
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This study aimed to compare item characteristics and response time between stimulus conditions in computer-delivered listening tests. Listening materials had three variants: regular videos, frame-by-frame videos, and only audios without visuals. Participants were 228 Japanese high school students who were requested to complete one of nine listening test forms. Results showed that item difficulty did not significantly differ between conditions, but item discrimination was much weaker in regular video versions than in the other two conditions. Response time was not different in the three conditions in any quantile. This suggests that listening items full of visual information have different aspects of the general (traditional) listening construct, despite the possibility of construct-irrelevant factors being affected.
Computer-based testing has spread worldwide owing to advancements in technology in education. For example, the College Board’s Digital SAT (Scholastic Assessment Test) is scheduled to be operational in spring 2023, with students taking the test with their own devices or school-managed devices (College Board, Citation2023). Educational Testing Service has also developed a product that allows students to take TOEFL iBT at home (TOEFL Home Edition; Educational Testing Service, Citation2022), increasing international test takers’ opportunities with computer-based testing.
Computerized testing has several significant advantages over traditional paper-and-pencil methods. Wools, Molenaar, and Hopster-den Otter (Citation2019) identified three main perspectives that influence measurement and its surroundings: a) items and tasks, b) test construction, assembly, and delivery, and c) personal needs and preferences. Technology-enhanced items (TEIs) that take advantage of a variety of dynamic interactions with test takers by computers have the potential to measure a broader and deeper range of targeted constructs. The most updated taxonomy of TEIs’ components proposed by Parshall, Harmes, Davey, and Pashley (Citation2010) comprises seven dimensions: (1) assessment structure, (2) response action, (3) media inclusion, (4) interactivity, (5) complexity, (6) fidelity, and (7) scoring method. These seven dimensions are closely related to each other and require the selection of appropriate options to effectively measure the targeted construct. An innovative algorithm that selects test items from large pools allows for the provision of a specified set of tests, such as the assembly of parallel test forms (e.g., van der Linden, Citation2010) and the optimization of adaptive and multi-stage testing (e.g., Yan, von Davier, & Lewis, Citation2014). Test accommodations and accessibility especially for people with disabilities are necessary in large-scale and public tests, such as text and screen sizes, colors, and other special personal assistances.
Video and audio are also among important components of TEIs and have been adopted in the listening testing in advance of other constructs. Some international organizations that provide English proficiency tests for second language (L2) learners, who are not native speakers in English and learn it as a foreign language, have investigated listening comprehension with videos (e.g., Bejar, Douglas, Jamieson, Nissan, & Turner, Citation2000), but a few of them employed videos in the limited number of sections (Wagner & Ockey, Citation2018). Computer-based listening tests are not common in Japan; the national listening tests for university entrance examinations have been administered in the paper-and-pencil way to about 500,000 simultaneous test takers (National Center for University Entrance Examinations, Citation2023). After the COVID-19 pandemic, people have paid more attention to computer-based testing, including the measurement of English proficiency.
Although paper-based methods are the majority of evaluating listening skills in Japan, the demand for fidelity grows stronger. The latest national curriculum for the high school students emphasized the cultivation of their listening skills in daily activities and promoted learning with visuals (Ministry of Education, Culture, Sports, Science and Technology, Citation2018). L2 Listening in English is often aided with visuals such as graphics, captions, or summaries. And it is often said that visuals might have potentials to obtain test takers’ responses in the real world. But indeed, it is long disputed that visual contents have some detrimental effects on the measurement, such as to help immature test takers answer the item correctly.
Basically, statistical properties of technology-enhanced items have been little researched, as Bryant (Citation2017) pointed out. Recently, measurement research on TEIs has been now increasing (e.g., Kim, Tywoniw, & Chapman, Citation2022; Qian, Woo, & Kim, Citation2017); a rationale of the development of TEIs are yet to be established due to a lack of research.
This study sought to investigate the effect of multimedia use on psychometric characteristics, such as difficulty, discrimination power, and response time. An elaborate research design and comprehensive models were employed to address the possibility of conflicting results and ensure compatibility. This study provides the essence of item writing guidelines of listening items with visuals.
1. Background
1.1. A Validity Trade-Off in the Use of Visuals in Computer-Based Listening Tests
The use of videos in computer-based listening assessments has often been questioned. While it is necessary to use audio, visual information is optional. Previous studies have pointed out various advantages and disadvantages of visuals in listening comprehension. An advantage of using visuals is that they improve fidelity. Fidelity is the degree of similarity to a real-world situation (Haladyna & Rodriguez, Citation2013; Loevinger, Citation1957) and is often included in validity inferences of the extrapolation (Kane, Citation2013). A task with higher fidelity may elicit real-life listening skills. Test takers can also reduce the use of cognitive resources in audio-only listening, utilize contextual information, and concentrate on the listening content itself (Shin, Citation1998).
In contrast, visuals also negatively affect test takers’ performance and experience. Lesnov (Citation2022) revealed that visuals may help immature students correctly answer test items for the experiment, in which visual information intentionally promotes correct answers (visual-cued items). This confounding can violate a basic assumption of the scoring inference that test takers can show their skills and abilities without barriers and that test scores reflect their competencies (Wools, Molenaar, & Hopster-den Otter, Citation2019). Additionally, Coniam (Citation2001) found that test takers listening with videos reported negative experiences such as less attention to test items and preferred audio-only listening tests, although their scores were competitive. More significant construct-irrelevant variance and less concentration due to the visual presentation also threaten the validity.
Using visuals in listening assessments creates a conflict between fidelity and construct-irrelevant errors, leading to a validity trade-off. Traditionally, test developers and linguistic researchers have cautioned against using visuals to assess pure listening constructs. Kang, Arvizu, Chaipuapae, and Lesnov (Citation2019) surveyed 20 listening tests for L2 learners and reported that all the tests defined listening constructs as a nonvisual auditory skill. As Bryant (Citation2017) insisted, brand-new constructs are not naturally born from multimedia use itself and must be inferred based on a clear definition and precise measurement without construct-irrelevant errors. Despite the necessity of psychometric considerations for multimedia listening assessments, little research has been conducted to tackle this problem (Batty, Citation2015; Lesnov, Citation2022).
In the field of linguistic studies, much research has been conducted to examine the difficulty of listening tests with video (Batty, Citation2015; Ginther, Citation2002; Lesnov, Citation2022; Suvorov, Citation2009). Unfortunately, inconsistent results have hindered scientific understanding of the influence of videos on difficulty; several studies observed no differences in difficulty between video and audio listening tests (e.g., Coniam, Citation2001; Ginther, Citation2002; Gruba, Citation1997; Pusey, Citation2020), whereas other studies showed that videos made test items easier (e.g., Shin, Citation1998; Wagner, Citation2010, Citation2013). Due to such conflicting outcomes of previous research, there was a need to ascertain better the effects of using videos.
1.2. Content and Context Visuals
The primary source of conflicting results is the type and amount of visual information. Videos often have a wide variety of visuals, both in terms of their content and volume. Previous studies have assumed two types of visuals for listening stimuli: content and context visuals (e.g., Bejar, Douglas, Jamieson, Nissan, & Turner, Citation2000; Ginther, Citation2002; Lesnov, Citation2022; Suvorov, Citation2015). Content visuals include a text and a graphic of the topic or an outline of the speech; context visuals contain the speakers and situations of the speech. Content visuals have critical information to the listening speech or test items, but context ones only aid the understanding of the speech situation (Bejar, Douglas, Jamieson, Nissan, & Turner, Citation2000; Ginther, Citation2002). Two types of visuals yielded different results on item difficulty; content visuals often make items more accessible, whereas context visuals do not (Bejar, Douglas, Jamieson, Nissan, & Turner, Citation2000; Lesnov, Citation2017).
Moreover, some students often paid more attention to content visuals to explore some hints. An eye-tracking study found that test takers watched content videos more often and keenly relative to the context (Suvorov, Citation2015). More items can result from manifestation or hidden cues in content visuals, that is, potential construct-irrelevant factors. The contents included and the amount of visual information should be considered to examine the effect of multimedia on item difficulty precisely in creating listening materials.
In addition to item difficulty, response times provide abundant evidence to grasp other aspects of the construct. A digital testing environment makes it possible to collect the response time data easily and automatically (Li, Banerjee, & Zumbo, Citation2017). In the context of listening assessments, Ockey (Citation2007) performed pioneering research to explore the proportion of the time for watching visuals during the entire testing, where most participants watched videos proportionately longer than images and paid attention to facial and body gestures to understand the speakers’ opinion. Similarly, another study reported students took the most of the time watching videos during the listening test (Wagner, Citation2007). Although the sample size was much smaller in these studies, the results again indicated that context visuals might implicitly work as cues to help answer the item correctly. Response time data often give us helpful information as a shred of evidence for cognitive issues, with care about many factors affecting response time, such as age and computer skills (Li, Banerjee, & Zumbo, Citation2017; Zenisky & Baldwin, Citation2006).
Ockey (Citation2007) examined the time of observing visuals in the total testing time. However, in the case of listening assessment, test developers might be keen to know the total length of the time spent watching videos and answering items to optimize the test assembly. Previous studies have not examined the material difference in response times. When the watching and answering duration is not different between videos and audios, a listening testlet with different media can be treated as the same. Such a finding of response times in a testlet also contributes to the item development process and the editing of a test form.
1.3. Methodological Issues and Statistical Evaluations
The second cause of the inconsistencies can be attributed to unsophisticated data collection and analytic methodologies. Recent studies have pointed out that the contradictory result of visual use can be partly attributed to the broader range of research methods (Suvorov & He, Citation2022). Most studies addressing the difficulty of listening items have compared overall test scores between visual or nonvisual conditions. However, various test items are included in a test form, so the result reflects the sum of smaller and significant item-level differences. A recent study focused on item-level effects of video and audio use by fitting many-facet Rasch models and demonstrated no single main effects of material types on the difficulty; the interaction between visual/audio stimulus and items was also detected (Batty, Citation2015). Experiments and analyses on the same items under different materials provide a new insight into the evaluation of material effects, free from rough and conflicting findings.
Of course, item statistics are not limited to difficulty; item discrimination between video and audio must also be investigated. Comparing differences in discrimination indicates the contribution of items with a specific material type to the construct. It may suggest heterogeneity in a specific condition to identify construct-irrelevant factors. While the central focus in previous studies has been the difficulty, understanding differences in item discrimination between conditions is an unexplored but essential research topic in computerized listening assessments.
1.4. Purpose of This Study
This study aimed to compare item characteristics such as difficulty, discrimination, and a total of page-viewing and answering time between different listening materials. The independent variable was visual/audio presentation stimulus; the dependent variables were difficulty and discrimination of items and response time in a passage, respectively. Three different types of stimuli were examined in this study. The first version was a regular video containing full visual information in every frame with audio in English. The second was a frame-by-frame video, a visual-limited version of each regular video to important scenes. The last one was audio-only condition without any visuals. Three types of stimuli were created to manipulate the amount of visual information.
This study addressed the following three research questions: 1) does the visual/audio presentation stimulus influence item difficulty; 2) does the visual/audio presentation stimulus have an effect on item discrimination; and 3) does the visual/audio presentation stimulus have an effect on response time? For a detailed inquiry of the first two questions, it is necessary to compare statistics in the same set of test items shown under three different stimuli. Meanwhile, a specific set of items cannot be presented repeatedly to the same participants; statistics must be evaluated by the data from independent participant groups. This study needed an elaborate research design to resolve these two constraints at the same time, to test the research questions appropriately. The study mixed the experiment design with item response theory to optimize item presentation, not to repeat the same items, and to investigate difficulty, discrimination under various conditions on the same scale. In addition, item and condition effects must be differentiated to evaluate differences in difficulty and discrimination. This study considered 12 candidate models and adopted the best fitted model to interpret the effects of visuals on such item characteristics.
Response time analysis was performed to answer the third question. As well as the mean, the median and other quantiles were compared among conditions. Analysis of variance and Kruskal–Wallis tests were performed to test condition effects.
2. Methods
2.1. Participants
Two hundred and twenty-eight high school students participated in this study. They were all Japanese and learned English as a second language. Participants joined this study in March 2021, and the test was administered at school.
Before listening tests, the purpose and data use policy was explained to participants. This study excluded the response data of participants who did not provide consent and analyzed the data of 219 students (74 tenth-, 143 eleventh graders, and two unknown). The Ethics Review Board of the author’s institution approved all procedures in this study.
2.2. Materials
This study used four passages (). All the passages had about 30–40 seconds of speech. Two were monologues, and the other two were dialogs. The former two passages had two items, and the latter two had three items each; a total of ten test items were developed. Every item had four options, one key and three distractors. Test items were created to ask participants to select the most appropriate option.
Table 1. Summary of four passage specifications.
This study created three different variants of listening stimuli for each passage: a regular video, a frame-by-frame video, and an audio-only version. Two types of videos only contained context-related information. A regular video with more visual information on context was played smoothly. A frame-by-frame video was a cropped version of the regular video to reduce the visual information. An audio-only version was a single audio file without visuals. Both regular and frame-by-frame videos had no text captions or summaries of the speech. Video clips were developed in 640 × 360px (standard resolution) and 30fps (frame rate).
When creating a video, the following points had to be considered: First, for the reduction of unconscious visual cues, animated characters, instead of accurate human models, were used in videos, as suggested in previous studies on implicit communications containing listening stimuli (Batty, Citation2021; Ockey, Citation2007). Facial and other body signs were not included to avoid test-takers’ inferences on the main point of the speech. Second, visuals were created without visual cues that could help test-takers to identify correct answers. The development of the speech and test items had been completed before the video creation step.
2.3. Experimental Design and Test Forms
This study adopted the Taguchi L9 orthogonal array (Taguchi, Citation1987; Roy, Citation2001 for the detailed introduction to the design of experiment and Taguchi approach) to satisfy these features and optimize test delivery (). L9 orthogonal array has four three-level factors; in this study, a factor corresponded with a set of items, and a level did with a condition. L9 orthogonal array enables us to assign four factors (i.e., test items in this study) independently and make a combination of other items. The right side of the displays how a set of items under the three conditions were included in nine test forms. L9 orthogonal array also makes it possible to collect response data with a common-item design and to compare item characteristics between conditions on a common scale. The number of conditions that each participant was exposed to varied, according to such design of experiment. For example, students delivered the Form 1 answered test items with the regular videos for all four passages; those delivered the Form 2 did with one regular video and three frame-by-frame videos.
Table 2. Taguchi’s L9 (34) orthogonal array and data collection design.
Such a test delivery also made it possible to balance the sample sizes between conditions; almost the same number of participants answered the items in all three conditions, with an effort of the randomized delivery of nine test forms. This produced condition parameters estimated with about the same level of precision.
2.4. Procedure
The assessment was administered on the TAO, an open-source computer-based platform (Open Assessment Technologies, Citation2022). Participants gathered in the classroom and took a test by the school. Computers were school-managed or BYOD (Bring-Your-Own Device) or BYAD (Bring-Your-Assigned Device) ones.
Participants were asked to log in to the testing system with their ID and password. The format of login IDs were constructed with the one alphabet and four digits of numeric, such as “a1001.” One of the nine different test forms was delivered by their login IDs and randomly assigned to the participants; a remainder of the last three digits of their login IDs divided by nine corresponded with the assigned test form. A participant who was delivered “a1001” answered the form 1, and “a1002” did the form 2. They were required to answer 10 test items in a test in 10 minutes. Participants were allowed to go back to the previous items and skip the following items within a test. Options were randomly ordered and presented to participants according to the previous study addressing the option position (Holzknecht et al., Citation2021).
The play of videos and audio was controlled in the following three ways. First, videos and audio did not start automatically; students were allowed to play them according to their timing. Second, visual and auditory media could be played at most twice because of the short answering time. Third, pauses and playbacks were not permitted.
2.5. Data Analysis
Statistical analyses were performed in three parts: a) a classical item analysis, b) IRT analyses, and c) response time analyses. The statistical software, R, was used in throughout the analytic process (R Core Team, Citation2022).
In the first step, a classical item analysis was performed to evaluate p-values and item-total correlations. These statistics were calculated in two ways: three different versions were mixed (overall 10 items) and separated (condition-partitioned 30 items). This study analyzed test items with 10% to 90% p-values and higher than .15 correlations; whether to include items outside these thresholds in the subsequent analysis was carefully examined. In addition, the descriptive statistics of raw scores and the estimated coefficient alpha levels were reported.
Second, this study examined item response models to evaluate item characteristics by condition. With reference to previous studies (Batty, Citation2015; Lesnov, Citation2022), many-facet Rasch models (MFRMs) were used, including item and condition effects. Condition effects were dummy-coded and the audio-only treatment treated as zero for the audio-only condition.
displays a summary of all the 12 candidate models in the current study. The first three models (the models 1 to 3) were a family of 1PLMs with item discriminations fixed to 1, and the latter nine models (the models 4 to 12) were 2PLMs. The candidate models had item difficulty and discrimination structure. Model 1 had the simplest item difficulty structure; difficulty parameters were estimated only for items, so it was a Rasch model. Model 2 had main effects for items and conditions; the condition-specific difficulty was assumed to be the same regardless of items and separately added to the primary item difficulty. Model 3 contained an interaction effect of two facets; a Rasch model fitting to the data showed that test items with the same content and different stimuli were treated as independent. The entire estimation was performed using the TAM package (Robitzsch, Kiefer, & Wu, Citation2022). This study selected the best-fitted model in 12 models in terms of likelihood, AIC, and BIC. Item fit statistics were also examined.
Table 3. Results of classical item analysis.
Table 4. A summary of examined 12 models and results of the model fit.
Lastly, the mean response time of each passage was compared between conditions (Zenisky & Baldwin, Citation2006). One-way between-subject analysis of variance was performed to examine the effect of stimulus on response time by item. Effect sizes, , and those confidence intervals were also evaluated. The response time data were preprocessed when test takers visited more than once. The system recorded cumulated duration from the first to the final attempts to answer the items, in line with Question and Test Interoperability (QTI) version 2.2.4 (IMS Global Learning Consortium, Citation2022). The time to step on other items before returning to the item was also included in the data. Post-processed response data were dropping the time spent on other items to represent the actual length of response time in all attempts. This study confirmed that the sum of response times for all four passages was within 600 seconds (10 minutes).
3. Results
3.1. Descriptive Statistics of Item Response
shows the overall and condition-partitioned statistics in the classical item analysis and the number of respondents for each item. The table also shows that the overall tendency was that the differences in p-values were not observed between conditions. The item Q02-1s were much easier, and p-values exceeded 90%. Item-Total correlation in the Q04–2-RV revealed a negative value. Coefficient alpha was .673 for overall 10 items and .795 for all 30 condition-partitioned items. Three easy items (Q02-1s) and one with a negative discrimination power (Q04–2-RV) were excluded from the analyses afterward.
3.2. Differences in Item Characteristic Curves by Condition
shows the log-likelihood and information criteria for all 12 models. AIC preferred Model 8, the model with only the main effects of items and conditions for difficulties and discriminations, while BIC recommended Model 1 (a simple Rasch model). This study selected Model 8 since an interpretation of condition effects was available. The complementary analysis using Model 1 was also performed to check the compatibility of item difficulty parameters between the two models. EAP estimates of thetas in Model 8 were not different between nine test forms (F[8, 204] = 1.146, p = .334, = .04, 95%CI = [.00, .08]).
shows the parameter estimates in Models 1 and 8. Estimates in the two models were approximately the same. In the table, item fit statistics such as outfit and infit mean square and t statistics were also reported. Item fit statistics did not indicate any overfits or underfits.
Table 5. Parameter estimates and item fit statistics in the Model 1 and 8.
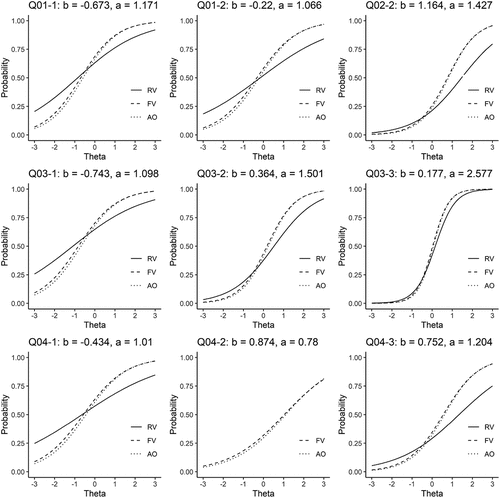
As shown in , item difficulty (b) did not significantly differ between the three conditions. The results of difficulty parameters were that items with RVs were slightly harder (0.133, 95%CI = [.00, .26]), and those with FV were a bit easier (−0.118, 95%CI = [−.25, .01]), which were almost at the same level. Item discriminations differed between conditions; it was lower in RV items than AO items (−0.540) but as high in FV items as AO items (−0.047). Condition parameters were constrained in this model, so those standard errors and confidence intervals were not directly evaluated. Standard errors for item parameters varied from .05 in average; it can be inferred that discriminations between RV and AOs were much lower, and those between AO and FV were not significantly different. displays item characteristic curves for each condition based on Model 8. The figure revealed that the position of ICCs in RV items was a little on the right side, and the slope in RV items was slower than in the other two conditions.
Figure 1. Item characteristic curves by condition.
3.3. Differences in Page-Viewing Duration by Condition
shows descriptive statistics of response times by condition. Overall, there were no significant differences observed between the three conditions. The mean and all percentiles of response times for passages Q01 and Q02, with two test items, were slightly smaller in the audio-only condition than in other video ones, unlike the passages Q03 and Q04.
Table 6. Descriptive statistics of response time by condition.
Results of one-way between-subject ANOVAs showed that no significant differences nor no large effect were detected in three of four passages (F[2, 210] = 1.95, p = .145, = .02, 95%CI = [.00, .06] for Q02; F[2, 210] = 2.45, p = .089,
= .02, 95%CI = [.00, .07] for Q03; F[2, 210] = 0.36, p = .696,
= .00, 95%CI = [.00, .03] for Q04). In one passage (Q01), the significant difference between three types of stimulus were observed (F[2, 210] = 4.91, p = .008); response time in the frame-by-frame was longer than in the audio-only condition (p = .007 for multiple comparisons using Bonferroni method). But indeed, the effect size was small, and its confidence interval included zero (
= .04, 95%CI = [.00, .11]). Overall results did not provide strong evidence on the effect of stimulus types on response time.
4. Discussion
This study aimed to examine the influence of video/audio materials on item difficulty, discrimination, and response time in computer-based listening tests. Results showed that item difficulty and response time did not differ between conditions. This study also found that item discrimination was lower in the regular videos than in the other two conditions. These results provide a new horizon for investigating the psychometric properties of video-mediated listening items in digital environments.
4.1. Item Difficulty
Previous findings on the difficulty in listening items and tests with visuals had conflicted with one another. Batty (Citation2015) suggested visual effects had item-dependent features in a few items, but this study revealed that item and material effects worked independently. Batty (Citation2015) also described the detail of item-dependent features and concluded that test takers infer the emphasis from facial expressions and gestures in visuals. The visuals used in this study can successfully suppress the implicit information, such as the speech’s main point, and result in the equivalence of the difficulty.
From the viewpoint of item writers and test developers, the same items with the same difficulty level were desirable, regardless of listening media types. Although lower discrimination powers in a regular video should be considered together, the homogeneity of the difficulty may reduce the workload of these stakeholders.
4.2. Item Discrimination
According to the results of this study, lower item discrimination was observed in the regular-video condition. This novel finding provides an important implication in language testing and educational measurement. Such results may come from two possible sources: construct-irrelevant factors specific in a regular video version or underrepresenting visual listening constructs.
The first explanation is that a regular video might include construct-irrelevant factors, unlike the other two materials. It is natural because a frame-by-frame video reduces visual information found in a regular video; the visual information for immature test-takers to answer the item correctly, which item writers did not notice, may be contained in the regular video. A large amount of visual information would have always created risks with low item discrimination if it is valid. It is recommended that the visuals should be limited as much as possible in a listening assessment.
There is another explanation for low item discrimination. Listening with the full visuals in the video has different aspects from ordinary listening skills, and the scale of visual listening skills is represented when all the materials have vast visual information. Considering the result of this study that higher item discriminations were observed in frame-by-frame video and audio-only versions, the scale constructed in this study was mainly a reflection of audio-based listening construct. The result of low discrimination in the regular video condition may suggest the heterogenicity of visual listening and the traditional listening construct. When new visual-related listening skills have different aspects from the original, it may be rather productive to develop a new separate listening scale only with the regular video items, not to contain other types of video items, than to identify a specific influence of construct-irrelevant factor in the regular videos.
This study focused on visual material differences in item discrimination in computer-based listening tests, which had not been addressed in previous studies. Technology-enhanced items (TEIs) additionally contain a more significant number of construct-irrelevant potentials to affect correct response than those in the paper-and-pencil testing. Low item discrimination provides suggestions for ways to improve item writing.
4.3. Response Time
This study showed that visual/auditory material differences did not impact response times at every quantile. A previous study only measured a video watching time for content and context visuals (Suvorov, Citation2015). This study examined the total viewing time, displaying a particular listening passage, questions, and options in the same scrollable page. This response time data included processes for listening to audios with or without visuals, answering, and reviewing. Tiny differences in overall response time between conditions implied that listening material types did not affect the cognitive load of test takers within the passage. In a passage (Q01), significant difference was detected between FV and AO, but the effect size was small. The video of the Q01 might contain implicit information for assisting to answer the item Q01–2 correctly.
This result can be interpreted in the following two ways. The first is that the videos presented in this study did not contain the visual cues for test takers to answer the items correctly, and answering time was also the same in any conditions. Visual information did not extend the total answering time partly because this study might successfully limit visual cues directly connected to the correct answer.
Another possibility is that the longer time for video watching and the shorter time for answering may be canceled out in the regular video and a total time was comparable with the other two versions that justify the interpretation of the result. Such a relationship indicates that test takers could quickly answer the test item whenever aided by visuals. This study did not segregate listening and answering components; thus, additional research is necessary to test this hypothesis.
The stated objective of the study was met with a large sample size to understand the differences in response times Earlier research on response time in listening tests collected the data manually with small sample sizes (Ockey, Citation2007; Wagner, Citation2007, Citation2010). The present study addressed this problem but could not identify any meaningful difference between conditions. Response time analysis is one of the most useful methodologies to check construct-irrelevant elements concerning listening materials, as evident in the pilot test.
4.4. Limitations and Future Directions
There are two major limitations to investigating listening material effects on item characteristics and response time. First, the topic’s complexity and the speech’s characteristics must be considered. The topic in this study was about students’ daily lives and is easy to understand. Moreover, the speech length was about 30–40 seconds, which was relatively short. Videos may be more advantageous to L2 test takers when they listen to complex or abstract topics or longer speech to reduce cognitive loads. This study included dialogs and monologues, which may also impact the item statistics. Future studies should employ various listening materials and examine the effects on item characteristics.
Second, the methodology of reducing the cost of video development should be considered. Even though the research found a validity compromise of the measurement efficiency and the fidelity, that is, a frame-by-frame video, an enormous cost of video creation is still a significant burden to the test development. The effective ways for low-cost development of videos can be explored in practical use.
Findings in this study are considered as useful in three levels: for international, domestic, and classroom testing. International English proficiency tests such as TOEFL and TOEIC have test takers from various countries and regions. Cultural bias may result in differential item functioning, a serious issue affecting measurement. Frame-by-frame visuals may allow test takers with a variety of educational background to understand the listening contexts in the same way, keeping item difficulties and discriminations homogeneous. National listening tests, in countries where English is not the first language, can also make use of this findings by showing real-world situations where L2 learners are difficult to imagine only with audio in frame-by-frame videos. It is suggested that fidelity and quality of measurement can be balanced by regulating the amount of visual information in videos. In classroom testing, frame-by-frame videos may have the potential to keep learners concentrated on stimulus and not to distract other interruptions, since the amount of visual information was reduced in development. Response time equivalence among material types, found in this study, should be a part of evidence of creating visuals to make students concentrate on just “listening.”
Visual use in listening assessments has been historically challenged due to the validity trade-off and inconsistency of the findings. It is useful to illustrate promises and pitfalls in multimedia use for test developments in future studies. A scale construction of visual-centered listening skills would be critical. Listening item development with videos should be sophisticated in its process and workflow. Developing guidelines to show what types of visuals should be included or excluded in videos is a valuable task for computer-based listening assessments.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Batty, A. O. (2015). A comparison of video- and audio-mediated listening tests with many-facet Rasch modeling and differential distractor functioning. Language Testing, 32(1), 3–20. doi:10.1177/0265532214531254
- Batty, A. O. (2021). An eye-tracking study of attention to visual cues in L2 listening tests. Language Testing, 38(4), 511–535. doi:10.1177/0265532220951504
- Bejar, I., Douglas, D., Jamieson, J., Nissan, S., & Turner, J. (2000). TOEFL 2000 listening framework: A working paper. (TOEFL Monograph Series, Report No. 19). Princeton, NJ: Educational Testing Service. https://www.ets.org/research/policy_research_reports/publications/report/2000/iciu
- Bryant, W. (2017). Developing a strategy for using technology-enhanced items in large-scale standardized tests. Practical Assessment, Research & Evaluation, 22(1), 1–10.
- College Board (2023). Digital SAT. https://satsuite.collegeboard.org/digital
- Coniam, D. (2001). The use of audio or video comprehension as an assessment instrument in the certification of English language teachers: A case study. System, 29(1), 1–14. doi:10.1016/S0346-251X(00)00057-9
- Educational Testing Service (2022). TOEFL iBT test. https://www.ets.org/toefl/test-takers/ibt/register/at-home-requirements.html
- Ginther, A. (2002). Context and content visuals and performance on listening comprehension stimuli. Language Testing, 19(2), 133–167. doi:10.1191/0265532202lt225oa
- Gruba, P. (1997). The role of video media in listening assessment. System, 25(3), 335–345. doi:10.1016/S0346-251X(97)00026-2
- Haladyna, T. M., & Rodriguez, M. C. (2013). Developing and validating test items. New York, NY: Routledge.
- Holzknecht, F., McCray, G., Eberharter, K., Kremmel, B., Zehentner, M., Spiby, R., & Dunlea, J. (2021). The effect of response order on candidate viewing behaviour and item difficulty in a multiple-choice listening test. Language Testing, 38(1), 41–61. doi:10.1177/0265532220917316
- IMS Global Learning Consortium (2022). IMS question & test interoperability assessment test, section and item information model. https://www.imsglobal.org/question/qtiv2p1/imsqti_infov2p1.html
- Kane, M. T. (2013). Validating the interpretations and uses of test scores. Journal of Educational Measurement, 50(1), 1–73. doi:10.1111/jedm.12000
- Kang, T., Arvizu, M. N. G., Chaipuapae, P., & Lesnov, R. O. (2019). Reviews of academic English listening tests for non-native speakers. International Journal of Listening, 33(1), 1–38. doi:10.1080/10904018.2016.1185210
- Kim, A. A., Tywoniw, R. L., & Chapman, M. (2022). Technology-enhanced items in grades 1–12 English language proficiency assessments. Language Assessment Quarterly, 19(4), 343–367. doi:10.1080/15434303.2022.2039659
- Lesnov, R. O. (2017). Using videos in ESL listening achievement tests: Effects on difficulty. Eurasian Journal of Applied Linguistics, 3(1), 67–91. doi:10.32601/ejal.461034
- Lesnov, R. O. (2022). Furthering the argument for visually inclusive L2 academic listening tests: The role of content-rich videos. Studies in Educational Evaluation, 72, 101087. doi:10.1016/j.stueduc.2021.101087
- Li, Z., Banerjee, J., & Zumbo, B. D. (2017). Response time data as validity evidence: Has it lived up to its promise and, if not, what would it take to do so. In B. D. Zumbo & A. M. Hubley (Eds.), Understanding and investigating response processes in validation research (pp. 159–177). Springer. doi:10.1007/978-3-319-56129-5_9
- Loevinger, J. (1957). Objective tests as instruments of psychological theory. Psychological Reports, 3(3), 635–694. doi:10.2466/pr0.1957.3.3.635
- Ministry of Education, Culture, Sports, Science and Technology. (2018). Koutougakkou Gakusyu Shidou Yoryo Kaisetsu :Gaikokugohen Eigohen [The national curriculum in English for high schools]. https://www.mext.go.jp/content/1407073_09_1_2.pdf [in Japanese]
- National Center for University Entrance Examinations. (2023). Eigo Listening Ni Tsuite [On English listening tests]. https://www.dnc.ac.jp/kyotsu/listening.html [in Japanese]
- Ockey, G. J. (2007). Construct implications of including still image or video in computer-based listening tests. Language Testing, 24(4), 517–537. doi:10.1177/0265532207080771
- Open Assessment Technologies. (2022). TAO testing. https://www.taotesting.com/
- Parshall, C. G., Harmes, J. C., Davey, T., & Pashley, P. J. (2010). Innovative items for computerized testing. In W. J. van der Linden & C. A. W. Glas (Eds.), Elements of adaptive testing (pp. 215–230). Springer. doi:10.1007/978-0-387-85461-8_11
- Pusey, K. (2020). Assessing L2 listening at a Japanese university: Effects of input type and response format. Language Education and Assessment, 3(1), 13–35. doi:10.29140/lea.v3n1.193
- Qian, H., Woo, A., & Kim, D. (2017). Exploring the psychometric properties of innovative items in computerized adaptive testing. In H. Jiao & R. W. Lissitz (Eds.), Technology enhanced innovative assessment: Development, modeling and scoring from an interdisplinary perspective (pp. 95–116). Charlotte, NC: Information Age Publishing.
- R Core Team. (2022). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/
- Robitzsch, A., Kiefer, T., & Wu, M. (2022). TAM: Test analysis modules. R package version 4.0-16. https://CRAN.R-project.org/package=TAM
- Roy, R. K. (2001). Design of experiments using the Taguchi approach: 16 steps to product and process improvement. New York, NY: A Wiley Interscience Publication.
- Shin, D. (1998). Using videotaped lectures for testing academic listening proficiency. International Journal of Listening, 12(1), 57–80. doi:10.1080/10904018.1998.10499019
- Suvorov, R. (2009). Context visuals in L2 listening tests: The effects of photographs and video vs. audio-only format. In C. A. Chapelle, H. G. Jun, & I. Katz (Eds.), Developing and evaluating language learning materials (pp. 53–68). Ames, IA: Iowa State University.
- Suvorov, R. (2015). The use of eye tracking in research on video-based second language (L2) listening assessment: A comparison of context videos and content videos. Language Testing, 32(4), 463–483. doi:10.1177/0265532214562099
- Suvorov, R., & He, S. (2022). Visuals in the assessment and testing of second language listening: A methodological synthesis. International Journal of Listening, 36(2), 80–99. doi:10.1080/10904018.2021.1941028
- Taguchi, G. (1987). System of experimental design: Engineering methods to optimize quality and minimizing costs. White Plains, NY: UNIPUB/Kraus International Publications.
- van der Linden, W. J. (2010). Linear models for optimal test design. New York, NY: Springer.
- Wagner, E. (2007). Are they watching? Test-taker viewing behavior during an L2 video listening test. Language Learning & Technology, 11(1), 67–86. https://eric.ed.gov/?id=EJ805397
- Wagner, E. (2010). Test-takers’ interaction with an L2 video listening test. System, 38(2), 280–291. doi:10.1016/j.system.2010.01.003
- Wagner, E. (2013). An investigation of how the channel of input and access to test questions affect L2 listening test performance. Language Assessment Quarterly, 10(2), 178–195. doi:10.1080/15434303.2013.769552
- Wagner, E., & Ockey, G. J. (2018). An overview of the use of audio-visual texts on L2 listening tests. In E. Wagner & G. J. Ockey (Eds.), Assessing L2 listening: Moving toward authenticity (pp. 130–144). Amsterdam, Netherlands: John Benjamins Publishing Company.
- Wools, S., Molenaar, M., & Hopster-den Otter, D. (2019). The validity of technology enhanced assessments: Threats and opportunities. In B. P. Veldkamp & C. Sluijter (Eds.), Theoretical and practical advances in computer-based educational measurement (pp. 3–19). Springer. doi:10.1007/978-3-030-18480-3_1
- Yan, D., von Davier, A. A., & Lewis, C. (2014). Computerized multistage testing: Theory and applications. Boca Rato, FL: CRC Press.
- Zenisky, A. L., & Baldwin, P. (2006). Using item response time data in test development and validation: Research with beginning computer users. Paper Presented at the Annual Meeting of The National Council on Measurement in Education, San Francisco, CA, April 8-10, 2006.