
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The artificial intelligence-based allocation of resources can substantially reduce resource wastage and cost. Cloud resource allocation and management have appeared to be the central research direction. Computing through the cloud looks like improvements in network, parallel, and distributed computing. This presentation explains how scheduling works in a cloud environment by comparing it to natural selection, a concept that describes biological evolution. A strategy to reduce the time needed to find a solution by proposing an optimal solution. algorithm adds flexibility, adaptability, parallel processing, and global optimization. Furthermore, the cost function is used to find a beneficial solution by studying the operational completion time, cost of resources, and load balancing. benchmark problems tested through the algorithm show that it performs better than the other algorithms. The algorithm simultaneously solves the scheduling tasks of virtual machines and self-guided vehicles in a cloud computing environment. We Also tested for significant differences among algorithms and the number of jobs using an analysis of variance. Finally, task scheduling using the suggested algorithm indicates an improvement.
1. Introduction
With the rapid development of internet technology, cloud computing has attracted People’s attention as an innovative model (Panda and Jana, Citation2015). Open service hacks and deploys technology in the cloud to generate revenue by selling computing and storage numbers to users (Yiqiu et al., Citation2019), meaning that users can easily access the network, pay for usage, and pay by model. Based on a previous study (Mesbahi et al., Citation2016). Firms and users can rent resources to service providers to save costs, and service providers can earn money by providing services quickly (Lin et al., Citation2014). Cloud computing has the advantages of excellent access, data security, unlimited storage, mobility, and enhanced collaboration by using virtual resources (Garg et al., Citation2013). Unlike rental services in cloud computing, only cloud vendors serve cloud users (Tsai et al., Citation2013). Owing to the need for air services, service providers have increased the quantity and quality of the services they provide (Agarwal and Jain, Citation2014). Currently, the focus has shifted to a more efficient and effective plan to improve resource use. These computational problems are NP-hard (Dordaie and Navimipour, Citation2018). Hence, researchers have shifted their focus toward cloud computing to address tasks such as pandas and similar endeavors (Panda and Jana, Citation2019) provided scheduling methods by considering time and resource usage for assessment. Hussain et al. (Citation2021) proposed an efficient job scheduling technique along with energy savings. In addition, researchers have gained extra attention through heuristic algorithms with issues such as scheduling tasks and balancing of load. placement of the virtual machines and vehicle systems. This algorithm is a hybrid algorithm based on biological evolution and natural selection (Zhou et al., Citation2020) which effectively illustrates the concept by drawing parallels between cloud resource allocation and biological evolution, emphasizing adaptability and optimization. This strategy yields the solution as an initial and current state, along with crossover and mutation (Song et al., Citation2020). The solution space problem is a trend in the population (Pan et al., Citation2021). The hybrid technique switches the closest optimal solutions to optimal global solutions using an algorithm procedure (Zhu et al., Citation2022). From the perspective of this work, the hill-climbing algorithm was hybridized with a genetic algorithm (GA) to enhance the speed of the algorithm in the global search space (Pan et al., Citation2020). The contributions of this study are as follows.
It creates an assessment function using the operational completion time, energy, and reliability.
It suggests advanced hill-climbing. It merges with a new evolutionary trend.
Comparison of the anticipated strategy with another algorithm employing 40 benchmark sets for testing with simulation. benchmark problems are utilized to evaluate the algorithm’s performance, demonstrating its superiority over other algorithms in resource allocation tasks within cloud computing environments.
Utilizing analysis of variance (ANOVA) or evaluating the algorithm’s performance.
The design of this essay’s design is as follows, related work in the second part, the third part of the system model, the proposed algorithm in the fourth part, the fifth section introduces ANOVA, and finally the sixth section introduces analysis of results.
2. Related work
Cloud computing is a pool of resources that can be provisioned and deployed instantly upon user request (Keshanchi et al., Citation2017). If the number of user requests increases, the cloud computing workload decreases (Liu et al., Citation2014). Therefore, the algorithm is responsible for allocating the work needed by the user to the service to shorten the time to complete the work, improve the service, and reduce the cost, infrastructure balance, and load (Alhaidari et al., Citation2019; Geng et al., Citation2019; Halim and Hajamydeen, Citation2019). In cloud environments, scheduling strategies encompass various areas. Scheduling issues within the cloud can be categorized into distinct domains, and Quality of Service (QoS) based scheduling tasks can be further divided into different methods (Arunarani et al., Citation2019). He et al. (Citation2003) proposed a service quality-based method to perform the next scheduling with the min- min heuristic. Wu et al. (Citation2013) allocated resources to the analysis strategy tested it by loading weights on a specific criterion and found its performance to be good. Potluri and Rao (Citation2020) discussed cost reduction and time lag issues and improved resource utilization. Ali et al. (Citation2017) created a rule based on the behavior of the tasks and assigned them to the servers the algorithm groups work by specification and the tasks need to be queued for distribution. Hanini et al. (Citation2019) developed a strategy to determine the number of virtual machines in conjunction with the management of virtual machine demands to manage energy consumption.
Ant colony optimization (ACO) is efficient for solving NP-complete problems, particularly dynamic scheduling task problems (Gupta and Garg, Citation2017). Liu et al. (Citation2014) developed a model to minimize energy consumption by reducing the number of substantial clouds using ACO algorithms to solve the virtual machine placement problem. Xin et al. (Citation2016) proposed a model to reduce energy consumption and operation time by advancing the scheduling system through a scheduling strategy based on ACO. Delavar et al. (Citation2012) studied grid computing in terms of QoS for scheduling task problems through the ACO approach with an objective function to minimize the operational completion time and cost. Wu et al. (Citation2021) developed a model to reduce resource waste using an assessment model to monitor changes in energy consumption. Kumar and Venkatesan (Citation2019) designated hybrid algorithms with ACO and GA for multi-objective task scheduling systems without considering the security and load of virtual machines. Ragmani et al. (Citation2020) considered an algorithm with alternating parameters to efficiently optimize the operation time and allocation of resources. Sun et al. (Citation2013) developed an advanced ACO called the period ant colony optimization (PACO) algorithm to solve scheduling problems. Pandey et al. (Citation2010) suggested a PSO algorithm to solve scheduling task problems to minimize the execution and transport costs as the objective functions and were then compared with the best resource selection (BRS) algorithm. Juan et al. (Citation2012) addressed the cost vector and potential solutions were found using the PSO algorithm. Alsaidy et al. (Citation2020) considered an objective function to maximize the effectiveness of the cost and consumption of resources using an advanced PSO algorithm. Wen et al. (Citation2012) developed a hybrid model to enhance the convergence speed of an algorithm by using ACO and PSO.
Genetic Algorithms (GA) can solve NP-hard problems, particularly task scheduling. Kumar and Sharma (Citation2020) proposed an enhanced genetic algorithm methodology for optimizing task selection by selecting the correct VM. Kumar and Verma (Citation2012) suggested a hybrid genetic algorithm and contrasted its outcomes against a standard genetic algorithm utilizing a time-based objective function across various environments. Nagar et al. (Citation2018) proposed a task scheduling model to reduce the time to completion by estimating the earliest completion time for some small projects using the predicted earliest time to finish (PEFT) genetic algorithm. Virangii et al. (2021) proposed a design to optimize the balance of product stability and processing time through hybrid electric search using a genetic algorithm. Manasrah and Ba Ali (Citation2018) worked on a hybrid GA-PSO algorithm for resource allocation in a cloud environmentto minimize the workload and cost performance. Pirozmand et al. (Citation2021) used cloud simulation software to solve the hybrid genetic algorithm problem to optimize virtual machine allocation and energy usage.
Fuzzy Algorithms (FA) are useful for solving NP problems, especially task scheduling. Fahmy (Citation2010) developed a nonperiodic task scheduling model using a fuzzy time-based algorithm and minimizing all tasks over time. Lv et al. (Citation2021) proposed a multi-objective algorithm to optimize queue processing. Zhou et al. (Citation2019) introduced an Infrastructure as a Service (IaaS) model aimed at enhancing the operational speed of intelligent machines through elevated performance standards. Sujana et al. (Citation2020) proposed a cost estimation matrix (CPM) based scheduling heuristic optimization algorithm that merges optimal scheduling with a virtual budget allocation technique. Rezaeipanah et al. (Citation2022) developed a management system for virtual machines in cloud environments. the algorithm tackles scheduling tasks for both virtual machines and self-guided vehicles concurrently, showcasing its versatility and applicability in diverse cloud computing scenarios.
Based on the above kind of literature, it is evident that subsequent research gaps have been identified. Many research activities have been performed using heuristic algorithms or meta-heuristic algorithms, and the simultaneous exploration of task scheduling for machines and automated guided vehicles (AGVs) has not yet been explored using hybrid algorithms. In this study task scheduling was performed using a hybrid hill-climbing algorithm to investigate the task completion time. Numerous researchers have deliberated on this topic and heuristic strategies for cloud computing that have been documented in publications. However, most of them are executed separately not in a hybrid manner, and task scheduling strategies in hybridization have not been examined. Therefore, this study concentrates on scheduling tasks using hybrid cloud computing strategies.
3. System design
Scheduling tasks can be divided into job scheduling and task scheduling in cloud computing. Task scheduling is the most frequently used scheduling method (Padillo et al., Citation2017; Xu et al., Citation2016). An important issue in scheduling tasks is determining how to assign jobs to processors to achieve a minimized completion time and cost with high system performance and efficiency (Selvarani and Sadhasivam, Citation2010).
3.1. Cloud computing system design
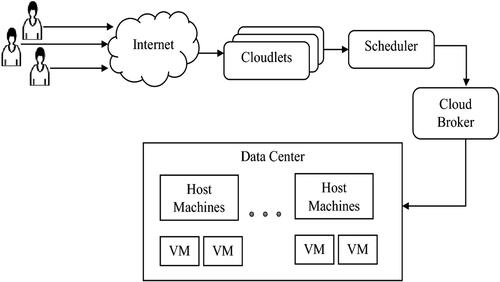
In cloud computing, all tasks are independent and are not prioritized, as shown in . When a user submits a task from the cloud, the task is queued by master task management and scheduling mechanisms to self-deploy tasks. Driving and using virtual machines. A virtual machine has characteristics such as the number of machines, processing environment, memory, and bandwidth task and possesses two defining attributes: the number of tasks and their respective lengths.
Figure 1. Task scheduling model through cloud computing.
3.2. Evaluation model
This study considers the scheduling task performance in terms of completion time, cost, and degree of imbalance. The performance indicators are explained in detail below: task scheduling performance mainly includes makespan, cost, profit, completion time, and waiting time through the indicators of cloud computing.
Notations
Table
Variables
Mixed integer linear programming (MILP) model
(1)
(1)
Subjected to
(2)
(2)
(3)
(3)
(4)
(4)
(5)
(5)
(6)
(6)
(7)
(7)
(8)
(8)
(9)
(9)
(10)
(10)
(11)
(11)
constraint 1st is stated as an objective function. 2nd constraint is indicated as a job start time of ≥0. Limitation 3rd is a precedence constraint. Constraints 4th, 5th, 6th, and 7th Indicate that the two jobs cannot be programmed simultaneously on the same machine. Constraints 8, 9, 10, and 12 mandate that the operational conclusion time should not be any less than the maximum completion time of the final operation among all jobs. Finally, we evaluated the efficacy of the constraints in the experimental section. The indexing of machines and vehicles is unclear because each job routing is known in the design of the smart manufacturing industry through artificial intelligence. The aim is to minimize the completion time, formulated nonlinearly using mixed integer programming.
4. Schedule model
A suitable heuristic algorithm is crucial for obtaining the optimum solution for scheduling problems with minimum time. Attaining specific goals through heuristic algorithms with a set of rules and multiple options to establish the evolution function. This method enriches the efficiency of a search process by yielding the claims of the organization and the extensiveness of the best.
4.1. Hill climbing
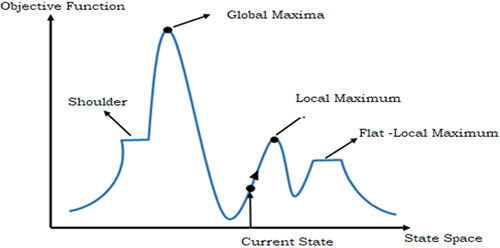
To attain the peak of the mountain or problem a local search method, such as a hill-climbing algorithm, continuously transports in the direction of rising height or value. Through the algorithm, the problem reaches the highest value, and it terminates when no neighbor has a higher value. The various stages of hill climbing algorithms are represented graphically in , and the pseudocode is presented in Algorithm 1. Evaluate the cost or objective function of both the current and previous states of the problem and then choose the superior one as the current state.
Figure 2. State-space vs objective function.
Algorithm 1.
Hill climbing algorithm.
Step 1: Initial solution = i
Step 2: f(s) ≤ f(i) S €Neighbours (i) do
Step 3: S €Neighbours (i), Generates;
Step 4: if cost (s) > cost (i) then
Step 5: Restore (s) with the I;
Step 6: Exit
In Algorithm 1, (i) the existing state within the solution space, denoted a represents the neighboring state in the hill climbing algorithm. After calculating the cost function, if the cost function of the neighboring state is greater than the existing state, then restore the neighboring state to the existing state or else keep the existing state as an optimum state for the next search. The above algorithm was integrated with the vehicle heuristic algorithm shown in Algorithm 2.
Algorithm 2.
Vehicle heuristic algorithm.
Step 1: parameters initialize
Step 2: generate initial solution ();
Step 3: machine number identification; M1–M4; ∀j J; ∀ i
I
Step 4: V(1) = i(1); V(2) = i(2); V{1, 2}; i{1, 2…. n}
Step 5: POMN; previous operation machine number; M1–M4; ∀j J; ∀ i
I
Step 6: VRT; vehicle ready time; V(1, 2)
Step 7: VETT; vehicle empty travel time; V(1, 2); ∀j J; ∀ i
I.
Step 8: VLTT; vehicle loaded travel time; V(1, 2); ∀j J; ∀ i
I.
Step 9: Current location of the vehicle; Vi = Mi; ∀v
Step 10: Vehicle availability; If V(1) TT ≤ V(2)TT; V1; otherwise V(2)
Step 11: termination criterion
Step 12: Exit
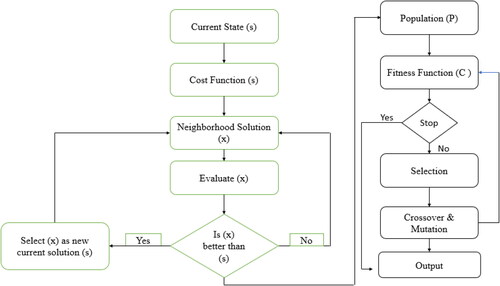
In Algorithm 2, the operation sequence is identified through the algorithm: according to the sequence identifying the machine number the 1st AGV assigns to the first job after the 2nd AGV assigns to the second job. From 3rd job onwards, the vehicle heuristic algorithm is incorporated to assign tasks to vehicles depending on their availability. After obtaining the optimal sequence through an integrated hill climbing algorithm, a neighbor sequence is generated for crossover and mutation operations, which a shown in Algorithm 3. The algorithm incorporates flexibility, adaptability, parallel processing, and global optimization techniques to speed up finding optimal resource allocation solutions.
Algorithm 3.
Genetic Algorithm.
Step 1: Initiation
Step 2: Population generation (); Pg; g{1, 2 … n}
Step 3: Fitness function; OCT; ∀j J; ∀ i
I
Step 4: Repeat; i{1, 2 … n}
Step 5: Selection; ∀j J; ∀ i
I; M1–M4;
Step 6: Crossover; Pg; and generate OCTCg
Step 7: Mutation; Pg; and generate OCTMg
Step 8: Fitness function; OCT; ∀j J; ∀ i
I
Step 9: termination criterion
Step 10: Exit
In Algorithm 3, after population generation from Algorithms 1 and 2 crossover and mutation operations are implemented to obtain an enhanced optimum solution. The hybrid algorithm is an alternative to the regular metaheuristic that we demonstrate in .
Figure 3. Hybrid hill climbing algorithm.
4.2. Experiments
Hill Climbing (HC) heuristic search implementation job number 1 out of 10 numbers and layout numbers 1, out of four layouts deliberated as an example (Ulusoy et al., Citation1997). A coding system is utilized to label the example problems found in the initial column of . The digits following “1.1” signify the specific job set and layout, considering both process time and travel time. Following this, the digit succeeding “1.10” indicates the job set and layout, with the processing time doubled and the travel time halved, resulting in an additional set of 40 problems. Similarly, the digit after “1.11” denotes the job set and layout, with the processing time tripled and the travel time halved, thus generating another set of 40 problems (Alla et al., Citation2023). The algorithm evaluates the CT for ten jobs and the sequence is accomplished based on the neighbor.
Hill climbing algorithm enlightened for job number 1:
Step 1: Select the job number from 10 jobs.
Job number 1, layout number 1, number of jobs 5, number of operations 13.
Step 2: Current state.
4-5-6-1-2-3-12-13-10-11-7-8-9
According to the search, the technique evaluates the cost function as shown in . The cost function evaluates operational completion time (OCT), cost of resources, and load balancing to determine the most advantageous resource allocation solutions.
Table 1. Cost function calculation for J1 and L1 benchmark problems.
Step 3: Generate a neighbor sequence of the current state.
4-5-6-12-13-1-2-3-10-11-7-8-9—fitness function-190
Step 4: Compare these two solutions and select the best one
Sequence 1: 4-5-6-1-2-3-12-13-10-11-7-8-9: fitness function: 173
Sequence 2: 4-5-6-12-13-1-2-3-10-11-7-8-9: fitness function: 190
The best sequence was 4-5-6-1-2-3-12-13-10-11-7-8-9 with an OCT of 173.
Step 5: Generate another neighbor sequence from the best one.
4-5-6-1-2-3-10-11-12-13-7-8-9 -fitness function-179
Step 6: Compare the OCT for the new neighbor solution and the best one from the previous comparison and select the finest one.
The best sequence is sequence 1.
Create an additional neighboring sequence to incorporate into the Genetic Algorithm
Step 7: Combine the genetic algorithm and hill climbing algorithm
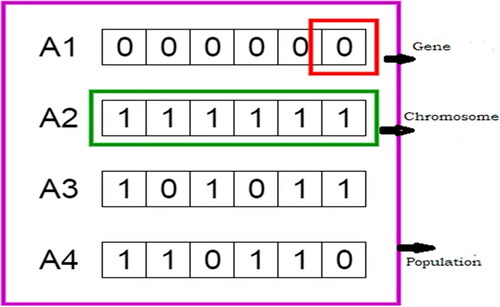
Holland et al. (1975) developed genetic algorithms (GAs) which are applied to different fields of engineering problems very effectively. It is very popular among all the algorithms. The algorithm mechanism is based on the natural evolutionary process simplifications shown in .
Figure 4. Population, chromosome, and genes in the genetic algorithm.
4.2.1 Genetic operators
Crossover and mutations are accomplished to produce new chromosomes.
4.2.2 Crossover operators
Based on the literature survey, single- and double-point crossovers were deemed as shown in .
Figure 5. The crossover position within the genetic algorithm.
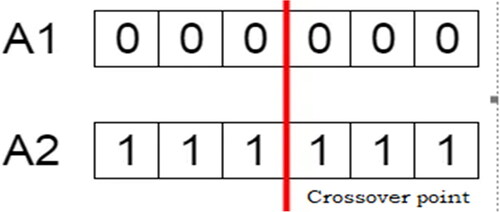
(i) Single-point crossover
parents are swapped with the genes.
Before:
Random sequence 1: 2-1|-4-5-3
neighbor sequence 2: 2-4|-1-3-5
After:
Random sequence 1: 2-1-1-3-5
neighbor sequence 2: 2-4-4-5-3
After repair and replacement:
Random sequence 1: 2-1-4-3-5
neighbor sequence 2: 2-4-1-5-3
According to job order operations, the sequences are: 4-5-6-1-2-3-10-11-7-8- 9-12-13-OCT-.179
4-5-6-10-11-1-2-3-12-13-7-8-9-OCT-185
(ii) Two-point crossover
genes in between two cut points are exchanged.
Random sequence 1: 2|-1-4-3|-5
neighbor sequence 2: 2-4-1-5-3
After Repair and replacement:
Random sequence 1: 2|-4-1-3|-5neighbor sequence 2: 2-|1-4-5|-3
According to job order operations sequences are:
4-5-6-10-11-1-2-3-7-8-9-12-13- OCT- 178
4-5-6-1-2-3-10-11-12-13-7-8-9 - OCT- 197
4-5-6-10-11-1-2-3-7-8-9-12-13- OCT- 178
4.2.3 Mutation operators
Mutation operations performed on chromosomes to efficiently search for the search space are shown in .
Figure 6. The mutation process within a GA.

4.2.4 Random mutation
Randomly selecting chromosomes is repaired, if necessary, after swapping two genes randomly.
Before: 2-4-1-3-5, After: 3-4-1-2-5
Operation sequence is: 7-8-9-10-11-1-2-3-4-5-6-12-13-OCT-173
4.2.5 Adjacent mutation
Exchange the genes that are adjacent to each other.
Before 3-4-1-2-5, After 3-4-2-1-5
The operation sequence was 7-8-9-10-11-4-5-6-1-2-3-12-13-OCT-173, shown in .
Table 2. Benchmark problems calculation for neighbor sequence.
Step 7: Repeat the procedure until execution.
To get the effective performance of the algorithm at least 10 to 20 runs are required to note down.
The different functions and layouts used to determine the completion time through HCA are presented in .
Table 3. Cost function through hill-climbing algorithm.
The above table gives the test results for the 40 problems using the hill climbing algorithm for the travel time vs process time ratio (t/p > 0.25). The OCT for job sets and layouts for the genetic hill climbing algorithm is presented in .
Table 4. Cost function through the hybrid algorithm.
Table 5. Percentage improvement between CDS and HCS.
The above table gives the test results for the 40 problems using the genetic hill climbing algorithm, which includes crossover, again with the mutations for the travel time vs process time ratio (t/p > 0.25). illustrates the performance of CDS (Prasad et al., Citation2023) and HCA, showing the percentage improvement between the algorithms.
The highest percentage improvement is 120, and the lowest percentage improvement is 18.06 when comparing HCA with the CDS (Prasad et al., Citation2023) algorithm while observing from the above table. lists the performance metrics of the HCS and GHCA, including the percentage improvement between the HCA and GHCA.
Table 6. Percentage improvement between HCS and GHCS.
The highest percentage improvement of the genetic hill climbing algorithm was 11.85 and the lowest percentage improvement of the genetic hill climbing algorithm was −0.60 when compared with the HCA.
4.3. Cloud environment
Following the simulation, two distinct cloud computing environments were established to assess the effectiveness of the algorithms. The results are presented in and .
Table 7. Simulation cloud environment 1.
Table 8. Simulation cloud environment 2.
and illustrate how the two meteorological conditions aid in demonstrating the stability and performance of the algorithm. The Wilcoxon signed-rank test scores for the CDS, HCA, and GHCA algorithms are displayed in when the correlation was set to 0.05. The (+) sign indicates that GHCA performance is the best at the level of significance 0.05. Current operation and indicator. This shows that the GHCA performs worse than the algorithm.
Table 9. Comparison with the results of CDS, HCA, and GAHCA at a significant level a = 0.05.
shows that the GAHCA algorithm outperforms the CDS and HCA in terms of overall performance.
5. Significant differences among algorithms and number of jobs
The Friedman test is a non-parametric test developed by Friedman. As with ANOVA, differences between the treatments were detected. Analysis of variance (ANOVA) is a tool used to test the equality of two or more individual instruments. According to R.A Fisher, ANOVA is “the separation of the variable in one group due to the variable’s association with the other group.” Statistics can be categorized as univariate (univariate) or multivariate. Two levels (two-way). The significance of differences was assessed using an analysis of variance (ANOVA), which allowed for a statistical comparison of algorithm performances and their scalability with varying job loads.
5.1. Friedman test
It is an alternative to one-way ANOVA with frequent measures.
5.1.1 Elements
Three or more strategies of measures at investigational conditions. There was only one dependent it can be a ratio interval or ordinal.
5.1.2 Assumptions
A random sample from the population and the sample is not normally distributed.
5.1.3 Hypothesis
Classified as alternate and null hypothesis.
Null hypothesis: Probability distributions for conditions are the same.
Alternate hypothesis: Differing from each other there are at least two of them.
H1: At least two of them show significant differences.
H0: P1 = P2 = P3 = …… Pk; p = Median
5.1.4 Statistics for assessment
n = Number of jobs total, k = measured blocks
Rk = ranks sum for a strategy i.
5.1.5 Decision rules
Decision-making is based on below below-mentioned rules.
Fr > Critical value—reject the hypothesis.
P-value ≤ (alpha)—reject the null hypothesis.
Post hoc analysis was performed if the null hypothesis was rejected to find a given pair difference.
5.1.6 Friedman test
Step 1: Define the hypothesis.
H0 (null hypothesis): All three Strategies have the same probability distribution.
H1 (alternate hypothesis)
Step 2: Significance
Significance level = 0.05
Step 3: DOF calculation
DF = number of strategies to be measured (K) − 1, DF = 3 − 1 = 2.
Step 4: Chi-Square value.
alpha = 0.05 and DF = 2. Critical Chi-square value = 5.991
Step 5: Decision rule
You have the option to verify either of the two rules
FR > 5.991, reject the Null Hypothesis.
P-value ≤ (alpha), reject the null hypothesis.
Step 6: The ranks are in ascending order and are shown in .
Table 10. Ranks according to Friedman test.
Step 7: Statistics assessment calculation
where n = number of jobs, k = number of strategies, and Rj2 = sum of ranks for the jth group.
Step 8: Result
Rejected the null hypothesis because Q was greater than the Critical Chi-square value. Therefore, we conclude that. There is a notable contrast in the decrease in the average OCT in a minimum of one pair of methods. Finally, the ANOVA test is presented in Section 5.2.
5.2. Two-way ANOVA
Step 1: Hypotheses
Null Hypotheses: H01: μM1= μM2= μM3 (for treatments) (algorithms)
In other words, there was an absence of notable divergence in the average execution time among the three algorithms.
H02: μS1= μS2= μS3 = μS4 = …… = μS40 (for blocks) (number of jobs)
Alternative Hypotheses:
H11: There exists a distinction among the three algorithms.
H12: There is a difference among the means of at least one of the 40 items compared to the other.
Step 2: Data
Information retrieved from and
Step 3: significance level α = 5%
Step 4: Statistic test
F0t (treatment) = MST/MSE, F0b (block) = MSB/MSE
Step 5: Calculation of the Test Statistic
Squares:
Correction factor:
Total sum of squares:
Treatments due to sum of squares:
Blocks due to sum of squares:
Error due to sum of squares:
Mean sum of squares for treatment: MST = =
= 2429
Mean sum of squares for blocks:
Mean sum of squares for errors:
ANOVA table (two-way)
Step 6: Critical value
Values for treatment and blocks
F (39,78) 0.05 = 1.55
F (02,78) 0.05 = 3.113
Step 7: Decision
Calculation F0t = 2.05 > f(39.78)0.05 = 1.55, and by rejecting the null hypothesis, we deduce that there is no substantial difference in OCT among our methods. The conclusion is presented in this section.
Calculate F0b = 89.43 > f(2,78)0.05 = 3.113, rejecting the null hypothesis and the conclusion drawn is that there exists no notable difference in the OCT across forty questions.
illustrates the performance of the algorithm for non-equilibrium tasks in two distinct environments, with a range of 50 to 500. The x-axis denotes the function, and the y-axis represents the measurement function value. A comparison between CDS, HCA, and GHCA is shown in the figure below.
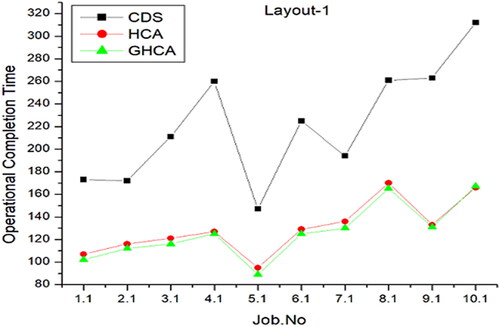
shows the performance of the HCA, GAHCA, and CDS algorithms within a smart manufacturing environment, utilizing 10 tasks with layout number 1. The X-axis indicates the number of jobs, while the y-axis represents the performance evaluation value.
Figure 7. Number of jobs vs performance matrix for layout 1.
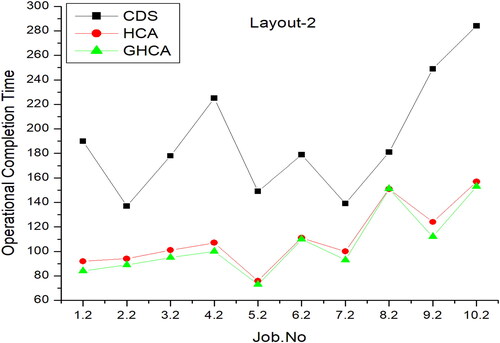
shows the performance of the HCA, GAHCA, and CDS algorithms in a smart manufacturing setting, employing 10 tasks with layout number 2. The X-axis denotes the number of jobs, and the y-axis represents the performance evaluation value.
Figure 8. Number of jobs vs performance matrix for layout 2.
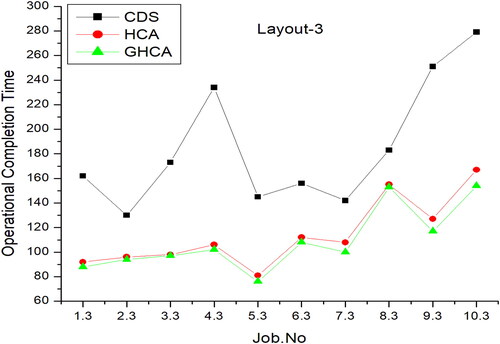
illustrates the performance of the HCA, GAHCA, and CDS algorithms within a smart manufacturing environment using 10 tasks with layout number 3. The X-axis indicates the number of jobs, while the y-axis represents the value of the performance evaluation.
Figure 9. Number of jobs vs performance matrix for layout 3.
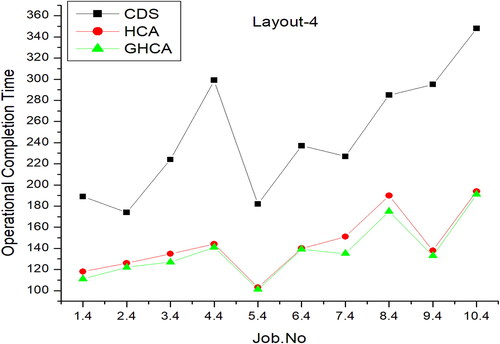
shows the performance of the HCA, GAHCA, and CDS algorithms within a smart manufacturing environment using 10 tasks with layout number 4. The X-axis displays the number of jobs, while the y-axis shows the value of the performance evaluation metric. Genetic Hill Climbing demonstrated superior performance compared to the other algorithms based on observations from the graph.
Figure 10. Number of jobs vs performance matrix for layout 4.
6. Conclusion
This study focuses on addressing task scheduling challenges within cloud computing environments by proposing a hybrid hill-climbing algorithm. Task scheduling using the suggested algorithm leads to a notable improvement in performance, suggesting enhanced efficiency, reduced resource wastage, and cost savings in cloud computing environments. This new algorithm aims to strike a balance between solution optimization and exploration capabilities. The implementation was conducted using Python, wherein the algorithm was tested across 10 different problem sets featuring various layouts. Python code encompassed multiple algorithms, including HCA and GHCA, integrated within the vehicle system.
The results were derived from 20 iterative runs of an evolutionary procedure. The conclusions drawn from this research were primarily based on the application of HCA and GHCA to NP-hard problems. The evaluations encompassed 40 problems categorized across different layouts: layout 1 with 10 job sets, layout 2 with 20 job sets, layout 3 with 30 job sets, and layout 4 with 40 job sets. For instance, “10.1” signifies the 10th job set within layout 1.
The analysis indicated that GHCA outperformed other algorithms based on observations. Hypothesis testing was conducted to ascertain the significant differences between the algorithms and job set problems. Experiments revealed that the hybrid strategy was particularly effective in addressing NP-hard problems, resulting in reduced cost functions and enhanced utilization of virtual machine resources.
Future endeavors include delving into multi-objective problems and exploring dynamic load balancing mechanisms to further mitigate cloud resource waste the study hints at future research directions by demonstrating the effectiveness of the proposed algorithm, encouraging further exploration into refining its capabilities or applying it to different cloud computing scenarios for even greater optimization and efficiency gains
Author contributions
Methodology, MNR and AVSRP. Software, MNR. Validation, MNR and LSP. Formal analysis, MNR. Writing-original draft preparation, MNR and SK. writing-review and editing, VSK. Visualization, MNR. Supervision, ND and AKS. Project administration, MNR.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding author.
References
- Agarwal, D., & Jain, S. (2014). Efficient optimal algorithm of task scheduling in the cloud computing environment. arXiv:1404.2076.
- Alhaidari, F., Balharith, T., & Al-Yahyan, E. (2019). Comparative analysis for task scheduling algorithms on cloud computing. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia (pp. 1–6). https://doi.org/10.1109/ICCISci.2019.8716470
- Ali, H., Saroit, I. A., & Kotb, A. M. (2017). Grouped task scheduling algorithm based on QoS in a cloud computing network. Egyptian Informatics Journal, 18(1), 11–19. https://doi.org/10.1016/j.eij.2016.07.002
- Alla, V. R. S. P., Medikondu, N. R., Kanakavalli, P. B., & Ravulapalli, V. P. (2023). Design and development of a mixed integer programming model for scheduling tasks through artificial intelligence. International Journal on Interactive Design and Manufacturing (IJIDeM), https://doi.org/10.1007/s12008-023-01488-1
- Alsaidy, S. A., Abbood, A. D., & Sahib, M. A. (2020). Heuristic initialization of PSO task scheduling algorithm in cloud computing; computer and information sciences. Journal of King Saud University.
- Arunarani, A., Manjula, D., & Sugumaran, V. (2019). Task scheduling techniques in cloud computing: A literature survey. Future Generation Computer Systems. 91, 407–415. https://doi.org/10.1016/j.future.2018.09.014
- Delavar, A. G., Bayrampoor, J., Boroujeni, A. R. K., & Broumandnia, A. (2012). Task scheduling in a grid environment with ant colony method for cost and time. International Journal of Computer Science, Engineering and Applications, 2(5), 1–12. https://doi.org/10.5121/ijcsea.2012.2501
- Dordaie, N., & Navimipour, N. J. (2018). Hybrid particle swarm optimization and hill climbing algorithm for task scheduling in cloud environments. ICT Express, 4(4), 199–202. https://doi.org/10.1016/j.icte.2017.08.001
- Fahmy, M. (2010). Fuzzy algorithm for scheduling non-periodic jobs on a soft real-time single processor system. Ain Shams Engineering Journal. 1(1), 31–38. https://doi.org/10.1016/j.asej.2010.09.004
- Pirozmand, P., Hosseinabadi, A. A. R., Farrokhzad, M., Sadeghilalimi, M., Mirkamali, S., & Slowik, A. (2021). Multi-objective hybrid genetic algorithm for task scheduling problem in cloud computing. Neural Computing and Applications, 33(19), 13075–13088. https://doi.org/10.1007/s00521-021-06002-w
- Garg, S. K., Versteeg, S., & Buyya, R. (2013). Framework for ranking of cloud computing services. Future Generation Computer Systems. 29(4), 1012–1023. https://doi.org/10.1016/j.future.2012.06.006
- Geng, X., Yu, L., Bao, J., & Fu, G. (2019). Task scheduling algorithm based on priority list and task duplication in a cloud computing environment. In Web Intelligence (Vol. 17, pp. 121–129). IOS Press. https://doi.org/10.3233/WEB-190406
- Gupta, A., & Garg, R. (2017) Load balancing based task scheduling with ACO in cloud computing [Paper presentation]. In Proceedings of the 2017 International Conference on Computer and Applications (ICCA), Doha, Qatar (pp. 174–179). https://doi.org/10.1109/COMAPP.2017.8079781
- Halim, A. H. A., & Hajamydeen, A. I. (2019) Cloud computing based task scheduling management using task grouping for balancing [Paper presentation]. In Proceedings of the 2019 IEEE 9th International Conference on System Engineering and Technology (ICSET), Shah Alam, Malaysia, 7 October (pp. 419–424). https://doi.org/10.1109/ICSEngT.2019.8906508
- Hanini, M., Kafhali, S. E., & Salah, K. (2019). Dynamic VM allocation and traffic control to manage QoS and energy consumption in the cloud computing environment. International Journal of Computer Applications in Technology, 60(4), 307–316. https://doi.org/10.1504/IJCAT.2019.101168
- He, X., Sun, X., & Von Laszewski, G. (2003). QoS guided min-min heuristic for grid task scheduling. Journal of Computer Science and Technology, 18(4), 442–451. https://doi.org/10.1007/BF02948918
- Hussain, M., Wei, L. F., Lakhan, A., Wali, S., Ali, S., & Hussain, A. (2021). Energy and performance-efficient task scheduling in heterogeneous virtualized cloud computing. Sustainable Computing: Informatics and Systems, 30, 100517. https://doi.org/10.1016/j.suscom.2021.100517
- Juan, W., Fei, L., & Aidong, C. (2012). Improved PSO-based task scheduling algorithm for cloud storage systems. Advances in Information Sciences and Service Sciences, 4, 465–471.
- Keshanchi, B., Souri, A., & Navimipour, N. J. (2017). An improved genetic algorithm for task scheduling in cloud environments using priority queues includes formal verification, simulation, and statistical testing. Journal of Systems and Software. 124, 1–21. https://doi.org/10.1016/j.jss.2016.07.006
- Kumar, A., & Venkatesan, M. (2019). Multi-objective task scheduling using hybrid genetic-ant colony optimization algorithm in the cloud environment. Wireless Personal Communications, 107(4), 1835–1848. https://doi.org/10.1007/s11277-019-06360-8
- Kumar, M., & Sharma, S. C. (2020). PSO-based novel resource scheduling technique to improve QoS parameters in cloud computing. Neural Computing and Applications, 32(16), 12103–12126. https://doi.org/10.1007/s00521-019-04266-x
- Kumar, P., & Verma, A. (2012). Independent task scheduling in cloud computing using an improved genetic algorithm. International Journal of Advanced Research in Computer Science, 2, 5.
- Lin, W., Liang, C., Wang, J. Z., & Buyya, R. (2014). Bandwidth-aware divisible task scheduling for cloud computing. Software: Practice and Experience, 44(2), 163–174. https://doi.org/10.1002/spe.2163
- Liu, C. Y., Zou, C. M., & Wu, P. (2014). A task scheduling algorithm based on genetic algorithm and ant colony optimization in cloud computing. In Proceedings of the 2014 13th International Symposium on Distributed Computing and Applications to Business, Engineering and Science, China, 24–27 November (pp. 68–72).
- Liu, X. F., Zhan, Z. H., Du, K. J., & Chen, W. N. (2014). Energy-aware virtual machine placement scheduling in cloud computing based on ant colony optimization approach. In Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation, 12–16 July (pp. 41–48).
- Lv, L., Zhou, X. D., Kang, P., Fu, X. F., & Tian, X. M. (2021). Multi-objective firefly algorithm with hierarchical learning. Journal of Network Intelligence, 6, 411–427.
- Manasrah, A. M., & Ba Ali, H. (2018). Workflow scheduling using hybrid GA-PSO algorithm in cloud computing. Wireless Communications and Mobile Computing, 2018, 1–16. https://doi.org/10.1155/2018/1934784
- Mesbahi, M. R., Hashemi, M., & Rahmani, A. M. (2016). Performance evaluation and analysis of load balancing algorithms in cloud computing environments [Paper presentation]. Proceedings of the 2016 Second International Conference on Web Research (ICWR), Tehran, Iran, 27–28 April (pp. 145–151). https://doi.org/10.1109/ICWR.2016.7498459
- Nagar, R., Gupta, D. K., & Singh, R. M. (2018). Time effective workflow scheduling using genetic algorithm in cloud computing. International Journal of Information Technology and Computer Science, 10(1), 68–75. https://doi.org/10.5815/ijitcs.2018.01.08
- Padillo, F., Luna, J. M., Herrera, F., & Ventura, S. (2017). Mining association rules on big data through MapReduce genetic programming. Integrated Computer-Aided Engineering, 25(1), 31–48. https://doi.org/10.3233/ICA-170555
- Pan, J. S., Liu, N., & Chu, S. C. (2020). Hybrid differential evolution algorithm, and its application in unmanned combat aerial vehicle path planning. IEEE Access,.8, 17691–17712. https://doi.org/10.1109/ACCESS.2020.2968119
- Pan, J. S., Song, P. C., Pan, C. A., & Abraham, A. (2021). Phasmatodea population evolution algorithm, and its application in 5G heterogeneous network downlink power allocation problem. Journal of Internet Technology, 22, 1199–1213.
- Panda, S. K., & Jana, P. K. (2015). Efficient task scheduling algorithms for a heterogeneous multi-cloud environment. The Journal of Supercomputing, 71(4), 1505–1533. https://doi.org/10.1007/s11227-014-1376-6
- Panda, S. K., & Jana, P. K. (2019). Energy-efficient task scheduling algorithm for heterogeneous cloud computing systems. Cluster Computing, 22(2), 509–527. https://doi.org/10.1007/s10586-018-2858-8
- Pandey, S., Wu, L., Guru, S. M., & Buyya, R. (2010). Particle swarm optimization-based heuristic for scheduling workflow applications in cloud computing environments [Paper presentation]. In Proceedings of the 2010 24th IEEE International Conference on Advanced Information Networking and Applications, Perth, WA, Australia, 20–23 April (pp. 400–407). https://doi.org/10.1109/AINA.2010.31
- Potluri, S., & Rao, K. S. (2020). Optimization model for QoS-based task scheduling in the cloud computing environment. Indonesian Journal of Electrical Engineering and Computer Science, 18(2), 1081–1088. https://doi.org/10.11591/ijeecs.v18.i2.pp1081-1088
- Prasad, S., Medikondu, A. V. R. N. R., Reddy, M. B. S. S., Rakesh, K., Shanthi Swaroopini, A., & Sahu, P. K. (2023) Mathematical model for vehicle scheduling [Paper presentation]. In AIP Conference Proceedings (pp 1–8). https://doi.org/10.1063/5.0143073
- Ragmani, A., Elomri, A., Abghour, N., Moussaid, K., & Rida, M. (2020). FACO: A hybrid fuzzy ant colony optimization algorithm for virtual machine scheduling in high-performance cloud computing. Journal of Ambient Intelligence and Humanized Computing, 11(10), 3975–3987. https://doi.org/10.1007/s12652-019-01631-5
- Rezaeipanah, A., Mojarad, M., & Fakhari, A. (2022). Provide a new approach to increase fault tolerance in cloud computing using fuzzy logic. International Journal of Computers and Applications. 44(2), 139–147. https://doi.org/10.1080/1206212X.2019.1709288
- Selvarani, S., & Sadhasivam, G. S. (2010) Improved cost-based algorithm for task scheduling in cloud computing [Paper presentation]. In Proceedings of the 2010 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 28–29 December (pp. 1–5).
- Song, P. C., Chu, S. C., Pan, J. S., & Yang, H. (2020) Phasmatodea population evolution algorithm and its application in a length-changeable incremental extreme learning machine [Paper presentation]. In Proceedings of the 2020 2nd International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–25 October (pp. 1–5). https://doi.org/10.1109/IAI50351.2020.9262236
- Sujana, J. A. J., Revathi, T., & Rajanayagam, S. J. (2020). Fuzzy-based security-driven optimistic scheduling of scientific workflows in cloud computing. IETE Journal of Research, 66(2), 224–241. https://doi.org/10.1080/03772063.2018.1486740
- Sun, W., Zhang, N., Wang, H., Yin, W., & Qiu, T. (2013). PACO: A period ACO Based Scheduling algorithm in cloud computing [Paper presentation]. In Proceedings of the 2013 International Conference on Cloud Computing and Big Data, Fuzhou, China, 16–19 December (pp. 482–486).
- Tsai, J. T., Fang, J. C., & Chou, J. H. (2013). Optimized task scheduling and resource allocation in a cloud computing environment using improved differential evolution algorithm. Computers & Operations Research. 40(12), 3045–3055. https://doi.org/10.1016/j.cor.2013.06.012
- Ulusoy, G., Sivrikaya-Şerifoǧlu, F., & Bilge, Ü. (1997). A genetic algorithm approach to the simultaneous scheduling of machines and automated guided vehicles. Computers & Operations Research, 24(4), 335–351. https://doi.org/10.1016/S0305-0548(96)00061-5
- Velliangiri, S., Karthikeyan, P., Arul Xavier, V., & Baswaraj, D. (2021). Hybrid electro search with genetic algorithm for task scheduling in cloud computing. Ain Shams Engineering Journal. 12(1), 631–639. https://doi.org/10.1016/j.asej.2020.07.003
- Wen, X., Huang, M., & Shi, J. (2012). Study on resources scheduling based on ACO algorithm and PSO algorithm in cloud computing [Paper presentation]. In Proceedings of the 2012 11th International Symposium on Distributed Computing and Applications to Business, Engineering Science, Guilin, China, 19–22 October (pp. 219–222).
- Wu, J., Xu, M., Liu, F. F., Huang, M., Ma, L., & Lu, Z. M. (2021). Solar wireless sensor network routing algorithm based on multi-objective particle swarm optimization. Journal of Information Hiding and Multimedia Signal Processing, 12, 1–11.
- Wu, X., Deng, M., Zhang, R., Zeng, B., & Zhou, S. (2013). Task scheduling algorithm based on QoS-driven in cloud computing. Procedia Computer Science. 17, 1162–1169. https://doi.org/10.1016/j.procs.2013.05.148
- Xin, G. (2016). Ant colony optimization computing resource allocation algorithm based on the cloud computing environment [Paper presentation]. In Proceedings of the International Conference on Education, Management, Computer and Society, Shenyang, China
- Xu, X., Cao, L., & Wang, X. (2016). Adaptive task scheduling strategy based on dynamic workload adjustment for heterogeneous Hadoop clusters. Systems Journal, IEEE. 10(2), 471–482. https://doi.org/10.1109/JSYST.2014.2323112
- Yiqiu, F., Xia, X., & Junwei, G. (2019). Cloud computing task scheduling algorithm based on improved genetic algorithm [Paper presentation]. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic, and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March (pp. 852–856).
- Zhou, J. L., Chu, S. C., Peng, Y. J., Huang, K. C., & Pan, J. S. (2020). An advanced clustering algorithm based on k-means and Phasmatodea population evolution algorithms data science. Pattern Recognition. 4, 41–56.
- Zhou, X., Zhang, G., Sun, J., Zhou, J., Wei, T., & Hu, S. (2019). Minimizing cost and makespan for workflow scheduling in the cloud using fuzzy dominance sort-based HEFT. Future Generation Computer Systems. 93, 278–289. https://doi.org/10.1016/j.future.2018.10.046
- Zhu, Y., Yan, F., Pan, J. S., Yu, L., Bai, Y., Wang, W., He, C., & Shi, Z. (2022). Multigroup-Based Phasmatodea population evolution algorithm with multistrategy for IoT electric bus scheduling. Wireless Communications and Mobile Computing, 2022, 1500646.