
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The key to electroencephalography (EEG)-based brain-computer interface (BCI) lies in neural decoding, and its accuracy can be improved by using hybrid BCI paradigms, that is, fusing multiple paradigms. However, hybrid BCIs usually require separate processing processes for EEG signals in each paradigm, which greatly reduces the efficiency of EEG feature extraction and the generalizability of the model. Here, we propose a two-stream convolutional neural network (TSCNN) based hybrid brain-computer interface. It combines steady-state visual evoked potential (SSVEP) and motor imagery (MI) paradigms. TSCNN automatically learns to extract EEG features in the two paradigms in the training process and improves the decoding accuracy by 25.4% compared with the MI mode, and 2.6% compared with SSVEP mode in the test data. Moreover, the versatility of TSCNN is verified as it provides considerable performance in both single-mode (70.2% for MI, 93.0% for SSVEP) and hybrid-mode scenarios (95.6% for MI-SSVEP hybrid). Our work will facilitate the real-world applications of EEG-based BCI systems.
1. Introduction
Brain-computer interface (BCI) decodes the brain signals (e.g. EEG, fMRI, and fNIRS) for establishing direct communication between the human brain and computer (or more generally, between brain and machine) to replace traditional brain signal output pathways, such as peripheral nerve and muscle tissues. In particular, EEG-based BCI detects EEG features related to mental states or intentions and translates these features into specific commands. A number of existing works have focused on improving EEG decoding performance in terms of accuracy [Citation1], robustness [Citation2], efficiency [Citation3], and cross-subject reliability [Citation4].
Typical EEG-based BCI paradigms include motor imagery (MI) [Citation1,Citation5,Citation6], P300 [Citation7,Citation8], and steady-state visual evoked potential (SSVEP) [Citation1,Citation9,Citation10]. During motor imagery, such as imagining limb movements without actual limb movements, the motor cortex is activated, producing neural patterns similar to those produced during actual motor execution [Citation11,Citation12]. These neural patterns can be captured with EEG recordings. Traditional human-computer interaction methods, such as using a keyboard to interact with a computer, require the user to perform actual operations to control. MI-based BCI provides a new mode of human-computer interaction for virtual reality and the manipulation of external devices without actual action execution. MI-based BCI also can control rehabilitation equipment such as wheelchairs and prosthetic devices for people with motor disabilities [Citation13,Citation14]. SSVEP signals are the entrained neural response to visual stimuli at specific frequencies, which can be used for neural decoding. As a widely used BCI paradigm, SSVEP has the advantages of fast recognition speed, high accuracy, and extendable classes of commands for external device control and text spelling [Citation15]. However, almost all of these BCI paradigms have their own limitations. MI-based BCI suffers from its unsatisfactory decoding accuracy and few recognizable command classes. SSVEP-based BCI requires the subjects to stare at the monitor for a long time, and the flickering stimuli easily cause visual fatigue [Citation16]. Therefore, a more reliable, efficient and comfortable BCI paradigm is urgently needed.
In recent years, there has been a growing interest in combining multiple brain-computer interface (BCI) paradigms, such as motor imagery (MI) and steady-state visual evoked potential (SSVEP), as well as integrating multimodal neural signals, leading to the emergence of hybrid BCIs. These hybrid systems aim to enhance BCI performance by leveraging the advantages of different modalities. Several studies have reported the benefits of hybrid BCIs in improving efficiency and accuracy compared to single-mode BCIs. For instance, Allison et al. [Citation17,Citation18] introduced an MI + SSVEP hybrid BCI paradigm in which participants performed motor imagery tasks while focusing on specific LED stimuli. Their findings demonstrated that the hybrid BCI approach improved accuracy and reduced the occurrence of BCI illiteracy, where users struggle to control the BCI effectively. Similarly, Yu et al. [Citation19] emphasized the auxiliary effect of SSVEP on MI. They proposed the integration of SSVEP into MI-BCI, expecting that this combination would provide more accurate feedback reflecting users’ intentions. Moreover, Ko et al. [Citation20] proposed an MI-SSVEP hybrid BCI system capable of recognizing user intent in MI mode, SSVEP mode, and mixed mode using a single electrode. This innovative system allows users to leverage different BCI modes through a unified interface, offering enhanced control and flexibility. Additionally, Chi et al. [Citation21] suggested that incorporating visual stimuli can improve the performance of MI tasks. They proposed novel methods involving visual cues to assist users in performing MI tasks more effectively. These studies collectively contribute to the advancement of hybrid BCIs by demonstrating their potential to improve BCI performance, providing more accurate intent recognition, and enhancing the user experience. The integration of multiple paradigms and the utilization of visual stimuli offer promising avenues for further research and development in the field of BCIs.
Motivated by recent advancements in deep learning and its widespread applications in computer vision and natural language processing, deep learning models have gained significant attention in the field of neural signal processing and decoding [Citation22,Citation23]. Deep learning techniques offer a promising framework for extracting electroencephalogram (EEG) features, allowing for the combination and utilization of complex information from different modes, such as steady-state visual evoked potential (SSVEP) and motor imagery (MI), within a unified multi-paradigm brain-computer interface (BCI) system. Traditional neural decoding methods used in BCI systems, including canonical correlation analysis (CCA), common spatial patterns (CSP), and filter bank CSP (FBCSP), often require specific algorithms designed for processing EEG signals in particular paradigms. Moreover, these traditional approaches heavily rely on prior knowledge and are susceptible to noise interference. In contrast, deep learning-based neural decoding can effectively extract EEG features in both the time domain and frequency domain, eliminating the need for explicit EEG feature engineering. Furthermore, deep learning models can leverage distributed and hierarchical features through multiple layers of nonlinear information processing, resulting in superior performance compared to traditional methods. For instance, Kwon et al. [Citation4] proposed a subject-independent convolutional neural network (CNN) framework for an MI-based BCI system, achieving significantly higher accuracy compared to traditional methods. Schirrmeister et al. [Citation24] implemented various CNN architectures for decoding MI directly from raw EEG signals, providing insights into the latent information learned by CNNs and how these learned feature representations facilitate neural decoding. Regarding multimodal fusion, several studies have provided valuable inspiration. Zheng et al. [Citation25] applied feature-level fusion and decision-level fusion techniques to combine features from EEG signals and eye-tracking data. Xu et al. [Citation26] proposed a parallel convolutional neural network (PCNN) that extracts high-dimensional and spatial features from converted images using convolution and pooling operations, respectively. The extracted features are then concatenated to realize multi-sensor fusion, enabling effective information integration. Amin et al. [Citation27] proposed a multi-layer CNN method that combines CNNs with different characteristics and architectures to enhance EEG MI classification accuracy through fusion.
In this study, we propose a hybrid BCI system based on MI and SSVEP and a two-stream convolutional neural network (TSCNN) which is used to decode EEG. As shown in , TSCNN can be used in three modes (i.e. MI, SSVEP, and hybrid). The main contributions of this study can be summarized as follows
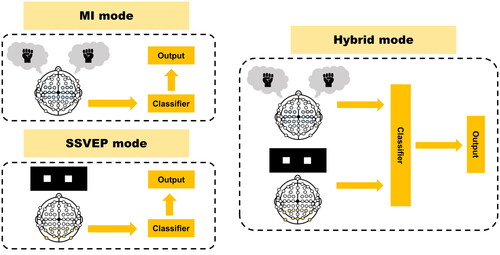
Figure 1. Three modes of BCI system. (left top) MI mode, in which the subject imagines the left- or right-hand movement. (left bottom) SSVEP mode, in which the subject stares at the left or right flickering stimulus. (right) Hybrid mode, in which the MI and SSVEP are combined.
TSCNN can automatically learn to extract the EEG features in two different BCI paradigms during the training process, avoiding the limitation of the traditional methods to design specific algorithms to extract features in different paradigms.
We present a novel training strategy that enables TSCNN to achieve high decoding accuracy in hybrid mode while maximally reserving performance in MI mode and SSVEP mode.
Through the training strategy and the two-stream architecture, TSCNN is more versatile as it provides considerable performance in both single-mode and hybrid-mode scenarios.
2. Materials and methods
2.1. Dataset description
The EEG dataset used in our study was collected by the Department of Brain and Cognitive Engineering at Korea University [Citation28]. It includes data from 54 subjects performing a binary-class MI task and a four-class SSVEP task. The dataset consists of two sessions, each of which includes an offline training phase and an online testing phase. For this study, we use the training phase of session1. The EEG signals were recorded at a sampling rate of 1,000 Hz using 62 Ag/AgCl electrodes and a BrainAmp amplifier (Brain Products; Munich, Germany).
In the MI task, a trial starts with a black fixation cross displayed in the center of the screen, which lasts for 3 s, followed by a left or right arrow as a visual cue, lasting for 4 s during which the subject imagine a grasping movement with the corresponding hand. In the end of each trial, the screen remains blank for 6s (±1.5s). The MI paradigm consists of 100 trials, including 50 left MI trials and 50 right MI trials. In the SSVEP task, four target SSVEP stimuli flickering at 5.45, 6.67, 8.57, and 12 Hz are presented at four locations (down, right, left, and up, respectively) on the monitor. Participants are instructed to fixate at the center of the black screen and then gaze in the direction where the target stimulus is highlighted in different colors. In each trial, SSVEP stimulus is presented for 4s followed by a 2s rest. The SSVEP paradigm consists of 100 trials, including 25 trials of each, frequency.
The EEG data preprocessing and channel selection procedures are presented in . In this study, we aim to develop a hybrid approach that combines MI and SSVEP to achieve binary classification for left-right discrimination. Accordingly, we have utilized the SSVEP task frequencies that represent the left-right classes, which are and
In the hybrid mode, the two classes comprise of the following combinations: left-hand MI with
SSVEP, and right-hand MI with
SSVEP. Prior studies have demonstrated the efficacy of this approach [Citation20]. Moreover, for the MI and SSVEP tasks, we have chosen 20 electrodes in the motor cortex region (FC-5/3/1/2/4/6, C-5/3/1/z/2/4/6, and CP-5/3/1/z/2/4/6) and 10 electrodes in the occipital region (P-7/3/z/4/8, PO-9/10, and O-1/z/2), respectively. A band-pass filter of 5th order Butterworth digital filter was applied to the MI signals between the frequency range of
Hz. Both MI and SSVEP signals were segmented within the time frame of
ms.
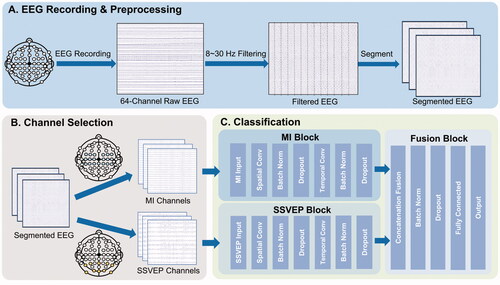
Figure 2. The TSCNN framework: (A) EEG Recording and preprocessing: the recorded EEG is filtered by bandpass filter, and then segmented into 4s length. (B) Channel selection: select the specific channels of MI and SSVEP. (C) Classification: classify the input EEG segments with TSCNN.
2.2. Model architecture
TSCNN consists of three main blocks: the MI block, SSVEP block, and Fusion block. illustrates the TSCNN architecture in this study. The MI block and the SSVEP block share a similar architecture adopted from the single-stream CNN (SCNN) [Citation9].
The MI block and the SSVEP block have two main layers: a spatial convolutional layer and a temporal convolutional layer. EEG channels are selected for MI and SSVEP tasks specifically, and these channels are input into the corresponding blocks, as shown in . The input dimension is where Nch is the number of channels and Nt is the number of time components. The spatial convolutional layer that performs 1D convolution across the channel dimension with the kernel dimension of 20 × 1 and 10 × 1 corresponding to MI and SSVEP. The temporal convolutional layer operates on the spectral representation of the input with a kernel dimension of 1 × 10. After the spatial and temporal convolution, the feature map dimension of MI and SSVEP blocks are both
Then the feature maps of MI and SSVEP blocks are concatenated in the fusion block. Afterward, the concatenated feature maps are connected to a fully connected layer for classification, followed by batch normalization and dropout. Specifically, batch normalization is used to accelerate training and improve the generation performance by reducing the internal covariance shift in the input, turning it into a standard normal distribution
[Citation29]. Dropout is used to avoid overfitting and improve generalizability [Citation30–32]. Finally, the decision of TSCNN is made by a sigmoid function.
2.3. Feature representation in TSCNN
We denote as a set of preprocessed single-trial EEG, and let
be the matching class labels, where n is the number of trials,
is the single-trial EEG, and
is the class label of the single trial. The selected MI channels and SSVEP channels from 64-channel EEGs of subject X are selected (), denoted as
and
respectively. We denote
and
as the inputs of the MI block and SSVEP block, respectively. Given inputs
and
the output of TSCNN is denoted as
where fT refers to the TSCNN network.
2.4. Division of data
Data from forty subjects are used to train the TSCNN model. We propose two training strategies: using only the hybrid-mode EEG (TSCNN1), and using both the single-mode EEG and hybrid-mode EEG (TSCNN2).
The first strategy is to train the model using only hybrid-mode EEG. We denote the TSCNN trained in this strategy as TSCNN1. The inputs are presented as:
A total number of 2000 samples (40 subjects × 50 trials) for each paradigm are utilized as inputs for TSCNN1. 10-fold cross-validation is performed in the training session.
The second strategy uses a combination of the single-mode and hybrid-mode EEG data to train the model. We denote the TSCNN trained in this strategy as TSCNN2. The inputs are presented as:
A total number of 4000 samples (40 subjects × 100 trials) for each paradigm are utilized as inputs for the TSCNN2. 10-fold cross-validation is performed.
2.5. Training parameters
The weights of the TSCNNs are initialized with a Gaussian distribution The network is trained using backpropagation to minimize the binary cross-entropy (BCE) loss function:
where y denotes the true label and
denotes the predicted label. All models are trained using the Adam optimizer with a learning rate of 0.00025 [Citation33]. The dropout rate and the batch size are set to 50% and 64, respectively. All the experiments are conducted on a laptop with AMD-Ryzen 7-5800H 3.20-GHz and 16-GB memory.
2.6. Evaluation
The test dataset comprised EEG data from the remaining 14 subjects. The performance evaluation of TSCNN included metrics such as decoding accuracy, sensitivity, specificity, and mean square error (MSE). To establish a comparison, we also employed a modified SCNN as a competing model, which has demonstrated excellent performance in single-mode classification tasks as reported in a previous study [Citation9]. Additionally, we assessed the decoding accuracy of SCNN in the hybrid mode, serving as a comparative model for the hybrid system. In the hybrid SCNN (hSCNN) model, we fused the SSVEP and MI data by concatenating them along the channel dimension, which were then input into the SCNN architecture.
3. Results
3.1. Decoding performance
shows the decoding performance of SCNN, TSCNN1, and TSCNN2. Obviously, TSCNN2 achieves the best decoding accuracy in the hybrid mode and maintains satisfactory performance in the single mode of MI and SSVEP. In an overarching assessment, TSCNN1 demonstrates the best accuracy, specificity, and MSE in the hybrid mode, while TSCNN2 exhibits the highest accuracy and sensitivity in hybrid mode. Specifically, the averaged decoding accuracy, sensitivity, specificity and MSE from TSCNN2 are and
in MI mode,
and
in SSVEP mode, and
and
in hybrid mode.
Table 1. Decoding performance (mean ± std) of three models.
In addition, we further compared our proposed hybrid system with existing successful algorithms for single-mode MI and SSVEP systems, such as M-CNN [Citation9], C-CNN [Citation9], and 1DMSCNN. [Citation34] Notably, clearly demonstrates that our hybrid system consistently outperforms these existing algorithms in terms of decoding performance. Among all the models considered, it is noteworthy that TSCNN1, operating within the hybrid mode, consistently exhibits the highest levels of accuracy, specificity, and MSE, while TSCNN2 excels in terms of accuracy and sensitivity. This finding highlights the superiority of our hybrid system and its ability to achieve the best decoding results across multiple paradigms. Furthermore, it is worth noting that the decoding performance of TSCNN significantly surpasses that of hSCNN, further affirming the effectiveness of our proposed model.
Table 2. Comparison of mean ± standard deviation for decoding performances (mean ± std) in single MI, SSVEP, and hybrid systems.
shows the performance changes of TSCNN2 in three modes according to the dimension of the fully-connected layer. For MI mode, the decoding accuracies with the change of dimension of the fully-connected layer are 65.1% and 70.4% for no fully connected layer and 16-dimension fully connected layer. For SSVEP mode, they are 93.6% and 93.7% respectively. For hybrid mode, they have the same performance on decoding accuracy, which is 95.6%. The model with 16-dimension fully-connected layer performed better overall.
Table 3. Decoding accuracy of TSCNN2 according to the fully connected number.
illustrates the performance changes of TSCNN2 under three modes according to the number of convolution kernels. In order to study the effect of the number of convolution kernels, the performance of the TSCNN under different numbers of convolution kernels was tested. Convolution kernels of (i, j) represent that the spatial convolutional layer and temporal convolutional layer in MI and SSVEP block have i and j convolutional kernels, respectively. The MI block and SSVEP block have the same structure, and the different numbers of kernels for spatial and temporal convolution are compared to evaluate the performance. The decoding accuracies for MI mode are 70.4%, 66.3%, 66.2%, and 64.6% when the kernel number is (1, 1), (1, 2), (2, 2), and (8, 8), respectively. For SSVEP mode, the decoding accuracies are 93.3%, and 93.0% when the kernel number is (1, 1), (1, 2), (2, 2), (8, 8) respectively. For hybrid mode, the decoding accuracies are
95.4%, 94.7% when the kernel number is (1, 1), (1, 2), (2, 2), and (8, 8), respectively. Notably, in both MI and SSVEP modes, the (1, 1) configuration for convolutional kernels demonstrates optimal performance, while in the hybrid mode, the (1, 2) configuration yields the highest decoding accuracy. Consequently, the model with kernel number (1, 1) had the best performance overall.
Table 4. Decoding accuracy of TSCNN2 according to the number of convolution kernels.
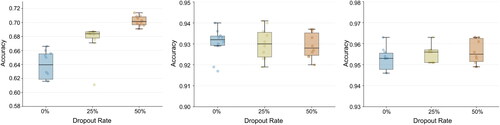
shows the decoding accuracy of TSCNN1 in three modes with 0%, 25%, and 50% dropout rate respectively. From the results, the 50% dropout rate has a significant improvement in decoding accuracy for the MI mode, while there is no obvious difference in decoding accuracies between different dropout rates in SSVEP and MI modes.
Figure 3. Impact of TSCNN architecture design choices on decoding accuracy in MI mode (left), SSVEP mode (middle), and hybrid mode (right) with different dropout rates. The horizontal axis is the different dropout rates, and the vertical axis is the decoding accuracy.
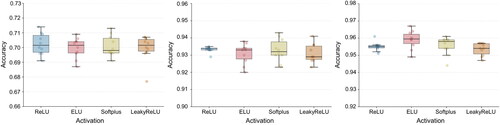
The decoding accuracy of TSCNN1 using different non-linear activation functions are compared. shows the decoding accuracies of TSCNN1 in the three modes with ReLU [Citation35], ELU [Citation36], Softplus [Citation35], and LeakyReLU [Citation37] activation functions. There is no significant difference in the performance of different activation functions in the three modes.
Figure 4. Impact of TSCNN architecture design choices on decoding accuracy in MI mode (left), SSVEP mode (middle), and hybrid mode (right) with different activations. The horizontal axis is the different dropout rates, and the vertical axis is the decoding accuracy.
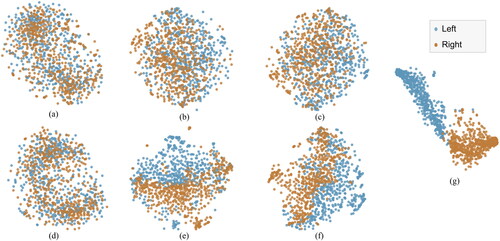
visualized the features at different layers of TSCNN2 in hybrid mode by t-SNE. are visualization results in the MI block, are visualization results in the SSVEP block, and is the visualization result in the fusion block. To achieve this, the data of subject 20 ∼ 40 is input into pre-trained TSCNN2, and the features were extracted at each layer. Each point in the figure represents a single trial, and the color represents its category (blue represents left and red represents right). The results show that the MI block features are less distinct than the SSVEP block. The features are the most obvious and can be distinguished well after the fusion.
Figure 5. Visualization of features for subjects 20–30 in 2 dimensions using t-SNE– – TSCNN2. (a)–(c) are the visualization results in MI block. (a) MI input features. (b) Features of spatial convolutional layer in MI block. (c) Features of the temporal convolutional layer in MI block. (d)-(e) are the visualization results in SSVEP block. (d) SSVEP input features. (e) Features of the spatial convolutional layer in SSVEP block. (f) Features of the temporal convolutional layer in SSVEP block. (g) Is the visualization result of fully-connected layer.
3.2. Statistical analysis
We conducted a paired sample t-test to compare the mean values of the experimental results obtained for TSCNN1 and TSCNN2 in each mode. The null hypothesis was that the mean values of the two samples are equal. Our results indicated significant differences ( and p = 0.048, respectively) between the two models in MI and SSVEP mode, while no significant difference was found in hybrid mode (p = 0.561). These findings suggest that TSCNN2 improves the decoding accuracy in MI and SSVEP mode while maintaining similar performance to TSCNN1 in hybrid modes.
Furthermore, we performed a significant difference analysis between TSCNN2 and SCNN. We found no significant difference in MI mode (p = 0.598), indicating that TSCNN2 performs similarly to SCNN in MI mode. This observation supports the notion that TSCNN2 maintains the performance of MI mode while achieving high decoding accuracy in hybrid mode.
Regarding the choice of parameters, we also performed a statistical analysis to evaluate the impact of different dropout rates and activations on the performance of TSCNN2. We found that different dropout rates did not show significant differences in SSVEP and hybrid modes, while in MI mode, there were significant differences between dropout rates of 50% and 25% (p = 0.004) and dropout rate of 50% and 0% (p = 0.001). As a result, we chose a dropout rate of 50% for TSCNN2. We also found that the choice of activation function is critical to the performance of the model [Citation38,Citation39]. However, unlike the dropout rate, none of the four different activations (ReLU, ELU, Softplus, LeakyReLU) showed significant differences in the three modes (p > 0.05).
3.3. Interpretation of connection weights
Our results indicate that TSCNN2 outperforms TSCNN1 in the MI mode. We hypothesize that the features of SSVEP are more dominant and may mask some of the features of MI, leading to a more significant representation of SSVEP after the fusion of the two streams in TSCNN1. During training with the MI mode, the layers in the SSVEP block remain inactive, allowing the model to fine-tune only the kernel weights based on the MI results and thereby improving the representation of MI.
To investigate our hypothesis, we conducted an analysis of the representations of MI and SSVEP in TSCNN1 and TSCNN2. We used the fully connected layer to extract the weights learned by the models, and the concatenation layer connects to the fully connected layer with two feature maps, one for the MI block and the other for the SSVEP block. To quantify the corresponding representation, we employed a threshold-based approach and counted the number of connection weights that exceeded a specified threshold.
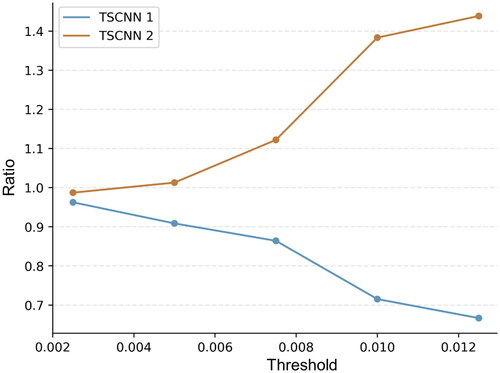
The number of connections for the MI block that are higher than the threshold is denoted as NM, and for the SSVEP block, it is NS. We computed the ratio of NM and NS to reflect the representation ability of the concatenation layer for MI.
A higher ratio indicated a stronger representation ability of the model for MI. We have graphically presented the change in the ratio as a function of the threshold in . Our analysis reveals that TSCNN2 exhibits a higher ratio and hence better representation ability for MI, as compared to TSCNN1. Specifically, with the increase in the threshold, the ratio of TSCNN1 decreases, while that of TSCNN2 increases.
Figure 6. The ratio according to different thresholds. The thresholds are the weights of connections that are relatively high. The vertical axis is the ratio of the number of connections exceeding the threshold in TSCNN1 to the number in TSCNN2. The blue curve is the ratio in TSCNN1, and the red curve is the ratio in TSCNN2.
4. Discussion
In this study, we proposed a deep learning model called TSCNN2, which can provide considerable decoding performance in both single-mode and hybrid-mode scenarios.
4.1. From methodology perspective
Universality and high-precision decoding performance are crucial for BCI systems. However, previous hybrid BCI methods, such as linear discriminant analysis (LDA), CCA, and CSP, have unsatisfactory decoding accuracy and universality [Citation17,Citation20]. As a deep learning model, TSCNN can achieve favorable performance in both single-mode and hybrid-mode scenarios, serving as a universal hybrid BCI framework.
Theoretically, TSCNN can be thought of as a combination of feature extraction and classification of the input. Compared with previous methods, the nonlinearity of TSCNN contributes to learning more complex latent representations and therefore higher performance of decoding. Moreover, TSCNN is well suited to both single-mode and hybrid-mode scenarios, while previous methods can only work in single-mode scenarios.
Another advantage of TSCNN is its interpretability, compared with other two-stream CNNs. We analyzed the connection weights in Section 3.3. and indicate that the fusion block has different representation abilities for the features of each stream, and the differences can be adjusted by applying designed the training strategy, allowing the model to learn the feature of each stream more evenly. The two-stream architecture and the proposed training strategy together achieve satisfactory decoding accuracy and universality for hybrid BCI.
Table 5. The number of weights that are greater than the threshold.
4.2. From application perspective
Compared to previous hybrid BCI methods, TSCNN can achieve satisfactory decoding performance in both single-mode and hybrid-mode scenarios. This flexibility makes TSCNN a promising choice for use in hybrid BCI systems. Subjects with damage to their motor or visual cortex may not be able to generate MI or SSVEP activity, respectively. However, these subjects can still use BCIs by utilizing the available mode. For instance, a subject with motor cortex damage can use the SSVEP mode to control the BCI, while a subject with visual cortex damage can use the MI mode. Additionally, subjects who are proficient in using both modes can generate MI and SSVEP activity simultaneously, allowing for high decoding accuracy. This demonstrates the versatility and adaptability of BCIs for a range of subjects and brain activity patterns. Training and testing TSCNN on a variety of subjects allows for subject-independence, meaning that it is able to overcome inter-subject variability in EEG signals. This makes TSCNN a useful tool for addressing the challenges posed by individual differences in brain activity. Its ability to adapt to a range of subjects demonstrates its potential for use in a variety of contexts.
4.3. Limitations and future works
There are still some limitations to our work. First, the ability to achieve high decoding accuracy of EEG signals with short epoch lengths is essential for the development of effective BCI systems. A shorter epoch length allows for higher temporal resolution, enabling the detection of changes in brain activity at a faster rate. However, in this study, our proposed TSCNN method was trained and tested with 4-s EEG. Further research is needed to investigate the potential of methods that can achieve high decoding accuracy with even shorter epoch lengths. Second, TSCNN is a fully supervised deep learning model, and thus, its training process requires a large amount of labeled data. Supervised deep learning models are highly dependent on the quality and relevance of the training data, and may not generalize well to unseen data. In order to further verify the effectiveness of our proposed method, it is important to conduct additional experiments using expert-annotated datasets. In the future, we also plan to explore unsupervised, semi-supervised, and domain generalization methods as potential avenues for improving the performance of our model. Finally, in our proposed TSCNN model, the MI block and SSVEP block used the same architecture, allowing them to learn the features of their respective modalities. However, there are already many deep learning models that have demonstrated the performance in single-mode MI and SSVEP decoding [Citation4,Citation24,Citation40]. Therefore, further research is needed to investigate fusion frameworks that can achieve higher performance by using these high-performing models architecture in a fusion context.
5. Conclusion
In this study, we put forth a TSCNN architecture that utilizes both SSVEP and MI for the development of a hybrid BCI system that offers high versatility and generalization. Our proposed TSCNN framework is capable of automatically extracting EEG features from both paradigms. We also introduced a novel training strategy for hybrid BCI models, which yielded superior performance in both uni-mode and hybrid-mode scenarios.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Yin W, Liang Z, Zhang J, et al. Partial least square regression via Three-Factor SVD-Type manifold optimization for EEG decoding. In: Chinese conference on pattern recognition and computer vision (PRCV). Berlin: Springer; 2022, pp. 778–787.
- Sadiq MT, Yu X, Yuan Z, et al. Motor imagery EEG signals decoding by multivariate empirical wavelet transform-based framework for robust brain–computer interfaces. IEEE Access. 2019;7:171431–171451. doi: 10.1109/ACCESS.2019.2956018.
- Amin SU, Muhammad G, Abdul W, et al. Multi-CNN feature fusion for efficient EEG classification. In: 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). 2020, pp. 1–6. doi: 10.1109/ICMEW46912.2020.9106021.
- Kwon OY, Lee MH, Guan C, et al. Subject-independent brain–computer interfaces based on deep convolutional neural networks. IEEE Trans Neural Netw Learn Syst. 2020;31(10):3839–3852. doi: 10.1109/TNNLS.2019.2946869.
- Coyle D, Garcia J, Satti AR, et al. EEG-based continuous control of a game using a 3 channel motor imagery BCI: BCI game in 2011 IEEE Symposium on Computational Intelligence, Cognitive Algorithms, Mind, and Brain (CCMB). 2011, p. 1–7.
- LaFleur K, Cassady K, Doud A, et al. Quadcopter control in three-dimensional space using a noninvasive motor imagery-based brain–computer interface. J Neural Eng. 2013;10(4):046003. Available at doi: 10.1088/1741-2560/10/4/046003.
- Akram F, Han SM, Kim TS. An efficient word typing p300-bci system using a modified t9 interface and random Forest classifier. Comput Biol Med. 2015;56:30–36.Available at https://www.sciencedirect.com/science/article/pii/S0010482514002959. doi: 10.1016/j.compbiomed.2014.10.021.
- Jin J, Sellers EW, Zhou S, et al. A p300 brain–computer interface based on a modification of the mismatch negativity paradigm. Int J Neural Syst. 2015;25(3):1550011. Available at doi: 10.1142/S0129065715500112.
- Ravi A, Beni NH, Manuel J, et al. Comparing user-dependent and user-independent training of CNN for SSVEP BCI. J Neural Eng. 2020;17(2):026028. Available at doi: 10.1088/1741-2552/ab6a67.
- Nakanishi M, Wang Y, Wang YT, et al. A comparison study of canonical correlation analysis based methods for detecting steady-state visual evoked potentials. PLoS One. 2015;10(10):e0140703. Available at doi: 10.1371/journal.pone.0140703.
- Decety J. The neurophysiological basis of motor imagery. Behav Brain Res. 1996;77(1–2):45–52. doi: 10.1016/0166-4328(95)00225-1.
- Decety J, Ingvar DH. Brain structures participating in mental simulation of motor behavior: a neuropsychological interpretation. Acta Psychol (Amst). 1990;73(1):13–34. Available at https://www.sciencedirect.com/science/article/pii/000169189090056L. doi: 10.1016/0001-6918(90)90056-l.
- Yu Y, Liu Y, Jiang J, et al. An asynchronous control paradigm based on sequential motor imagery and its application in wheelchair navigation. IEEE Trans Neural Syst Rehabil Eng. 2018;26(12):2367–2375. doi: 10.1109/TNSRE.2018.2881215.
- Wang X, Lu H, Shen X, et al. Prosthetic control system based on motor imagery. Comput Methods Biomech Biomed Engin. 2022;25(7):764–771. pMID: 34533381. doi: 10.1080/10255842.2021.1977800.
- Chen X, Wang Y, Nakanishi M, et al. High-speed spelling with a noninvasive brain–computer interface. Proc Natl Acad Sci USA. 2015;112(44):E6058–E6067. Available at doi: 10.1073/pnas.1508080112.
- Wen D, Liang B, Zhou Y, et al. The current research of combining multi-modal brain-computer interfaces with virtual reality. IEEE J Biomed Health Inform. 2021;25(9):3278–3287. doi: 10.1109/JBHI.2020.3047836.
- Allison BZ, Brunner C, Kaiser V, et al. Toward a hybrid brain–computer interface based on imagined movement and visual attention. J Neural Eng. 2010;7(2):26007. Available at doi: 10.1088/1741-2560/7/2/026007.
- Brunner C, Allison BZ, Krusienski DJ, et al. Improved signal processing approaches in an offline simulation of a hybrid brain–computer interface. J Neurosci Methods. 2010;188(1):165–173. Available at https://www.sciencedirect.com/science/article/pii/S0165027010000786. doi: 10.1016/j.jneumeth.2010.02.002.
- Yu T, Xiao J, Wang F, et al. Enhanced motor imagery training using a hybrid BCI with feedback. IEEE Trans Biomed Eng. 2015;62(7):1706–1717. doi: 10.1109/TBME.2015.2402283.
- Ko LW, Ranga SSK, Komarov O, et al. Development of single-channel hybrid bci system using motor imagery and ssvep. J Healthc Eng. 2017;2017:3789386–3789387. doi: 10.1155/2017/3789386.
- Chi X, Wan C, Wang C, et al. A novel hybrid brain-computer interface combining motor imagery and intermodulation steady-state visual evoked potential. IEEE Trans Neural Syst Rehabil Eng. 2022;30:1525–1535. doi: 10.1109/TNSRE.2022.3179971.
- Yu J, Li C, Lou K, et al. Embedding decomposition for artifacts removal in eeg signals. J Neural Eng. 2022;19(2):026052. doi: 10.1088/1741-2552/ac63eb.
- Qu Y, Jian X, Che W, et al. Transfer learning to decode brain states reflecting the relationship between cognitive tasks. In: Human brain and artificial intelligence. Singapore: Springer Nature; 2023; pp. 110–122.
- Schirrmeister RT, Springenberg JT, Fiederer LDJ, et al. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum Brain Mapp. 2017;38(11):5391–5420. Available at doi: 10.1002/hbm.23730.
- Zheng WL, Dong BN, Lu BL. Multimodal emotion recognition using EEG and eye tracking data in 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. IEEE, 2014, p. 5040–5043.
- Xu X, Tao Z, Ming W, et al. Intelligent monitoring and diagnostics using a novel integrated model based on deep learning and multi-sensor feature fusion. Measurement. 2020;165:108086. doi: 10.1016/j.measurement.2020.108086.
- Amin SU, Alsulaiman M, Muhammad G, et al. Deep learning for EEG motor imagery classification based on multi-layer CNNS feature fusion. Future Gener Comput Syst. 2019;101:542–554. doi: 10.1016/j.future.2019.06.027.
- Lee MH, Kwon OY, Kim YJ, et al. EEG dataset and OpenBMI toolbox for three BCI paradigms: an investigation into BCI illiteracy. GigaScience. 2019;8(5). Available at doi: 10.1093/gigascience/giz002,giz002.
- Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift, in proceedings of the 32nd international conference on machine learning. In: Bach F, Blei D, editors. Proceedings of machine learning research. Vol. 37, Lille, France. PMLR; 2015; pp. 448–456. Available at https://proceedings.mlr.press/v37/ioffe15.html.
- Wang S, Manning C. Fast dropout training. In International conference on machine learning. Atlanta, GA: PMLR; 2013; pp. 118–126.
- Gal Y, Hron J, Kendall A. Concrete dropout. Advances in Neural Information Processing Systems 30; 2017.
- Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: a simple way to prevent neural networks from overfitting. J Machine Learning Res. 2014;15:1929–1958.
- Kingma DP, Ba J. Adam: a method for stochastic optimization. 2014. Available at https://arxiv.org/abs/1412.6980.
- Tang X, Li W, Li X, et al. Motor imagery EEG recognition based on conditional optimization empirical mode decomposition and multi-scale convolutional neural network. Expert Syst Appl. 2020;149:113285. doi: 10.1016/j.eswa.2020.113285.
- Agarap AF. Deep learning using rectified linear units (relu). arXiv Preprint arXiv:1803.08375. 2018.
- Clevert DA, Unterthiner T, Hochreiter S. Fast and accurate deep network learning by exponential linear units (elus). arXiv Preprint arXiv:1511.07289. 2015.
- Zhang X, Zou Y, Shi W. Dilated convolution neural network with LeakyReLU for environmental sound classification. In: 2017 22nd international conference on digital signal processing (DSP). IEEE; 2017, pp. 1–5. doi: 10.1109/ICDSP.2017.8096153.
- Nwankpa C, Ijomah W, Gachagan A, et al. Activation functions: comparison of trends in practice and research for deep learning. arXiv Preprint arXiv:1811.03378. 2018.
- Pedamonti D. Comparison of non-linear activation functions for deep neural networks on MNIST classification task. arXiv Preprint arXiv:1804.02763. 2018.
- Chiang KJ, Wei CS, Nakanishi M, et al. Boosting template-based SSVEP decoding by cross-domain transfer learning. J Neural Eng. 2021;18(1):016002. Available at doi: 10.1088/1741-2552/abcb6e.