
ABSTRACT
Named Entity Recognition (NER) is a crucial task in natural language processing and has a wide range of applications in communication science. However, there is a lack of systematic evaluations of available NER tools in the field. In this study, we evaluate the performance of various multilingual NER tools, including rule-based and transformer-based models. We conducted experiments on corpora containing texts in multiple languages and evaluated the F1-score, speed, and features of each tool. Our results show that transformer-based language models outperform rule-based models and other NER tools in most languages. However, we found that the performance of the transformer-based models varies depending on the language and the corpus. Our study provides insights into the strengths and weaknesses of NER tools and their suitability for specific languages, which can inform the selection of appropriate tools for future studies and applications in communication science.
Introduction
Actors, organizations, and locations are at the heart of news coverage and finding them in texts is a standard task in content analysis (Boumans & Trilling, Citation2016). While manual coding of actors is typically accurate and reliable, it consumes valuable resources for large amounts of data (van Atteveldt et al., Citation2021). With the help of computational methods, however, researchers can find and extract actors in texts at a large scale, either by composing more or less complex search terms or by employing named entity recognition (NER) algorithms. In deductive approaches, the former technique is often used for querying large text archives and selecting texts based on the occurrence of specific actors (e.g., Kruikemeier et al., Citation2018). For research questions of an inductive nature, NER tools are applied to an existing corpus in order to extract actors, locations, or organizations at large scale (e.g., Welbers et al., Citation2018). Regardless of an inductive or deductive research design, researchers can use the results of NER to perform more complex analysis, such as measuring sentiments toward political actors (e.g., Fogel-Dror et al., Citation2019; Turcsányi et al., Citation2019), linking documents based on actors (e.g., Lind et al., Citation2021), or exploring networks of actors (e.g., Traag et al., Citation2015). NER is not only relevant for actor-centric sampling strategies, but also for issue-centric research designs, where text archives are sampled according to issues for which involved actors are not known beforehand. For example, for a study investigating the reporting on climate change during the past decades, a researcher could sample the texts based on key words related to climate change, and then use NER to identify key actors associated with the issue.
While there is a large variety of NER tools available, these have several shortcomings. First, the majority of available tools is optimized for English texts, and their counterparts for other languages typically perform less well (Baden et al., Citation2022). Second, NER tools are often trained and validated against corpora from specific domains, but then are applied across domains or text genres. Third, most tools perform NER at the surface level, meaning that they are not able to resolve coreferences or disambiguate named entities automatically.
NER has advanced significantly in recent years with the development of neural networks and transformer models (Devlin et al., Citation2018). These models have shown impressive performance across various languages and text domains, including news texts and social media contents (Joshi et al., Citation2019; Pires et al., Citation2019; Scheible et al., Citation2020). Despite this progress, these modern techniques have not yet been widely adopted by communication researchers, who often analyze texts in these genres. So far, no recent study has systematically compared and reviewed the available multilingual techniques for NER in the social sciences (Nadeau & Sekine, Citation2007; Steinberger & Pouliquen, Citation2007).Footnote1 This is particularly important for communication researchers, as they often work with specific text genres and domains. It is essential to evaluate the performance of NER tools in these domains to understand their validity and limitations.
Additionally, domain differences can significantly impact the performance of NER tools, and so it is crucial to evaluate the tools with regard to domain differences. While some tools might perform well across various domains, others might struggle to identify entities accurately in certain text genres or domains. Therefore, a systematic comparison of multilingual NER tools across various languages and text domains is necessary to facilitate the development of more effective NER techniques and support research in the social sciences.
In this article, we first take stock of NER tools that are currently in use in the social sciences and look at their validation practices. We base our review on the work by Baden et al. (Citation2022) who manually surveyed 854 publications in the top 20 journals in communication science, political science, sociology, and psychology between 2016 and 2020. We closely look at those 62 journal publications that, according to their study, had named entities as a variable of interest and employed some form of computational text analysis. In our review, we pay special attention to the specific NER tool used in each study, mentions of validation, analyzed languages, multilingual capabilities, as well as the purpose for using a NER tool – aspects which have not been inquired in the original review by Baden et al. (Citation2022).
Next, we gather the computational tools identified in the literature review and compare their performance according to a defined set of criteria. We evaluate the typical metrics (precision, recall, F1 score) against commonly available test corpora from different domains (see below). But we also assess “softer” criteria such as usability that are relevant for practitioners of content analysis.
With this performance evaluation, we contribute to the field by identifying gaps in current research practice and highlighting the advantages and disadvantages of currently available NER tools. Furthermore, we explore use cases and implementations for large language models with a transformer architecture to gauge their multilingual capabilities for NER.
NER in the social sciences
Named entities are widely understood as rigid designators for particular elements which exist in the world outside of language (Kripke, Citation1972). They rigidly identify persons or things, like the expression “Joe Biden” pointing at a specific person. Pragmatic consensus in computational linguistics established that named entities always entail persons, organizations, and locations (Nadeau & Sekine, Citation2007). However, this classic separation into three categories might not be sufficiently fine-grained for communication research. This is because, “actors” are not only individual persons, but also collective actors such as organizations, political parties, or companies. Geo-political entities can also function as actors when they are a synonym for governments as in “Tokyo bid to host the Olympic Games.” “Tokyo” as place clearly cannot have this kind of agency, but as a reference to their administration it can (Nouvel et al., Citation2016). Furthermore, from a broader perspective, actors do not have to be confined to social beings. Other kinds of named entities are also relevant for communication research, such as legal constructs (“the Geneva Convention”), global events (e.g., “the pandemic”), demonyms (e.g., “the French”), infrastructure projects (e.g., “Nord Stream 2”), or even products and services (e.g., “iPhone”).
In many applications, the extraction of a named entity is sufficient at the document level, such as identifying whether an actor is mentioned at least once in a news article (e.g., Vliegenthart et al., Citation2011). However, for more detailed analysis at the paragraph or sentence level, coreference resolution is desired, because it links pronouns and definite descriptors to mentioned named entities (Nouvel et al., Citation2016). This allows tracking the entity through subsequent sentences and is crucial for identifying semantic relationships (e.g., Fogel-Dror et al., Citation2019). Finally, disambiguation (or entity classification) is important to distinguish the types of named entities (e.g., “Washington” can refer to a president, a state, or a city).
shows that six of the reviewed publications used a collection of manually composed search terms to sample documents according to actors. With 16 publications, dictionaries are the most commonly used approach for finding actors (e.g., Grill & Boomgaarden, Citation2017). Dictionaries and collections of search terms are often hand-crafted and highly specialized toward the corresponding research question, such as finding specific politicians (e.g., Gattermann, Citation2018), experts (e.g., Merkley, Citation2020), company names (e.g., Jonkman et al., Citation2020), social groups (e.g., Lee & Nerghes, Citation2018), or demonyms (e.g., Walter & Ophir, Citation2019). While this brings the advantages of simplicity and flexibility, these dictionaries can rarely be reused for other research tasks. Exceptions are large-scale general-purpose dictionaries that were semi-automatically created, such as the JRC-Names (Steinberger et al., Citation2011) with over 850,000 entries or the Integrated Crisis Early Warning System (ICEWS) by Boschee et al. (Citation2015). However, the more actors a dictionary covers, the more editorial effort is required in its creation. They also cannot disambiguate entities well, and they lack the capability of resolving coreferences. Furthermore, they also follow a deductive logic and thus, do not find previously unknown actors in texts.
Table 1. Most commonly used techniques for named entity recognition (based on literature review).
Even though approaches based on supervised machine learning tend to perform better, resolve coreferences and are able to disambiguate well, they were used in only eight publications. For example, five of the reviewed papers used the built-in NER tool of CoreNLP (Fogel-Dror et al., Citation2019; Martin & McCrain, Citation2019). Burggraaff and Trilling (Citation2020) trained a custom classifier using the Python Natural Language Toolkit (NLTK) with the help of the Dutch CoNLL Corpus (Tjong Kim Sang & De Meulder, Citation2003). Apache OpenNLP is another library for a series of NLP tasks which Nardulli et al. (Citation2015) used for extracting named entities from texts and connecting them with sentiments. However, such supervised methods also require a large human-annotated corpus for training purposes. There are also several neural network libraries publicly available, such as spaCy (Honnibal et al., Citation2020). They can perform a variety of NLP tasks, including NER and coreference resolution and tend to generalize well (e.g., Hopp et al., Citation2020). Additionally, there are also ready-to-use cloud solutions such as IBM Watson as employed by Scott et al. (Citation2020).
It should be noted here that none of the publications gave explicit reasons for choosing one NER tool over the other. Which means, that for example, the publications that used CoreNLP did not state why they chose this particular tool over NLTK or OpenNLP.
Among the reviewed articles, 34 analyzed English texts, followed by Dutch as second with 13 publications. Arabic, Chinese, German, as well as French texts were also analyzed, but to a much smaller extent. Also, while most of the aforementioned tools often allow processing of texts in a variety of languages such as German, French, Dutch, or Chinese, they perform significantly better for English. The overall gap for tools that perform well on non-English texts is a current challenge for researchers who conduct automated content analysis more generally (Baden et al., Citation2022).
Nevertheless, new frontiers in computing (Vaswani et al., Citation2017) brought the rise of large language models that can process astronomical amounts of text data and have billions of parameters (Devlin et al., Citation2018). Among the large language models, the most common underlying design is the transformer architecture. There is a fairly large variety of transformer models including single-language models (e.g., Scheible et al., Citation2020) and large multilingual models (e.g., Conneau et al., Citation2019). Unlike previous techniques, these large language models are pre-trained with minimal supervision, where they are presented with millions of automatically generated training unites. For example, one of the tasks is a fill-in-the-blank exercise, where in each training sample, one token is masked from the model and the model has to predict which token is supposed to be in the masked position. For example, the model is presented with the phrase “the capital of [MASK] is Paris” and it has to predict that “France” would be the answer for the masked token (Devlin et al., Citation2018).Footnote2 This process enables the use of extremely large amounts of training samples, because the tokens can be masked automatically with simple algorithms.
After the training procedure is completed, the model can then be fine-tuned for a particular task with a smaller amount of data. Fine-tuned transformer models tend to outperform other methods, and also to generalize well. This opens the possibility for researchers to manually annotate a comparatively small dataset and then leverage their pre-trained basic “language understanding” (Devlin et al., Citation2018). Their performance on NER, coreference resolution, and disambiguation is well-documented (e.g., Scheible et al., Citation2020), but these results only refer to laboratory conditions. None of the reviewed publications employed a NER tool with a transformer architecture. Because of their potential use cases for communication research, we include them in the performance evaluation.
Methodology & data
Evaluated NER tools
Based on the literature reviewed, we identified eight NER tools used for the social sciences with multilingual capabilities (see ). To represent dictionary-based methods, we use two publicly available resources. Both were built semi-automatically through rule based parsing and manual review. ICEWS can extract actors in 10 languages (Boschee et al., Citation2015). JRC-Names has an even higher coverage of 45 languages including non-Latin scripts such as Arabic, Chinese, or Japanese (Steinberger et al., Citation2011). However, both dictionaries come with the caveats that they have not been updated frequently and the algorithms for construction are not available. Moreover, they only cover persons and organizations. Nevertheless, they are suitable candidates for general purpose NER dictionaries with multilingual capabilities and come with the advantages and disadvantages outlined above.
Table 2. Comparison of tools according to features and speed.
We specifically exclude inductive dictionary composition methods that are based on extracting term frequencies (e.g., Al-Rawi, Citation2017), because they require a relatively large amount of editorial labor and they are usually not transferrable to other corpora. We also exclude Newsmap (Watanabe, Citation2017), since this tool is tailored for geographic document classification, and cannot extract named entities from texts. While IBM Watson appears to be a powerful tool as well, we will not include it in the comparison, because their services are not open to the public. We also exclude Frog, since it is a monolingual tool exclusively for Dutch (Van den Bosch et al., Citation2007).
All tested tools are open source and can be used free of charge. The only potential monetary costs of NER tools depend on computational requirements (see below).
For “classical” machine learning we use four different tools. Apache OpenNLP uses a Maximum Entropy model and is pre-trained for English, Dutch, and Spanish. NLTK (Bird et al., Citation2009) also implements a Maximum Entropy classifier, but only supports English out of the box. CoreNLP has an NER algorithm based on Conditional Random Fields enhanced with Gibbs Sampling and provides pre-trained models in Chinese, English, French, German, Hungarian, Italian, and Spanish (Finkel et al., Citation2005; Manning et al., Citation2014). Finally, we also benchmark nametagger which uses a Maximum Entropy Markov Model and is the only NER tool in our sample that provides a pre-trained model for Czech (Straková et al., Citation2013).
We are benchmarking two tools which are built with neural networks. First, the software package spaCy is partially open-source and offered by a commercial provider for industrial NLP applications. It provides models based on neural networks for Chinese, Dutch, English, French, and Spanish. It also includes models based on a transformer architecture, but these only support Chinese, English, Dutch, and German. To benchmark the potential performance of language models with transformer architecture, we include XLM-RoBERTa which covers 100 languages (Conneau et al., Citation2019).
Test corpora
We run the selected tools against a choice of freely available corpora that are geared toward evaluating the performance of NER tools in a variety of languages (see ; section B of the Appendix provides a detailed description for each corpus). We base our selection on the following criteria:
The corpus should be freely available for research purposes and their licensing should allow the redistribution of models trained with the data.Footnote3 This ensures replicability of our study and helps to advance further research.
The text type and domain should be related to communication research. For example, we exclude corpora that are specialized toward the recognition of proteins (Nouvel et al., Citation2016).
The corpus should increase the diversity of the test setup. Therefore, we intentionally selected monolingual and multilingual corpora to achieve a wide coverage of different languages, scripts, and text types for the evaluation.
Table 3. Selected corpora for NER performance evaluation.
We include six multi-lingual corpora in our evaluation. Note that none of them is a parallel corpus.Footnote4 The CoNLL corpora are the oldest released in the set and are considered to be a standard task in evaluating NER tools (Nouvel et al., Citation2016). They have four categories for named entities and are sampled from news wires (Tjong Kim Sang, Citation2002; Tjong Kim Sang & De Meulder, Citation2003). The AnCora corpus uses news wires as well, but in Spanish and Catalan, which can be considered to be a low-resource language (Taulé et al., Citation2008). The OntoNotes corpus covers three different scripts with Arabic, English, and simplified Chinese and is comprised of a mix of news texts, weblogs, talk shows and broadcast talks (Weischedel et al., Citation2013).
Scans of historical newspapers are the source for the Europeana Corpus (Neudecker, Citation2016) and HIPE Corpus (Ehrmann et al., Citation2020). The latter can be considered to be the follow-up project of the Europeana Corpus. Both are derived of the same materials, which are newspapers that were digitized using optical character recognition and then manually corrected and labeled. Some of these results are inaccurate and thus the data of this corpus is fairly noisy (Neudecker, Citation2016).Footnote5 Finally, the WikiANN Corpus was created with automated means by systematically querying the links of Wikipedia articles and their corresponding categories (Pan et al., Citation2017). This resulted in a silver-standard that is rich in sample size and covers 282 languages, from which we selected Arabic, Catalan, Chinese, Czech, Dutch, English, Finnish, French, German, Hungarian, Italian, Portuguese, and Spanish.
Additionally, we include nine monolingual corpora. The Second HAREM Resource Package “LÂMPADA” (hereinafter: HAREM) is rather small, but it contains Portuguese texts from various genres, such as news, education, blogs, legal, literary works, and advertisement (Mota & Santos, Citation2008). The AQMAR corpus (Mohit et al., Citation2012) is comprised of Arabic Wikipedia articles and fairly small as well. The Dutch SoNaR corpus is rather large and covers a broad variety of text genres (Oostdijk et al., Citation2013). The Czech Named Entity Corpus 2.0 (CNEC 2.0) (Ševčíková et al., Citation2014) and the German GermEval corpus (Benikova et al., Citation2014) are both comparatively large and are taken from news sources and Wikipedia articles. The Emerging Entities Corpus (Derczynski et al., Citation2017) contains texts created by Twitter users. Therefore, it contains misspellings, abbreviations, slang, and non-canonical named entities. While it contains a large number of tweets by private users, it also contains professionally produced tweets by organizations such as newspapers (Derczynski et al., Citation2017). The Finnish FiNER (Ruokolainen et al., Citation2020) uses news articles and is fairly small. The Kessler Italian Named-entities Dataset (KIND) (Aprosio & Paccosi, Citation2023; Paccosi & Aprosio, Citation2021) and the Hungarian NYTK-NerKor (Simon & Vadász, Citation2021) both cover multiple text genres and are relatively large.
All corpora together cover a variety of text types, scripts, languages, noise levels, and time periods. With this broad coverage, we can aim to create an encompassing evaluation.
Test setup
In order to ensure an equal benchmark for all NER tools, we aligned the corpora annotation schemes with each other. This was necessary because some corpora have broad categories and others are more fine-grained. For example, the CoNLL corpora use only 4 categories for named entities: persons, organizations, locations, and misc. Other corpora use 6, 18 or even up to 46 distinct categories for named entities. Moreover, the miscellaneous category has no standard definition across corpora and therefore, the corpora differ in their labeling schemes for this category. As a result, we reduced the categories to the original triad of persons, organizations, and locations.
Furthermore, the NER tools themselves also differ in their categories for named entities. Similarly, to the corpora some tools have 4 categories others have up to 25. This difference is mostly due to the corpora that were used for developing the tools. For example, the English NER model in CoreNLP was trained using the a mix of several corpora which results in 25 NE categories. Thus, the number of categories strongly depend on the training materials used for each NER tool. The two dictionaries (ICEWS and JRC Names) both only have two categories (persons and organizations), and they used rather vague definitions for their named entity categories. However, most tools were developed with compatibility for CoNLL annotation standards. This means that most tools share the same definitions for persons, organizations, and locations. Consequently, we also map the outputs of the tools to match the alignment that we applied for the corpora annotations.Footnote6
For our evaluation study, we define NER as a token classification task at the sentence level, where the NER tool has to detect which tokens comprise a named entity and label them accordingly to four categories: person, organization, location, or none.
We benchmark the above tools against a broad range of criteria. We use the typical performance metrics: precision, recall, and F1 score. We also gauge the speed of the tools (measured in tokens per second) on two different test computers. One high-end computer with a professional grade graphics card and one consumer grade system without graphic card acceleration (see section C of the Appendix). We make this comparison, because on the one hand we want to benchmark the tools’ speed under optimal conditions, and on the other hand we also want to measure the performance drop of each tool depending on the used hardware. Our assumption is that most researchers in social sciences tend to have limited access to high-end systems and typically would use consumer grade hardware for their research. Therefore, the speed of each tool under more realistic conditions is also an important factor for practical research.
Beyond these more technical criteria, we also include “softer” factors in our evaluation that have an impact on research practices. First, the supported languages of each tool are included to measure its versatility especially for multilingual research tasks. We assume that researchers prefer to use only one tool to extract named entities in a multilingual project, instead of switching between different tools. Second, we also consider support for coreference resolution, which is a related task to NER. And third, we include a qualitative evaluation on difficult edge cases as described by Nouvel et al. (Citation2016) and Jurafsky and Martin (Citation2023). The edge cases are sentences where automated techniques typically perform less well. Nouvel et al. (Citation2016) describes that tools mainly encounter problems with boundary detection, misclassification, or unknown tokens.
We manually selected 36 authentic sentences that pose various kinds of challenges for NER tools.Footnote7 We chose challenges in English, Dutch, German, and Spanish, because most tools can perform NER in these languages. Another practical reason is that we are most familiar with these languages and can provide a qualitative assessment for them.
The first kind of challenge is correct boundary detection in simple cases, where a tool has to determine which of the tokens form a sequence of a single named entity. This includes example sentences like the following:
“He saw John F. Kennedy just before the assassination.”
“Und nun will die Bundesregierung Gerhard Schröder Büro und Personal streichen.” [“And now the Federal Government wants to cancel Gerhard Schroeder’s office and staff.”]
In the first example, the challenge is posed by the middle name which is shortened by a period, which could confuse some tools that mistakenly split the example into two sentences. The second sentence presents a grammatical challenge to the tools: “Bundesregierung” and “Gerhard Schröder” should be classified as two separate entities.
The second kind of challenge is related to the correct classification of named entities:
“His trip through John F. Kennedy went well.”
“The Abrams tank was widely tested during the Gulfwar.”
“The Star Wars VII movie was directed by Abrams.”
“Romario, que en 1995, cuando militaba en el Flamengo, discutió públicamente con Luxemburgo - entonces técnico de ese club.” [“Romario, who in 1995, when he was a member of Flamengo, publicly argued with Luxemburgo - then coach of that club.”]
In the first and second examples, the named entities should not be classified as persons. However, in the third and fourth examples it should.
The third challenge encompasses a variety of issues and arises from tokens that are likely unfamiliar to the tools we employ. This frequently occurs when certain named entities are absent from the training data, such as neologisms, or when named entities are underrepresented, which is often the case with foreign or female names (Mehrabi et al., Citation2020, Citation2021):
“Hong Kong’s students tell Xi they don’t want a revolution.”
“Agnes Chow Ting, 17, stepped down as a spokeswoman for Scholarism after 2½ years, citing exhaustion, saying that she’s ‘unable to shoulder such a great burden,’ in a post Saturday on Scholarism’s Facebook page.”
“In Corona-Hochburgen wie München und Hamburg nähern sich einige Krankenhäuser der Kapazitätsgrenze.” [“Several hospitals are approaching the limits of their capacities in Corona-Strongholds such as Munich and Hamburg”]
The three examples, could cause NER tools to not to fully detect a named entity such as in “Agnes Chow Ting,” falsely classifying a named entity where there is none as in “Corona-Hochburgen,” or not detecting a named entity at all as in “Xi.”
XLM-RoBERTa finetuning
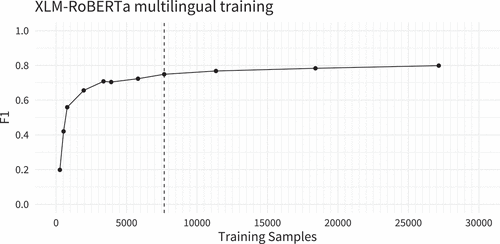
Since XLM-RoBERTa comes pre-trained in over 100 languages but not prepared for the NER task, we fine-tune the model on a composite multilingual corpus. We take the training splits from the corpora above to generate a composite corpus that contains training units for all evaluated languages. To prevent the model from over-fitting, we first test how the number of sample sentences affects the fine-tuning results, by randomly sampling training units from each corpus, where we increase the number of random samples for every training run (). Additionally, we also run several tests to gauge the minimum amount of required training data per language, as well as the transfer-learning capabilities of the model (see Turc et al., Citation2021). Our tests confirm that the model can perform NER in Hungarian or Italian, even though it has only “seen” training data for English, German, Dutch, and Spanish (see subsection C8 in the Appendix). Our tests also indicate that the model does not decrease in performance with the full set of sample sentences. It also shows that, with around 7,500 training sentences, the model can already achieve an F1 score above 0.75. Given these results, we fine-tuned XLM-RoBERTA with the complete training datasetFootnote8 which consists of 571,215 training sentences in all 13 languages. We use this model version to compare against all other NER tools.
Figure 1. Performance of XLM-RoBERTa with increasing size of training data for fine-tuning. One training sample is one sentence.
Results
Precision & recall
Comparing the performance of each tool across languages shows that extracting organizations is the most challenging task, while identifying persons is the easiest (). The results suggest that XLM-RoBERTa has the highest precision and recall throughout all benchmarks, tightly followed by the spaCy models. Among the dictionary-based approaches, JRC-Names shows high precision, but also low recall, indicating that it rarely reports false positives, but also misses a substantial amount of named entities. Among the classical machine learning algorithms, CoreNLP reaches the best F1 scores. However, all tools have unsatisfactory performance for non-Latin scripts. The precision and recall values for Arabic and Chinese are rarely above 0.75.
Figure 2. Precision, recall, and F1 score for each NER tool grouped by languages.

Considering the difference across corpora, most tools perform well on the CoNLL datasets, which is the oldest dataset in the test (see ). However, there is also a tendency that newer datasets (i.e., OntoNotes, GermEval, SoNaR, NYTK-NerKor, and KIND) pose a challenge for older tools. The noisy datasets are challenging for most tools, except for XLM-RoBERTa which still performs fairly well on this task.
Figure 3. Precision, recall, and F1 score for each NER tool grouped by corpora.

Speed
shows that nametagger is the fastest tool by far, followed by XLM-RoBERTa. Both were able to annotate the CNEC corpus in more or less one second. The dictionary-based tools become much slower with increasing keyword size. Among the classical machine learning tools, CoreNLP is the slowest, but it trades this for better precision. Using a consumer grade system, the speed of classical machine learning approaches and dictionaries decreases between 34% and 52%, where the speed of nametagger drops the least. The transformer based models have a dramatic speed reduction of over 90% on a system without graphics card acceleration, making them also the slowest under non-optimal conditions. This also hints at the monetary costs of employing deep learning models which require formidable hardware to run.
Features and languages
JRC-Names supports most languages out of the box and also performs almost equally well across them. XLM-RoBERTa was fine-tuned on all 13 languages and it could perform well on most of them. However, the weak performance for Chinese and Arabic would render this model unusable for these languages. CoreNLP supports 7 languages, but it also has weak performance in Chinese. spaCy’s support for up to 6 languages is satisfactory, but also with lackluster precision in Chinese.
Among all tested tools, CoreNLP and spaCy can perform coreference resolution, but only for selected languages.
Hand-picked challenges
shows a summary of each tool’s performance on the challenging cases. spaCy is the most robust tool for English and passed almost every challenge in this language. XLM-RoBERTa did not perform as well for English, but better for Spanish and Dutch. None of the tools particularly struggled with boundary detection in English, but classical machine learning tools had difficulties in detecting boundaries in Spanish or Dutch. The classical machine learning tools also performed worse when correctly extracting named entities with foreign names. Interestingly, none of the tools could correctly classify John F. Kennedy as a location when the NE referred to the airport. This indicates that ambiguous NE appear to be particularly difficult.
Table 4. Number of passed challenges per tool.
Discussion
We ran a comprehensive quantitative and qualitative evaluation of 8 tools for named entity recognition. For our evaluation we used 15 corpora covering 13 languages. We first critically reflect on our evaluation study, then we discuss the results of the NER tools. Finally, we present our recommendations for the practical usages of NER tools in communication research.
Limitations
While we tried to create optimal conditions for our evaluation study, there are some limitations in regard to data quality and test implementation. First, some corpora have impurities in their data that probably affected the results for French, English, and German. The Europeana and HIPE corpora were generated with the help of optical character recognition which introduces a significant number of misspelled tokens and thus can be considered noisy data. The WikiANN corpus was labeled with a semi-automated procedure which also produced imperfect validation data. Furthermore, the benchmark results for English were also negatively affected by the Emerging Entities corpus, which is extremely noisy and still a major challenge for top-performing monolingual tools (e.g, Shahzad et al., Citation2021). However, all these impurities in the data affected all models equally. And in practical research, noise in raw data is fairly common. Therefore, we believe that it is important to evaluate tools with noisy data as well.
Second, we might not have used the optimal implementations for CoreNLP and the two dictionaries, which probably caused these tools to underperform in terms of speed. When we evaluated CoreNLP we used its server mode and interfaced with it via HTTP requests to annotate the validation data. CoreNLP probably runs faster if it is natively imported in Java. We evaluated JRC Names and ICEWS using corpustools (Welbers & van Atteveldt, Citation2022). While it is arguably a very fast tool for keyword matching, there might be faster implementations possible. However, we believe that these are realistic implementation scenarios for said tools and that the speed decrease is probably fairly small.
Third, we refrained from retraining the older algorithms with newer data. While the models for CoreNLP are still updated regularly, it is highly possible that the other classical machine learning tools would perform better if they were retrained with newer data. However, we wanted to test how these models perform out of the box.
Fourth, we had to align the various named entity categories to achieve comparable results. However, in a few instances not all categories translate well. For example, the NE categories for locations (LOC), geo-political entities (GPE), and facilities (FAC) have slightly different definitions across tools and corpora. Additionally, for some tools and corpora, the definitions for the categories are somewhat vague, which potentially leaves room for variance among the human annotators (e.g., the “John F. Kennedy Airport” could be interpreted as an organization, facility or location). Given that the XLM-RoBERTa model was trained on the corpora after the alignment was applied, the model had a slight advantage over the other models. But we believe that such edge cases should not affect the evaluation results too much.
Fifth, there are more NER tools available that we did not evaluate in this study, but we based our selection on the research practices in the field. However, we admit that some tools would also be worthwhile exploring such as Flair (Akbik et al., Citation2019) or Stanza (Qi et al., Citation2020).
Finally, we acknowledge that the hand-picked challenges are not optimally balanced. They do not cover all tested languages and also did not provide an equal number of challenges for German, English, Dutch, and Spanish. Furthermore, they all only cover languages with Latin scripts. Yet, the challenges help to illustrate common issues that occur when using NER tools. For example, the challenges expose potential biases of NER tools toward non-Western names.
To address these challenges and accelerate future research of NER tools, we make the entire replication materials for our test setup publicly available. This enables other researchers to use our evaluation framework for other tools, or to extend the benchmarks.
Performance of NER tools
The evaluation study has shown that older models and approaches tend to perform worse on newer data. This can be explained by the increasing size and coverage of newer datasets. For example, the models for NLTK, nametagger, and OpenNLP were trained with the CoNLL corpora which are comparatively small and roughly 20 years old. For example, the English CoNLL corpus is solely based on news wires by Reuters from 1996 until 1997 (Tjong Kim Sang & De Meulder, Citation2003). Newer corpora such as OntoNotes are two times larger and also features samples from a diverse set of news sources and a wider date range (Weischedel et al., Citation2013). However, this also raises the question, how long the existing training datasets for NER will remain valid for research. The Emerging Entities corpus is a good example of the ever changing nature in news communication. Ideally, a training and validation corpus for NER should be continuously updated and incrementally extended.
Considering the softer criteria, our evaluation demonstrates that coreference resolution is a rare feature among NER tools. Only two of the selected tools can perform this sub-task. However, it is also an important building block for content analysis. For example, coreference resolution enables reliable extraction and attribution of quotes (e.g., Newell et al., Citation2018). Another shortcoming of most tools are their multilingual capabilities. Professionally maintained tools such as spaCy or CoreNLP cover more languages than other tools. However, all tools still lack support for a variety of languages. For example, there are over 22 languages with Latin scripts in the European Union alone, and our evaluation only covered 10 of them. Of course, this can be explained by the lack of available training and evaluation corpora. But it highlights the need for more multilingual training data with high quality.
Our study also shows the potential of large language models with a transformer architecture. XLM-RoBERTa performed well across all languages and corpora and appears to be robust against noisy data. There is a considerable performance drop when it had to perform NER in non-Latin scripts. The comparatively poor performance in Arabic and Chinese could be explained with the effective vocabulary size of the base model (Artetxe et al., Citation2020). BERT models tokenize into subwords, for example “playing” is split into “play” and “−ing.” On the one hand, the multilingual model appears to benefit from shared sub-words across languages with Latin scripts. The beneficial effect for languages with Latin script became evident in its performance during our pretests, where XLM-RoBERTa models showed acceptable results on languages that they were not trained on (see subsection C8 in the Appendix). Named entities tend to only change minimally across languages, which shows that a single model that covers a decent number of languages is within reach. On the other hand, the model’s fixed vocabulary size,Footnote9 may also be the cause for the weak performance for languages with non-Latin scripts. It probably does not allocate enough tokens for Arabic or Chinese. Additonally, the model employs a “one-size-fits-all” tokenizer, which in turn may be insufficient to properly segment Chinese input (Fu et al., Citation2020). This indicates that languages with non-Latin scripts such as Arabic, Chinese, Hebrew, or Russian would require separate models that are specifically trained on these scripts.
The fine-tuning process of the model took a considerable amount of time and professional grade hardware. One fine-tuning cycle can take between 4 and 12 hours and is impossible to do without a fairly large graphics card, which in turn may require monetary investments. However, the fine-tuning has to be done only once and then the model can be reused by other researchers on all kinds of hardware. However, our benchmarks also highlighted that the speed of the model decreases significantly on consumer grade hardware. In our validation scenario, using a graphics card, the model finished all corpora in less than seven minutes. In contrast, on the consumer grade system, the model took about 110 minutes, which is a speed decrease of 98% (see ).
There are promising advances in computer science that work toward improving the speed and performance of large language models on consumer grade hardware (e.g., Tsai et al., Citation2019). Therefore, we believe that this is also an important avenue to explore in future development of NER tools.
Furthermore, our experiments with XLM-RoBERTa have shown that the model requires a comparatively small amount of data to achieve acceptable performance in NER. We fine-tuned it with only 3,500 randomly sampled training sentences in 6 languages and it could already reach a F1 score above 0.8. For comparison, the CoNLL training dataset has over 14,000 training sentences in English. This means, that the existing and freely available corpora could be extended with additional samples for more languages to generate a multi-lingual NER corpus.
Conclusions & practical implications
With a wider perspective on communication research, it seems appropriate to continuously assess the performance of NER tools. The tools’ differences in performance on older and newer data is indicative for this conclusion. The hand-picked challenges we presented are a start for systematically evaluating NER tools against potential systematic biases, such as their weaknesses toward non-Western names.
There is also a lack of a common categorization standard for named entities. As mentioned above, each corpus and every tool uses different categories for named entities. It would probably be necessary to work toward annotation standards that are tailored for different sub-disciplines of communication research. For example, political communication researchers might be interested in laws or social groups, but scholars of advertisement might be interested in product names.
With more tuning and data XLM-RoBERTa and other large language models could achieve a human-like performance in NER. This potentially opens new avenues for big data analysis where NER can be used as an inductive approach. Researcher could compose their text data based on issues and then inductively examine the actors involved in the discourse.
Finally, we would like to give some recommendations for practical research based on our evaluation study. Among the off-the-shelf solutions, spaCy and CoreNLP seem to be strong choices. While spaCy scored slightly lower than CoreNLP in terms of F1 scores for some languages, it passed more challenges and is also updated several times a year. While we do not particularly want to endorse a commercially maintained software library, spaCy is open-source and also offers a rich set of other features and allows for custom training of NER in other languages. CoreNLP is maintained by a university, and open-source as well. However, CoreNLP is highly sensitive toward noisy data and appears to be biased against non-Western names.
In practical research, named entities are not only extracted, but also need to be reconciled and harmonized. All tested tools based on machine or deep learning merely return the tokens that compose a named entity alongside their broad category. However, this is not necessarily useful, since it is a common follow-up task to reconcile variations of the same NE to a canonical form. For example, the tokens “President Biden” and “Joe Biden” (probably) refer to the same person. And there are often not only a few of such cases, but rather thousands (e.g., the CoNLL English corpus has about 17,000 person tokens, which is about 5% of all its tokens). Dictionaries have the advantage that they are a two-in-one tool, which means that they detect the NE and harmonize it at the same time. Therefore, we recommend using a dictionary based approach if a research project requires to extract a small and finite list of named entities. A carefully crafted and validated collection of search strings can achieve F1 scores above 0.9 (e.g., Litvyak et al., Citation2022). The JRC Names dictionary is a promising foundation for custom dictionary development, because it already includes alternative spellings for a variety of actors. However, if the number of actors is too high, then the editorial effort increases dramatically. In such cases we advise to run an off-the-shelf tool and then to filter based on the named entities that the research question requires.
When using learning-based tools, the editorial effort is shifted to their (potentially) messy output. While it is possible to perform reconciliation manually, there are a series of third-party tools available that make this step easier. For example, OpenRefineFootnote10 or reconcilerFootnote11 which are both tools that query the WikiData API and provide suggestions for canonical names of named entities. A human annotator can then review the suggestions and make manual corrections accordingly. Besides these semi-automated approaches, there are also attempts at creating fully automated analysis pipelines such as JEnExtrA (Poschmann & Goldenstein, Citation2019). While these approaches may reduce the manual labor, it is still a limitation of learning-based tools.
Another approach to address the shortcomings of deep-learning methods would be to combine them with dictionary-based approaches. If the research interest requires to extract some highly domain-specific named entities, domain experts can create an initial seed dictionary which covers such kind of named entities. Next, the dictionary can be used to sample training units from new text data that covers the domain-specific entities. The newly sampled texts can then be used to augment an existing NER corpus. As mentioned above, transformer models can generalize well with a comparatively small set of training sample (Artetxe et al., Citation2020). This approach would be particularly effective in a human-in-the-loop (also known as active learning) method, where the NER pipeline is continuously improved and updated (e.g., Steinberger et al., Citation2011).
If performance and high accuracy is important, it is worth the effort to fine-tune a custom model like XLM-RoBERTa, instead of using an off-the-shelf tools like spaCy. Large language models are already freely available for a variety of languages and the fine-tuning process has become much simpler thanks to the continuous improvements of various software libraries. As mentioned, training data is also available for a variety of research purposes and they can be extended to suit the specifications of the research question.
Supplemental Material
Download PDF (142 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Supplementary material
Supplemental data for this article can be accessed online at https://doi.org/10.1080/19312458.2024.2324789
Additional information
Funding
Notes on contributors
Paul Balluff
Paul Balluff is a doctoral student at the Department of Communication at the University of Vienna.
Hajo G. Boomgaarden
Hajo G. Boomgaarden is a Professor of Empirical Social Science Methods at the University of Vienna.
Annie Waldherr
Annie Waldherr is a Univ.-Prof. Dr. Annie Waldherr Professor of Computational Communication Science at the University of Vienna.
Notes
1 For a recent comparison of NER tools for journalistic texts in German, please refer to Buz et al. (Citation2021).
2 Of course, this is a very simplified explanation of the training procedure. There are also other automatically generated training samples, for complete explanation refer to Devlin et al. (Citation2018).
3 For example, the Quaero corpus (see: https://islrn.org/resources/074-668-446-920-0/) is available for research purposes, but the licensing prohibits to redistribute a model that was trained with the data. Therefore, we excluded this corpus from our evaluation.
4 A parallel corpus has equivalent translations of the same text in multiple languages alongside annotations for each language.
5 See the subsections B6 and B9 in the Appendix and supplementary materials for details.
6 For a detailed explanation of all annotation standards for each tool, see section C of the Appendix.
7 For the complete list of challenges, please see section D in the Appendix and replication materials.
8 For details regarding the fine-tuning process refer to the supplementary materials.
9 XLM-RoBERTa has a vocabulary of 250,000 sub-word tokens.
10 see: https://openrefine.org/
References
- Akbik, A., Bergmann, T., Blythe, D., Rasul, K., Schweter, S., & Vollgraf, R. (2019). FLAIR: An easy-to-use framework for state-of-the-art NLP. Proceedings of the NAACL 2019, 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, Minnesota (pp. 54–59). https://doi.org/10.18653/v1/N19-4010
- Al-Rawi, A. (2017). News values on social media: News organizations’ Facebook use. Journalism, 18(7), 871–889. https://doi.org/10.1177/1464884916636142
- Aprosio, A. P., & Paccosi, T. (2023). NERMuD at EVALITA 2023: Overview of the named-entities recognition on multi-domain documents task. Proceedings of the Eighth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2023), Parma, Italy.
- Artetxe, M., Ruder, S., & Yogatama, D. (2020). On the cross-lingual transferability of monolingual representations. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 4623–4637. https://doi.org/10.18653/v1/2020.acl-main.421
- Baden, C., Pipal, C., Schoonvelde, M., & van der Velden, M. A. C. G. (2022). Three gaps in computational text analysis methods for social sciences: A research agenda. Communication Methods and Measures, 16(1), 1–18. https://doi.org/10.1080/19312458.2021.2015574
- Benikova, D., Biemann, C., & Reznicek, M. (2014). NoSta-D named entity annotation for German: Guidelines and dataset. Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland (pp. 2524–2531). http://www.lrec-conf.org/proceedings/lrec2014/pdf/276_Paper.pdf
- Bird, S., Klein, E., & Loper, E. (2009). Natural language processing with Python: Analyzing text with the natural language Toolkit. O’Reilly Media.
- Boschee, E., Lautenschlager, J., Shellman, S., & Shilliday, A. (2015). ICEWS dictionaries. https://doi.org/10.7910/DVN/28118
- Boumans, J. W., & Trilling, D. (2016). Taking stock of the toolkit. Digital Journalism, 4(1), 8–23. https://doi.org/10.1080/21670811.2015.1096598
- Burggraaff, C., & Trilling, D. (2020). Through a different gate: An automated content analysis of how online news and print news differ. Journalism, 21(1), 112–129. https://doi.org/10.1177/1464884917716699
- Buz, C., Promies, N., Kohler, S., & Lehmkuhl, M. (2021). Validierung von NER-Verfahren zur automatisierten identifikation von akteuren in deutschsprachigen journalistischen texten. Studies in Communication & Media, 10(4), 590–627. https://doi.org/10.5771/2192-4007-2021-4-590
- Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, E., Ott, M., Zettlemoyer, L., & Stoyanov, V. (2019). Unsupervised cross-lingual representation learning at scale. https://doi.org/10.48550/arXiv.1911.02116
- Derczynski, L., Nichols, E., van Erp, M., & Limsopatham, N. (2017). Results of the WNUT2017 shared task on novel and emerging entity recognition. Proceedings of the 3rd Workshop on Noisy User-generated Text, Copenhagen, Denmark (pp. 140–147). https://doi.org/10.18653/v1/W17-4418
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. https://doi.org/10.48550/arXiv.1810.04805
- Ehrmann, M., Romanello, M., Flückiger, A., & Clematide, S. (2020). Extended overview of CLEF HIPE 2020: Named entity processing on historical newspapers. In L. Cappellato, C. Eickhoff, N. Ferro, & A. Névéol (Eds.), CLEF 2020 Working Notes. Working Notes of CLEF 2020 – Conference and Labs of the Evaluation Forum, Thessaloniki, Greece (Vol. 2696). CEUR-WS. https://doi.org/10.5281/zenodo.4117566
- Finkel, J. R., Grenager, T., & Manning, C. (2005). Incorporating non-local information into information extraction systems by Gibbs sampling. Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, Michigan (pp. 363–370). https://doi.org/10.3115/1219840.1219885
- Fogel-Dror, Y., Shenhav, S. R., Sheafer, T., & Van Atteveldt, W. (2019). Role-based association of verbs, actions, and sentiments with entities in political discourse. Communication Methods and Measures, 13(2), 69–82. https://doi.org/10.1080/19312458.2018.1536973
- Fu, J., Liu, P., Zhang, Q., & Huang, X. (2020). RethinkCWS: Is Chinese word segmentation a solved task? The 2020 Conference on Empirical Methods in Natural Language Processing, Online. https://arxiv.org/abs/2011.06858
- Gattermann, K. (2018). Mediated personalization of executive European Union politics: Examining patterns in the broadsheet coverage of the European Commission, 1992–2016. The International Journal of Press/politics, 23(3), 345–366. https://doi.org/10.1177/1940161218779231
- Grill, C., & Boomgaarden, H. (2017). A network perspective on mediated Europeanized public spheres: Assessing the degree of Europeanized media coverage in light of the 2014 European Parliament election. European Journal of Communication, 32(6), 568–582. https://doi.org/10.1177/0267323117725971
- Honnibal, M., Montani, I., Van Landeghem, S., & Boyd, A. (2020). spaCy: Industrial-strength natural language processing in Python. https://doi.org/10.5281/zenodo.1212303
- Hopp, F. R., Fisher, J. T., Cornell, D., Huskey, R., & Weber, R. (2020). The extended moral foundations dictionary (eMFD): Development and applications of a crowd-sourced approach to extracting moral intuitions from text. Behavior Research Methods, 53(1), 232–246. https://doi.org/10.3758/s13428-020-01433-0
- Jonkman, J. G., Trilling, D., Verhoeven, P., & Vliegenthart, R. (2020). To pass or not to pass: How corporate characteristics affect corporate visibility and tone in company news coverage. Journalism Studies, 21(1), 1–18. https://doi.org/10.1080/1461670X.2019.1612266
- Joshi, M., Levy, O., Weld, D. S., & Zettlemoyer, L. (2019). BERT for coreference resolution: Baselines and analysis. https://doi.org/10.48550/arXiv.1908.09091
- Jurafsky, D., & Martin, J. H. (2023). Speech and language processing: An introduction to natural language processing, computational linguistics, and speech recognition [3rd Edition Draft]. https://web.stanford.edu/~jurafsky/slp3/
- Kripke, S. A. (1972). Naming and necessity. In D. Davidson & G. Harman (Eds.), Semantics of natural language (pp. 253–355). Springer.
- Kruikemeier, S., Gattermann, K., & Vliegenthart, R. (2018). Understanding the dynamics of politicians’ visibility in traditional and social media. The Information Society, 34(4), 215–228. https://doi.org/10.1080/01972243.2018.1463334
- Lee, J. S., & Nerghes, A. (2018). Refugee or migrant crisis? Labels, perceived agency, and sentiment polarity in online discussions. Social Media & Society, 4(3), 205630511878563. https://doi.org/10.1177/2056305118785638
- Lind, F., Eberl, J.-M., Eisele, O., Heidenreich, T., Galyga, S., & Boomgaarden, H. G. (2021). Building the bridge: Topic modeling for comparative research. Communication Methods and Measures, 16(2), 96–114. Advance online publication. https://doi.org/10.1080/19312458.2021.1965973
- Litvyak, O., Fischeneder, A., Balluff, P., Müller, W. C., Kritzinger, S., & Boomgaarden, H. G. (2022). AUTNES automatic content analysis of the media coverage 2019 (SUF edition). https://doi.org/10.11587/ZY7KSQ
- Manning, C., Surdeanu, M., Bauer, J., Finkel, J., Bethard, S., & McClosky, D. (2014). The Stanford CoreNLP natural language processing toolkit. Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, (pp. 55–60). https://doi.org/10.3115/v1/P14-5010
- Martin, G. J., & McCrain, J. (2019). Local news and national politics. American Political Science Review, 113(2), 372–384. https://doi.org/10.1017/S0003055418000965
- Mehrabi, N., Gowda, T., Morstatter, F., Peng, N., & Galstyan, A. (2020). Man is to person as woman is to location: Measuring gender bias in named entity recognition. Proceedings of the 31st ACM Conference on Hypertext and Social Media, Online (pp. 231–232). https://doi.org/10.1145/3372923.3404804
- Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM Computing Surveys, 54(6), 1–35. https://doi.org/10.1145/3457607
- Merkley, E. (2020). Are experts (News)worthy? Balance, conflict, and mass media coverage of expert consensus. Political Communication, 37(4), 530–549. https://doi.org/10.1080/10584609.2020.1713269
- Mohit, B., Schneider, N., Bhowmick, R., Oflazer, K., & Smith, N. A. (2012, April). Recall-oriented learning of Named entities in Arabic Wikipedia. In W. Daelemans (Ed.), Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France (pp. 162–173). Association for Computational Linguistics. https://aclanthology.org/E12-1017
- Mota, C., & Santos, D. (Eds.). (2008). Desafios na avaliação conjunta do reconhecimento de entidades mencionadas: O Segundo HAREM. Linguateca. https://www.linguateca.pt/LivroSegundoHAREM/
- Nadeau, D., & Sekine, S. (2007). A survey of named entity recognition and classification. Lingvisticae Investigationes, 30(1), 3–26. https://doi.org/10.1075/li.30.1.03nad
- Nardulli, P. F., Althaus, S. L., & Hayes, M. (2015). A progressive supervised-learning approach to generating rich civil strife data. Sociological Methodology, 45(1), 148–183. https://doi.org/10.1177/0081175015581378
- Neudecker, C. (2016, May). An open corpus for named entity recognition in historic newspapers. In N. Calzolari, K. Choukri, T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016). European Language Resources Association (ELRA), Portorož, Slovenia.
- Newell, C., Cowlishaw, T., & Man, D. (2018). Quote extraction and analysis for news. Proceedings of the KDD Workshop on Data Science, New York, NY, USA. Journalism and Media (DSJM).
- Nouvel, D., Ehrmann, M., & Rosset, S. (2016, February). Named entities for computational linguistics (Vol. 148). John Wiley & Sons, Inc. https://doi.org/10.1002/9781119268567
- Oostdijk, N., Reynaert, M., Hoste, V., & van den Heuvel, H. (2013). SoNaR User Documentation (tech. rep). Instituut voor de Nederlandse Taal. https://taalmaterialen.ivdnt.org/wp-content/uploads/documentatie/sonardocumentatie.pdf
- Paccosi, T., & Aprosio, A. P. (2021). KIND: An Italian multi-domain dataset for named entity recognition. CoRR. https://doi.org/10.48550/arXiv.2112.15099
- Pan, X., Zhang, B., May, J., Nothman, J., Knight, K., & Ji, H. (2017). Cross-lingual name tagging and linking for 282 languages. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1946–1958. https://doi.org/10.18653/v1/P17-1178
- Pires, T., Schlinger, E., & Garrette, D. (2019). How multilingual is multilingual BERT?. https://doi.org/10.48550/arXiv.1906.01502
- Poschmann, P., & Goldenstein, J. (2019). Disambiguating and specifying social actors in big data: Using Wikipedia as a data source for demographic information. Sociological Methods & Research, 51(2), 887–925. https://doi.org/10.1177/0049124119882481
- Qi, P., Zhang, Y., Zhang, Y., Bolton, J., & Manning, C. D. (2020). Stanza: A python natural language processing toolkit for many human languages. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online.
- Ruokolainen, T., Kauppinen, P., Silfverberg, M., & Lindén, K. (2020). A Finnish news corpus for named entity recognition. Language Resources and Evaluation, 54(1), 247–272. https://doi.org/10.1007/s10579-019-09471-7
- Scheible, R., Thomczyk, F., Tippmann, P., Jaravine, V., Boeker, M., Folz, M., Grimbacher, B., Göbel, J., Klein, C., Nieters, A., Rusch, S., Kindle, G., & Storf, H. (2020). GottBERT: A pure German language model. https://doi.org/10.48550/arXiv.2012.02110
- Scott, T. A., Ulibarri, N., & Scott, R. P. (2020). Stakeholder involvement in collaborative regulatory processes: Using automated coding to track attendance and actions. Regulation & Governance, 14(2), 219–237. https://doi.org/10.1111/rego.12199
- Ševčíková, M., Žabokrtský, Z., Straková, J., & Straka, M. (2014). Czech named entity corpus 2.0 [LINDAT/CLARIAH-CZ digital library at the Institute of Formal and Applied Linguistics (ÚFAL). In Faculty of mathematics and physics. Charles University]. http://hdl.handle.net/11858/00-097C-0000-0023-1B22-8
- Shahzad, M., Amin, A., Esteves, D., & Ngonga Ngomo, A.-C. (2021). InferNER: An attentive model leveraging the sentence-level information for named entity recognition in Microblogs. The International FLAIRS Conference Proceedings, North Miami Beach, Florida (p. 34). https://doi.org/10.32473/flairs.v34i1.128538
- Simon, E., & Vadász, N. (2021). Introducing NYTK-NerKor, a gold standard Hungarian named entity annotated corpus. In K. Ekstein, F. Pártl, & M. Konopík (Eds.), Text, Speech, and Dialogue – 24th International Conference, Olomouc, Czech Republic (pp. 222–234, Vol. 12848). Springer. https://doi.org/10.1007/978-3-030-83527-9_19
- Steinberger, R., & Pouliquen, B. (2007). Cross-lingual named entity recognition (S. Sekine & E. Ranchhod, eds.). Lingvisticae Investigationes, 30(1), 135–162. https://doi.org/10.1075/li.30.1.09ste
- Steinberger, R., Pouliquen, B., Kabadjov, M., Belyaeva, J., & Van Der Goot, E. (2011). JRC-NAMES: A freely available, highly multilingual named entity resource. International Conference Recent Advances in Natural Language Processing, RANLP, Hissar, Bulgaria (pp. 104–110). https://aclanthology.org/R11-1015
- Straková, J., Straka, M., & Hajič, J. (2013). A new state-of-the-art Czech Named Entity Recognizer. In I. Habernal & V. Matoušek (Eds.), Text, speech, and dialogue (pp. 68–75). Springer. https://doi.org/10.1007/978-3-642-40585-3_10
- Taulé, M., Martí, M. A., & Recasens, M. (2008, May). AnCora: Multilevel annotated corpora for Catalan and Spanish. In N. Calzolari, K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, & D. Tapias (Eds.), Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco. European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2008/pdf/35_paper.pdf
- Tjong Kim Sang, E. F. (2002). Introduction to the CoNLL-2002 lc: Language-independent named entity recognition. COLING-02: The 6th Conference on Natural Language Learning 2002 (CoNLL-2002). https://aclanthology.org/W02-2024
- Tjong Kim Sang, E. F., & De Meulder, F. (2003). Introduction to the CoNLL-2003 lc: Language-independent named entity recognition. Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, 142–147. https://aclanthology.org/W03-0419
- Traag, V. A., Reinanda, R., & Van Klinken, G. (2015). Elite co-occurrence in the media. Asian Journal of Social Science, 43(5), 588–612. https://doi.org/10.1163/15685314-04305005
- Tsai, H., Riesa, J., Johnson, M., Arivazhagan, N., Li, X., & Archer, A. (2019). Small and practical BERT models for sequence labeling. https://doi.org/10.48550/arXiv.1909.00100
- Turc, I., Lee, K., Eisenstein, J., Chang, M.-W., & Toutanova, K. (2021, June). Revisiting the primacy of English in zero-shot cross-lingual transfer. https://doi.org/10.48550/arXiv.2106.16171
- Turcsányi, R. Q., Karásková, I., Matura, T., & Šimalčík, M. (2019). Followers, challengers, or by-standers? Central European media responses to intensification of relations with China. Intersections East European Journal of Society and Politics, 5(3), 49–67. https://doi.org/10.17356/IEEJSP.V5I3.564
- van Atteveldt, W., van der Velden, M. A. C. G., & Boukes, M. (2021). The validity of sentiment analysis: Comparing manual annotation, crowd-coding, dictionary approaches, and machine learning algorithms. Communication Methods and Measures, 15(2), 121–140. https://doi.org/10.1080/19312458.2020.1869198
- Van den Bosch, A., Busser, G., Daelemans, W., & Canisius, S. (2007). An efficient memory-based morphosyntactic tagger and parser for Dutch. In F. van Eynde, P. Dirix, I. Schuurman, & V. Vandeghinste (Eds.), Selected papers of the 17th computational linguistics in the Netherlands Meeting, Leuven, Belgium (pp. 99–114). LOT.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you Need. NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, California (pp. 6000–6010). https://doi.org/10.5555/3295222.3295349
- Vliegenthart, R., Boomgaarden, H. G., & Boumans, J. W. (2011). Changes in political news coverage: Personalization, conflict and negativity in British and Dutch newspapers. Political Communication in Postmodern Democracy: Challenging the Primacy of Politics, 92–110. https://doi.org/10.1057/9780230294783
- Walter, D., & Ophir, Y. (2019). News frame analysis: An inductive mixed-method computational approach. Communication Methods and Measures, 13(4), 248–266. https://doi.org/10.1080/19312458.2019.1639145
- Watanabe, K. (2017). Newsmap. Digital Journalism, 6(3), 294–309. https://doi.org/10.1080/21670811.2017.1293487
- Weischedel, R., Palmer, M., Marcus, M., Hovy, E., Pradhan, S., Ramshaw, L., Xue, N., Taylor, A., Kaufman, J., Franchini, M., El-Bachouti, M., Belvin, R., & Houston, A. (2013). OntoNotes release 5.0. https://doi.org/10.35111/XMHB-2B84
- Welbers, K., & van Atteveldt, W. (2022). Corpustools: Managing, querying and analyzing tokenized text [R Package Version 0.4.10]. https://CRAN.R-project.org/package=corpustools
- Welbers, K., van Atteveldt, W., Kleinnijenhuis, J., & Ruigrok, N. (2018). A gatekeeper among gatekeepers. Journalism Studies, 19(3), 315–333. https://doi.org/10.1080/1461670X.2016.1190663