We believe that the current study provides valuable insight into topic modeling estimation – specifically the impact of Named Entities on structural and qualitative characteristics of topic models. Importantly, the current paper stresses the importance of another step in dealing with raw text that is not very often thought of, but that turns out to have non-trivial consequences. It is evident that removing Named Entities from the text is an effective way to increase the topic’s interpretability. Obviously, the decisions taken should always depend on the task and the context at hand, but if we think of text processing as a problem of measurement, this step could play a significant role in how well we are able to extract meaning from the raw text. Researchers employing the topic modeling methodology should reflect on these decisions and be explicit about their choices when designing their studies.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Notes on contributors
Petro Tolochko
Petro Tolochko is a postdoctoral researcher at the Department of Communication at the University of Vienna.
Paul Balluff
Paul Balluff is a doctoral student at the Department of Communication at the University of Vienna.
Jana Bernhard
Jana Bernhard is a doctoral student at the Department of Communication at the University of Vienna.
Sebastian Galyga
Sebastian Galyga is a doctoral student at the Department of Communication at the University of Vienna.
Noëlle S. Lebernegg
Noëlle S. Lebernegg is a doctoral student at the Department of Communication at the University of Vienna.
Hajo G. Boomgaarden
Hajo G. Boomgaarden is a Professor of Empirical Social Science Methods at the University of Vienna.
Notes
1 The model used was en_core_web_lg; the score for Named entity recognition is .85.
2 Due to the computational intensity of estimating 60 separate topic models (30 with NEs and 30 without) we focus on models (as a middle value from the spectral initialization step described earlier).
3 Simple searchstrings were used to filter the texts. sport*|football|soccer|tennis|basketball|baseball for “Sports,” polit*|govern*|vote*|president* for “Politics,” econom*|business*|corporat*, scien*|health* for “Science,” and celebrit*|cultur*|movie* for “Celebrity.” This is obviously a very simplified way of searching for the general theme, and should not be indicative of a real empirically-driven study. However, we believe this level of simplification is suitable for our purposes of demonstration.
References
- Bischof, J., & Airoldi, E. M. (2012). Summarizing topical content with word frequency and exclusivity. Proceedings of the 29th International Conference on Machine Learning (ICML-12), 201–208. Edinburgh Scotland.
- Boukes, M., & Vliegenthart, R. (2020). A general pattern in the construction of economic newsworthiness? analyzing news factors in popular, quality, regional, and financial newspapers. Journalism, 21(2), 279–300. https://doi.org/10.1177/1464884917725989
- Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M., Guo, J., Li, P., & Riddell, A. (2017). Stan: A probabilistic programming language. Journal of Statistical Software, 76(1). https://doi.org/10.18637/jss.v076.i01
- Chang, J., & Blei, D. (2009). Relational topic models for document networks. In D. van Dyk & M. Welling (Eds.), Proceedings of the twelth international conference on artificial intelligence and statistics (pp. 81–88). Florida, USA.
- Chang, J., Gerrish, S., Wang, C., Boyd-Graber, J. L., & Blei, D. M. (2009). Reading tea leaves: How humans interpret topic models. Advances in Neural Information Processing Systems, 288–296. Vancouver, B.C., Canada.
- Denny, M., & Spirling, A. (2017 (September 27, 2017). Text preprocessing for unsupervised learning: Why it matters, when it misleads, and what to do about it. When It Misleads, and What to Do About It, https://doi.org/10.2139/ssrn.2849145
- Doogan, C., & Buntine, W. (2021). Topic model or topic twaddle? re-evaluating semantic interpretability measures. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 3824–3848.
- Eberl, J.-M., Boomgaarden, H. G., & Wagner, M. (2017). One bias fits all? three types of media bias and their effects on party preferences. Communication Research, 44(8), 1125–1148. https://doi.org/10.1177/0093650215614364
- Gelman, A., & Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences. Statistical Science, 7(4), 457–472. https://doi.org/10.1214/ss/1177011136
- Grimmer, J., Roberts, M. E., & Stewart, B. M. (2022). Text as data: A new framework for machine learning and the social sciences. Princeton University Press.
- Grimmer, J., & Stewart, B. M. (2013). Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Analysis, 21(3), 267–297. https://doi.org/10.1093/pan/mps028
- Grusky, M., Naaman, M., & Artzi, Y. (2018). Newsroom: A dataset of 1.3 million summaries with diverse extractive strategies. arXiv Preprint arXiv: 180411283.
- Honnibal, M., & Johnson, M. (2015). An improved non-monotonic transition system for dependency parsing. Proceedings of the 2015 conference on empirical methods in natural language processing, 1373–1378. Lisbon, Portugal.
- Hoyle, A., Goel, P., Peskov, D., Hian-Cheong, A., Boyd-Graber, J., & Resnik, P. (2021). Is automated topic model evaluation broken?: The incoherence of coherence. arXiv Preprint arXiv: 210702173.
- Hudson, R. (1994). About 37% of word-tokens are nouns. Language, 70(2), 331–339. https://doi.org/10.2307/415831
- Hu, L., Li, J., Li, Z., Shao, C., & Li, Z. (2013). Incorporating entities in news topic modeling. In G. Zhou, J. Li, D. Zhao, & Y. Feng, Eds. Natural language processing and Chinese computing. (pp. 139–150). Springer: 14. https://doi.org/10.1007/978-3-642-41644-6.
- Jacobi, C., & K¨onigslo¨w, K.-K.v., & Ruigrok, N. (2016). Political news in online and print newspapers. Digital Journalism, 4(6), 723–742. https://doi.org/10.1080/21670811.2015.1087810
- Krasnashchok, K., & Jouili, S. (2018). Improving topic quality by promoting named entities in topic modeling. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 247–253. https://doi.org/10.18653/v1/P18-2040
- Kripke, S. A. (1972). Naming and necessity. In D. Davidson & G. Harman (Eds.), Semantics of natural language (pp. 253–355). Springer.
- Kuhr, F., Lichtenberger, M., Braun, T., & M¨oller, R. (2021). Enhancing relational topic models with named entity induced links. 2021 IEEE 15th International Conference on Semantic Computing (ICSC), 314–317. https://doi.org/10.1109/ICSC50631.2021.00059
- Kumar, D., & Singh, S. R. (2019). Prioritized named entity driven LDA for document clustering. In B. Deka, P. Maji, S. Mitra, D. K. Bhattacharyya, P. K. Bora, & S. K. Pal (Eds.), Pattern recognition and machine intelligence (pp. 294–301). Springer International Publishing. https://doi.org/10.1007/978-3-030-34872-433
- Lau, J. H., Newman, D., & Baldwin, T. (2014). Machine reading tea leaves: Automatically evaluating topic coherence and topic model quality. Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, 530–539. Gothenburg, Sweden.
- Liang, J., & Liu, H. (2013). Noun distribution in natural languages. Poznań Studies in Contemporary Linguistics, 49(4), 509–529. https://doi.org/10.1515/psicl-2013-0019
- Lundberg, I., Johnson, R., & Stewart, B. M. (2021). What is your estimand? defining the target quantity connects statistical evidence to theory. American Sociological Review, 86(3), 532–565. https://doi.org/10.1177/00031224211004187
- Maier, D., Waldherr, A., Miltner, P., Wiedemann, G., Niekler, A., Keinert, A., Pfetsch, B., Heyer, G., Reber, U., H¨aussler, T., Schmid-Petri, H., & Adam, S. (2018). Applying lda topic modeling in communication research: Toward a valid and reliable methodology. Communication Methods and Measures, 12(2–3), 93–118. https://doi.org/10.1080/19312458.2018.1430754
- Marrero, M., Urbano, J., Sanchez-Cuadrado, S., Morato, J., & Gomez-Berbis, J. M. (2013). Named entity recognition: Fallacies, challenges and opportunities. Computer Standards and Interfaces, 35(5), 482–489. https://doi.org/10.1016/j.csi.2012.09.004
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems, 3111–3119. Lake Tahoe, Nevada, USA.
- Mimno, D., & Lee, M. (2014). Low-dimensional embeddings for interpretable anchor-based topic inference. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1319–1328. Doha, Qatar.
- Mimno, D., Wallach, H., Talley, E., Leenders, M., & McCallum, A. (2011). Optimizing semantic coherence in topic models. Proceedings of the 2011 conference on empirical methods in natural language processing, 262–272. Edinburgh, Scotland, UK.
- Nadeau, D., & Sekine, S. (2007). A survey of named entity recognition and classification. Lingvisticae Investigationes, 30(1), 3–26. https://doi.org/10.1075/li.30.1.03nad
- Nouvel, D., Ehrmann, M., & Rosset, S. (2016). Named entities for computational linguistics. John Wiley & Sons, Inc. https://doi.org/10.1002/9781119268567
- Rehurek, R. & Sojka, P. (2011). Gensim—statistical semantics in python. Retrieved from Genism
- Rijcken, E., Kaymak, U., Scheepers, F., Mosteiro, P., Zervanou, K., & Spruit, M. (2022). Topic modeling for interpretable text classification from ehrs. Frontiers in Big Data, 5. https://doi.org/10.3389/fdata.2022.846930
- Roberts, M. E., Stewart, B. M., & Tingley, D. (2019). Stm: An r package for structural topic models. Journal of Statistical Software, 91(1), 1–40. https://doi.org/10.18637/jss.v091.i02
- Roberts, M. E., Stewart, B. M., Tingley, D., Lucas, C., Leder-Luis, J., Gadarian, S. K., Albertson, B., & Rand, D. G. (2014). Structural topic models for open-ended survey responses. American Journal of Political Science, 58(4), 1064–1082. https://doi.org/10.1111/ajps.12103
- Sievert, C., & Shirley, K. (2014). Ldavis: A method for visualizing and interpreting topics. Proceedings of the workshop on interactive language learning, visualization, and interfaces, 63–70. Baltimore, Maryland, USA.
- Taddy, M. (2012). On estimation and selection for topic models. In Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics. La Palma, Canary Islands.
- Vehtari, A., Gelman, A., Simpson, D., Carpenter, B., & Bu¨rkner, P.-C. (2021). Rank-normalization, folding, and localization: An improved r for assessing convergence of mcmc (with discussion). Bayesian Anal- Ysis, 16(2), 667–718. https://doi.org/10.1214/20-BA1221
- Ying, L., Montgomery, J. M., & Stewart, B. M. (2021). Topics, concepts, and measurement: A crowdsourced procedure for validating topics as measures. Political Analysis, 30(4), 570–589. https://doi.org/10.1017/pan.2021.33