
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this age of data, digital tools are widely promoted as having tremendous potential for enhancing food safety. However, the potential of these digital tools depends on the availability and quality of data, and a number of obstacles need to be overcome to achieve the goal of digitally enabled “smarter food safety” approaches. One key obstacle is that participants in the food system and in food safety often lack the willingness to share data, due to fears of data abuse, bad publicity, liability, and the need to keep certain data (e.g., human illness data) confidential. As these multifaceted concerns lead to tension between data utility and privacy, the solutions to these challenges need to be multifaceted. This review outlines the data needs in digital food safety systems, exemplified in different data categories and model types, and key concerns associated with sharing of food safety data, including confidentiality and privacy of shared data. To address the data privacy issue a combination of innovative strategies to protect privacy as well as legal protection against data abuse need to be pursued. Existing solutions for maximizing data utility, while not compromising data privacy, are discussed, most notably differential privacy and federated learning.
Introduction
The societal and economical importance of food safety issues
Food safety is a global concern. The WHO estimates that a total of 600 million cases of foodborne illness, including 420,000 deaths due to foodborne illness occur globally every year (Jayasena et al. Citation2015). While the US Department of Agriculture (USDA) Economic Research Service (ERS) estimates that 15 pathogens that cause the most deaths in the United States lead to $15.5 billion economic loss (Hoffman Citation2015), the World Bank estimates that in low- and middle-income countries the annual loss in productivity and medical expenses due to unsafe food is $95 billion (Jaffee et al. Citation2019). Importantly, limited advances are made in reducing foodborne illness rates based both on global data as well as data for specific countries. For example, Healthy People Citation2020 goals set in the US, were not met for a number of key foodborne pathogens. Most notably, Salmonella numbers in the US increased from 15.0 cases per 100,000 people per year in 2009 (Healthy People Citation2020) to 17.1 cases per 100,000 people per year in 2019 (Tack et al. Citation2020). This illustrates the need for novel and different approaches to assure food safety globally.
Table 1. List of abbreviations related to modeling and data privacy protection techniques.
The need for digital tools in modeling and Real-Time decision making, which hinges on the availability of data
As food safety increasingly uses digital tools, such as predictive models (Wang et al. Citation2022; Deng, Cao, and Horn Citation2021) and even digital twins of processing facilities or complete supply chains (Nasirahmadi and Hensel Citation2022; Tebaldi, Vignali, and Bottani Citation2021), it is becoming clear that access to real world data that are needed for model development and parameter estimates represents a major challenge. Collection of data to support or verify safety of food or food production environments can be expensive and resource intensive. It can involve extensive testing of raw materials, environments (e.g., irrigation water, processing plant), and finished products for different pathogens and/or indicator organisms (non-pathogens that provide insight into the hygienic quality of food production or processing environments). Once collected, these data are typically only used for quality and safety control within a food facility, with approaches ranging from visual examination of paper records to descriptive statistics and analysis of trends. However, the utility of such data could be much enhanced with digital tools, such as agent-based models (ABM) and machine learning (ML) algorithms, which are designed to improve food safety in a specific facility or multiple facilities.
Several existing studies have highlighted the importance of data availability and data sharing in food industry. Wang et al. (Citation2022) provided a detailed survey on how different types of data can be used for training ML models for a variety of tasks related to food safety. Data sharing across similar sources (e.g., comparable institutions in different areas/countries) can further enhance the performance of ML models. For example, Liu et al. (Citation2018) used data on mycotoxin deoxynivalenol (DON) concentration obtained from Italy to predict the probability of mycotoxin DON levels in wheat in Netherlands. In a similar vein, using additional data from complementary sources can help increase interpretability and usefulness of existing data. For example, Gardy et al. (Citation2011) showed how socio-environmental information can be combined with existing whole-genome sequencing (WGS) data to help determine sources and transmission pathways of infectious disease outbreaks. In the context of food fraud, Marvin et al. (Citation2016) demonstrated how identifying main drivers and collecting and using corresponding data in conjunction with reported food fraud cases can help predict future incidents. Despite the recognized benefit of higher data availability, data sharing is still limited in food industry, including for the reasons discussed in the section below.
Concerns for data sharing and model misuse
Many participants in the food system and in food safety may be reluctant to share data that may harm them because of liability, bad publicity or loss of business advantage relative to competitors. Industry groups, government agencies, as well as academia and research institutions are all potential data sources. However, concerns about data security, data privacy, and model misuse often limit their willingness to share data and provide data access. Thus, these concerns have emerged as a major bottleneck for further development of digital tools in food safety.
Data security, which describes the prevention of unauthorized access to data (e.g., cyberattacks), is one of main reasons that lead to mistrust in data sharing for companies. With more awareness of high-profile cyberattack cases (e.g., against the meat supplier JBS (Robbins Citation2021)), it is inevitable that food companies become more cautious about data handling. Although not the main topic of this review, technical solutions to data security are already available to mitigate enterprise risks. For example, blockchain provides some level of security to data as no single user can tamper with data without the consensus from all participating stakeholders (IBM Citation2022a). Other enterprise services are also available at the commercial level and can help identify the security vulnerability and prevent cyberthreats (IBM Citation2022b). Moreover, as data security also belongs within the realm of contractual agreement and regulatory purview, guidelines (CDC. Citation2019) and policies (Waithira, Mutinda, and Cheah Citation2019) have been proposed to standardize data collection, sharing and use for health-related data.
Different from data security (), data privacy focuses on the legitimacy of data handling and assurance of users’ rights to their shared data (Noyes Citation2016). However, without protective measures, the possibility of privacy breaches still exists even if the data collector is compliant with the regulations. For example, a researcher might collect data on foodborne pathogen detection in fields used to grow produce to develop Geographic Information System (GIS) models that could be used to predict field locations at an increased risk of pathogen presence. Upon publishing the model, the researcher shared the entire dataset while anonymized the identity of each individual farm according to the agreement with farmers. However, the privacy of pathogen data can still be breached if the locations of specific farms or fields are identified by matching weather data provided in the publication to a public database. In this case, the breached pathogen data will reveal the risk associated with specific farmland or food products, which could negatively influence the reputation and business of stakeholders.
Table 2. Data security vs. privacy: definitions, risks, and technical solutions.
In another scenario, assuming the pathogen data are not breached (i.e., privacy is guaranteed), a prediction model built on these data might still be used in a way that violates the intentions of the data provider. For example, outputs from developed GIS models in the last example could consequently be used to potentially discount the value of land that is predicted to be at an increased risk of pathogen simply due to a geographic location predicted to have a higher risk of pathogen presence. This would have a negative impact on the landowner that shared some of the data used for model development. Another hypothetical example of such misuse is that food safety related data can allow participants in the food system (e.g., retailers, processors) to make decisions as to which suppliers to use or potentially even which suppliers to negotiate with to agree on lower prices. For example, if a buyer gains access to model outcomes that show that one of their sellers had a sample collected from the environment of their facility test positive for a foodborne pathogen, they may elect to drop this supplier, even if the supplier took appropriate corrective actions. To define the limits of model utilization, government regulations and a priori business agreements are needed. As a general guideline for business agreements, we suggest that sensitive models could be held by a 3rd party that will run specific analyses, but that will require the individuals and organizations to (1) provide reasons for requesting analysis and (2) to justify the usage of model outputs, in order to avoid misuse. The government could also put in place more transparent regulations to promote the implementation of digital tools for food safety. For example, governmental agencies might provide licenses to approved models for internal use, similar to FDA-approved medical device and algorithms (Benjamens, Dhunnoo, and Meskó Citation2020). While strategies to minimize the potential of model misuse are important, they are beyond the scope of this paper. Instead, we will focus on technical solutions that improve data privacy.
While the notion of findable, accessible, interoperable, and reusable (FAIR) data sharing was mentioned in other fields (Reiser et al. Citation2018; Alvarez-Romero et al. Citation2022), we here suggest data privacy and protection should also be prioritized. This is becoming ever more important with the development of ML, artificial intelligence (AI) and similar models and technologies. While these models promise to create a smarter, autonomous world, including in terms of food safety, they have raised a number of concerns, of which data privacy is perhaps the most prevalent (Humerick Citation2018). Data privacy has been recognized as an essential requirement of a “trustworthy” AI, which has been defined as a framework to ensure that a model is worthy of being trusted based on the evidence concerning its stated requirements (ISO Citation2021). Another requirement of trustworthy AI is transparency or explainability, which refers to the need to explain, interpret, and reproduce its decisions by ensuring that stakeholders understand the AI system’s performance and limitations (Kaur et al. Citation2022). The requirement for privacy and explainability creates a tradeoff where higher level of explainability can make a model more vulnerable to attacks and therefore have a higher risk of privacy leakage (Budig, Herrmann, and Dietz Citation2021). Thus, novel data management and processing techniques need to be explored to ensure data privacy, and legal rules on data sharing need to be enforced to protect the rights of data providers, while also maintaining the explainability (as well as fairness, accountability, and acceptance) requirement of a trustworthy model.
Examples of tools that assure privacy protection in data sharing
Beyond the anonymization of data provider’s identity, techniques and tools protecting data privacy have seen limited use in food industry. In other sectors, however, there is rapid growth in the use of advanced solutions that protect data privacy and minimize the risk of data abuse. For example, in the public health domain where multiple data sources can provide information about individual patient, CDC began to explore the privacy-preserving record linkage (PPRL) to connect multiple datasets for a more comprehensive investigation of individual’s health status (Gilbert Citation2021). PPRL was shown to have similar results compared to standard linkage algorithm, but without compromising Personally Identifiable Information (PII) (Mirel Citation2021). PPRL can also allow the linkage to synthetic data to further mitigate the data leaking risk, as demonstrated in a case study (Resnick, Cox, and Mirel Citation2021). However, the linkage accuracy as well as validation of synthetic data need to be evaluated for applications to be feasible. In addition to the existing governmental approaches, other advanced data-preserving solutions proposed to be potentially applicable in public health are differential privacy (DP) and federated learning (FL). Differential privacy has already been used to allow releasing public health data for Coronavirus disease 2019 (COVID-19) surveillance without compromising the confidentiality of personal data (Dyda et al. Citation2021). Moreover, in a perspective paper (Rieke et al. Citation2020), federated learning was presented as a promising tool to allow the increased use of patient data in ML models for applications such as better diagnostic tools and accelerated drug discovery. These emerging applications in other fields can help with adoption of similar innovations in the food safety applications. Because most food safety model applications lack large, centralized datasets such as those available from healthcare providers for public health applications (e.g., National Hospital Care Survey (NHCS), National Death Index (NDI)), PPRL might be less relevant in the context of food safety than differential privacy and federated learning, which are more suitable for decentralized data that are more commonly collected by different stakeholders affiliated with the food industry.
Overview of data sharing needs and tools and article outline
In this paper, we will outline data needs for digital food safety applications and provide an overview of different modeling approaches and digital tools that play important roles in food safety, to more specifically illustrate data needs. Finally, we will describe existing approaches to assure data privacy and confidentiality to detail how these could be used in food safety in order to develop a system where data needed to develop digital food safety tools will become available and will be shared more easily. To make the concepts discussed here more accessible to a broad readership, we will illustrate them throughout this paper using practical examples from food safety models and summarize potential solutions at the end in a case study based a single hypothetical, yet realistic food system and supply chain (see and ). Briefly, this supply chain involves production and processing of fresh produce; this supply chain was selected due to the relevance of this system (as supported by a number of foodborne disease outbreaks traced back to fresh produce over the last decade (FDA Citation2020, Citation2021a, 2021b, 2021c) as well as the fact that the fresh produce supply chain does not include a singular step that would effectively eliminate, from raw materials, microbes that cause foodborne illness (a so-called “kill step”); in other supply chains (for example dairy), a heat treatment applied during processing (i.e., pasteurization) effectively reduces microbes that cause disease, which means that practices that reduce microbial contamination at the field level are less important. The hypothetical supply chain that we will use here includes (1) produce farms, each with multiple fields (which may also be called lots or ranches) where produce is grown; (2) produce processing facilities (where produce is delivered to and processed, e.g., into bagged salad mixes), and (3) retail chain stores where produce is delivered to and sold. We appreciate that this hypothetical system is simplistic and leaves out some components that are parts of the actual fresh produce supply chain, such as packing houses (where some fresh produce may be handled before it is delivered to a processing facility); this system however is comprehensive enough to illustrate the data needs and privacy issues that are encountered across all different supply chains.
Figure 1. A simplified sample system of fresh produce supply chain.
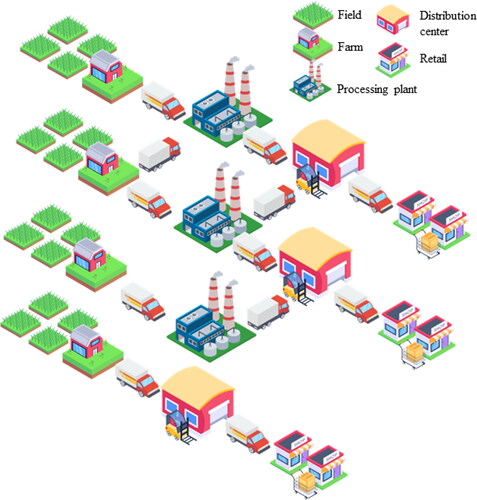
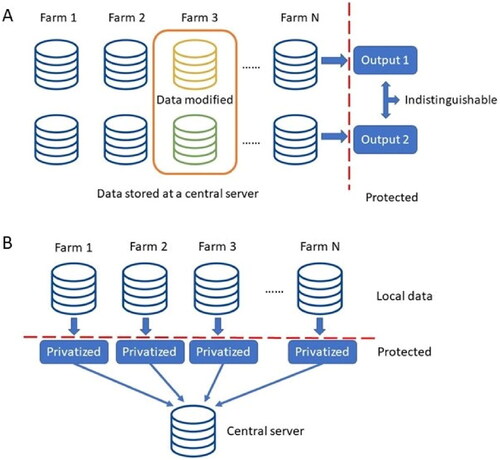
Figure 2. An illustration of (A) central differential privacy (CDP) and (B) local differential privacy (LDP). In CDP, each farm shares its own input data (e.g., soil quality, concentration of indicator microorganisms) to the central server. The data are stored at the central server and the model performance should be indistinguishable if the data from any single farm is modified. In LDP each individual farm does not share the original data, but instead share the privatized data that reveal little information about the farm.
Data needs in digital food safety systems
In response to the digital revolution in the food industry, FDA has called for “Smarter Food Safety” by acknowledging the need to incorporate modern tools in the current food safety system (Food and Drug Administration and (FDA)), Citation2018). Some digital modeling and analytical tools are already increasingly used to inform food safety decisions at both the firm as well as the system level, including growth modeling tools and quantitative risk assessment models. Novel analytics have also increasingly been developed for food safety applications (Deng, Cao, and Horn Citation2021), ranging from data-driven ML models for microbial DNA sequence annotation, to GIS -supported models to allow for prediction of field and environmental locations that have an increased risk of pathogen detection. In addition, simulation models developed based on the best understanding of causal principles and through synthesis of various data sources (e.g., ABMs) are also increasingly applied to food safety. While details of some of these model applications have already been summarized elsewhere (Lammerding Citation1997; Zoellner et al. Citation2019; Deng, Cao, and Horn Citation2021), below we will review 1) different data categories that are commonly used in food safety applications as well as 2) the data needs for different digital and modeling tools, emphasizing that potential benefits that can be gained from improved data sharing.
Data categories, utility and concerns for sharing
Microbial data
Description
Microbial data of interest to food safety model applications include data on pathogen prevalence, diversity, concentration, growth characteristics (including under different environmental conditions) as well as transmission coefficients, which describe the likelihood that pathogens can be transmitted from one surface (or location) to another. WGS data are another group of microbial data that can reveal the genetic fingerprint of a microorganism and thus be used for pathogen identification and characterization. This category of data is difficult and time-consuming to obtain due to the complex nature of biology. Compounding this challenge is that many of these data are needed for different conditions (e.g., temperature, humidity), locations, times (e.g., seasons), and matrices (e.g., different food types, different soil properties, etc.).
Utility
Because the presence of pathogens in food product and production environment is often the ultimate prediction outcome, improving our fundamental understanding of the pathogen can be extremely important to modeling the dynamics of pathogen. Consequently, data on pathogen presence and characteristics are often indispensable for model training and validation. Moreover, WGS data are extremely useful in outbreak investigation. Sharing WGS data can enhance models for outbreak source attribution and tracking.
Concerns for sharing
This category of data is also the primary privacy concern for stakeholders as it can reveal information on the (perceived) safety of product as well as the hygienic status of production environments, which can directly impact a company’s reputation.
Environmental data including risk factors
Descriptions
Environmental data broadly refer to the features in the food growing or production environments that could potentially have an impact on the presence of pathogens in the food product. In the case of a produce growing field, examples of these categories of data include but are not limited to soil quality attributes, agricultural water quality attributes, weather conditions and surrounding land use (see Weller et al. Citation2020a, Citation2020b for how these data may be used to predict food safety risks).
Utility
Environmental data can be important to help predict the likelihood of pathogen presence, as theses data provide information on 1) the ability of pathogens to grow or survive, 2) the likelihood and magnitude of pathogen die-off, and 3) the likelihood of pathogen introduction and transfer. Having these data at a higher granularity (i.e., collected at higher frequency) can potentially improve the accuracy of model predictions.
Concerns for sharing
While most environmental data are accessible through public databases, and thus are less of a concern for sharing and privacy, there are instances with higher privacy concerns. For example, agricultural water quality data may often predominantly reside in the private domain. In the case of a processing facility for produce, environmental data can include the wetness of surfaces and floor traffic patterns which could reveal a higher risk area for introducing potential contamination. While sharing of these categories of data per se is often only of limited concern, these data typically need to be linked to pathogen data (e.g., pathogen presence, pathogen levels) to be valuable for food safety applications, which substantially increases the concerns about data sharing.
Processing and management data
Descriptions
Processing and management data are specific to a processing facility. Examples of processing data could be the product processing records, sanitation frequency, etc. Examples of management data could be the employee movement, training records, and maintenance records.
Utility
While the benefit of sharing processing and management data of a single facility might be limited because they can be facility specific, comparison between facilities sharing similar characteristics may help discover specific risk factors for pathogen presence, growth, and transmission. Access to data collected across a large number of facilities can also be extremely valuable as these data could help define optimum levels of different food safety measures (e.g., sanitation frequency) based on environmental and facility conditions (e.g., moisture, age of facility, type of construction material).
Concerns for sharing
Processing and management data categories have medium to high privacy concerns as they can contain proprietary information such as processing procedures and processing volumes and as they may also reveal information that could be considered as indicating food safety risks (e.g., less frequent sanitation).
Supply chain data
Descriptions
Supply chain refers to the system network through which a food product travels from point of production (e.g., farm) to consumer. Relevant supply chain data could include data on the time and length of transport and storage as well as transport and storage conditions (e.g., temperature, humidity).
Utility
Sharing of supply chain data can be extremely valuable for different aspects of food safety, including traceback in the case of an outbreak, identification of high-risk suppliers and high-risk supply chain conditions (e.g., weather abnormalities) etc. These data could potentially help with development of a system-level risk assessment model that accounts for heterogeneous suppliers providing inputs with varying levels of food safety risks. Moreover, mapping the food distribution network was shown to be a useful tool that can aid in outbreak investigations (Norström et al. Citation2015).
Concerns for sharing
This data category is of high privacy concern because it reveals the company’s business details, such as supply volumes and collaborators, and thus would typically be considered proprietary information.
Consumer data
Description
Consumer data include 1) data actively generated by consumers such as social media post (Du and Guo Citation2022; Sadilek et al. Citation2017; Kuehn Citation2014), restaurant reviews (Effland et al. Citation2018; Harrison et al. 2014) and web search records (Sadilek et al. Citation2018), and 2) data passively collected from consumers such as locational data and transactional data. Some of these data (e.g., online reviews) are generated in high velocity and volume and can be mined from various web sources. Other data (e.g., transactional data, locational data) can be requested on an individual basis or from the platform for the investigation or research purposes.
Utility
As reviewed previously (Oldroyd, Morris, and Birkin Citation2018), studies have applied consumer data to monitor for foodborne illness signals to address the disadvantages of traditional approaches such as untimeliness and underreporting. In addition, a model utilizing Google search history and locational data has shown promise to facilitate restaurant inspections in Chicago (Sadilek et al. Citation2018). In another study, consumer purchase data were utilized in 20 outbreak investigation from 2006–17 to identify purchased items associated with illness cases at high odds ratios, hence aiding source tracking (Møller, Mølbak, and Ethelberg Citation2018).
Concerns for sharing
While most consumer data such as social media comments are publicly available, platforms still withhold identity and demographic information associated with these user data due to privacy concerns. Moreover, data sources such as web search history from Google and individual transactional data that can link the individuals to the purchase of contaminated product are protected the privacy agreements.
Data needs in modeling
Quantitative microbial risk assessment
Quantitative microbial risk assessment (QMRA) uses stochastic models for risk analysis and has been widely adopted as a decision support tool in the government (Bartram et al. Citation2015; Mcnab Citation1998). Through a structured process of hazard identification, exposure assessment, dose–response assessment, and risk characterization, QMRA is typically used to predict the likelihood of foodborne illness that results from consumption of contaminated products. Other possible applications for QMRA could be to predict the risk of recalls (for example under different testing scenarios) or to predict the likelihood of other enterprise risks (e.g., not meeting specific customer specifications) (Chen et al. Citation2022). One advantage of this model type is the capacity to test the effectiveness of different intervention strategies to minimize the risk. Uncertainty in predictions of QMRA reduces its usefulness and is inversely proportional to the data availability. Researchers usually use different categories of data obtained from a number of resources when developing a QMRA, including 1) microbial data, such as bacterial growth parameters, inactivation data, transmission coefficients, collected from literature (or calculated from primary data), as well as pathogen prevalence data collected by different sources; primary data can be obtained from farms or facilities that collect data by themselves, academic institutions or trade organizations that collaborated with farms and facilities, or government, which collected them as part of routine inspections or sampling assignments, 2) processing and management data (e.g., process flow diagrams representing industry standards or specific companies; sanitation frequency data), and 3) supply chain data (e.g., when developing a QMRA for a more complex supply chain system).
Improved data sharing and access to industry data could in many cases provide more accurate and reliable input data for QMRA, which can substantially reduce uncertainty and also help to separately assess uncertainty and variability of key parameters (e.g., by using Bayesian modeling approaches (Delignette-Muller et al. Citation2006)). Moreover, sharing data that were not previously incorporated in a risk assessment can address knowledge gaps identified in previously established models, and thus lead to more comprehensive and realistic models. With more resolution in the input data (e.g., microbial quantity in irrigation water at different seasons), it is also possible to use different sets of input data depending on various situations (e.g., different times of year), rather than using a set of aggregated input data with higher variability which also increases the variability of model outcomes.
In addition to, a priori, facilitating development of more accurate QMRA, enhanced data sharing would also provide for an improved ability to validate developed QMRAs and to assess their ability to accurately predict outcomes, including under different conditions; these data will also allow updates to model parameters as conditions change (e.g., as climate and predominant weather conditions change). Given the inconsistent occurrence of pathogens over time, acquiring these data regularly to maintain and re-calibrate models is important. Moreover, with more detailed historical data, error analysis can be performed to identify at which conditions a model will underperform, suggesting directions for further model adjustments or improvements.
Importantly, while QMRA is traditionally predominantly used by government agencies, enhanced sharing of industry data can have multiple benefits, including for the food industry. For one, data sharing can lead to improved models used by government agencies to set food safety policies, which provides an (indirect) benefit to industry by enhancing the likelihood that QMRAs suggest effective food safety practices. In addition, improved data sharing will help with development of more specific models (e.g., for certain types of processing facilities or specific industry sectors), which would be valuable for industry stakeholders as they perform their own risk assessments, including QMRAs that assess business risks (e.g., recall risks) rather than solely public health outcomes.
GIS models
The application of GIS to produce safety has shown (Polat, Topalcengiz, and Danyluk Citation2020; Weller et al. Citation2020a, Citation2020b) promise in predicting the probability of occurrence of foodborne pathogens in the environment as well as in identifying key factors that increase the likelihood of contamination. Using ML models with geo-referenced data (e.g., meteorological data, soil data), multiple studies reported promising results in predicting the pathogen presence in specific produce-growing areas (Polat, Topalcengiz, and Danyluk Citation2020; Weller et al. Citation2020a, Citation2020b).When developing a GIS model, researchers typically take advantage of multiple data sources including, 1) microbial data such as the concentration of indicator microorganisms and pathogens in the environments modeled (e.g., irrigation water, soil), 2) open-access environmental data updated and provided by public databases (e.g., geographical data associated with weather conditions, land use, geographical locations, 3) environmental data collected on private land with the permission from landowners (e.g., irrigation water turbidity and presence of indicator microorganisms, presence of pathogens). Despite the fact that GIS models use a substantial amount of publicly available data sources, the time-consuming and costly process of collecting field data on pathogen presence (i.e., the response variable) severely restricts the sample size for model training (typically <500 samples) and therefore limits model performance and generalizability. This drawback can be mitigated by encouraging data sharing.
Importantly, improved sharing of pathogen data could lead to the development of more accurate models. With higher data density in a given geographical region, models might reveal spatial autocorrelations, which would indicate hot spots of elevated risks that are not correlated with any geographical features currently used in a model. These spatial autocorrelations can help identify additional geographical features that might be responsible for an increased risk of pathogen presence. Moreover, since many geographical features have seasonal patterns (e.g., wind, temperature), collecting and sharing more data on pathogen presence (i.e., the response variable) more frequently can help assure developed models are consistently accurate throughout the year, rather than optimized toward a given time of year.
Apart from improving model accuracy, enhanced data sharing can also provide more historical data for re-calibration of models. Since some geographical features may be affected by climate change (e.g., global warming), periodical model re-calibration is needed to ensure accurate model predictions and prevent incorrect decision making.
Furthermore, enhanced data sharing could also broaden the applicability of models. Aggregating field pathogen data at the national level would facilitate identification of geographical patterns that lead to increased food safety risks on a large scale, and thus broaden model uses including to 1) identify additional local policy or management options that can be used to mitigate relative food safety risks in specific locations, 2) integrate data with other national geographical database to identify natural patterns that lead to increased risk (e.g., animal migration pathways), and 3) use information on specific locations to identify specific field locations that may represent increased or decreased food safety risks, which could be used for land selection. Many of these applications would facilitate development of location and time specific “precision food safety” approaches (Kovac et al. Citation2017), which will represent a substantial advancement over the current predominant “one size fits all” food safety approaches.
Agent-Based models
An agent-based model (ABM) is a type of rule-based model that simulates the operation of a complex system through simulation of autonomous components (i.e., agents) over a given time. Depending on its heterogeneous characteristics, each agent in the system is defined with a set of behaviors through which it interacts with other agents or the environment (Wilensky and Rand, Citation2015). In food safety, ABMs have been used for modeling pathogen transmission in food processing facilities; the outcomes from model simulations can be used to inform management decisions, such as whether to implement specific intervention strategies or change sampling plans (Zoellner et al. Citation2019; Sullivan et al. Citation2021; Barnett-Neefs et al. Citation2022).
The specific data needs for ABMs can vary depending on the sophistication of the simulation (e.g., an ABM may involve spatial co-ordinates and exact spatial relationships of modeled agents and the environment), and its purpose (e.g., to predict contamination in the environment, finished food product or both). Typical data needs for development and validation of food safety related ABMs may include (1) pathogen data, (2) environment data, and (3) process and management data (e.g., agent behaviors, such as movement patterns for employee in a facility). Pathogen data needed for ABMs not only include pathogen characteristics (e.g., growth rate, optimum growth temperature (Hoelzer et al. Citation2012), carrying capacity for different environments), but also data related to pathogen-environment interactions. Examples of these categories of data include (1) prevalence and loads in different sources that can introduce pathogens into the modeled environment (e.g., Zoellner et al. Citation2019); (2) transfer coefficients and probabilities (e.g., Hoelzer et al. Citation2012); and (3) pathogen reduction rates associated with different routine processes such as cleaning and sanitation (Hoelzer et al. Citation2012; Gallagher et al. Citation2013).
While data on the environment for which a model is developed are essential for ABMs, one could argue that minimal privacy concerns arise if facility specific ABMs are developed. Sharing and publication of ABMs (e.g., in the peer-reviewed literature) may however raise substantial concerns if blueprint data for a facility (Zoellner et al. Citation2019), specifications such as room dimensions, or daily operation data (e.g., shift length) are shared. Similar data sharing and privacy concerns also apply to agent data, which can include specific data on facility lay-out and use (including the number of employees) (Zoellner et al. Citation2019), which often may be considered competitive or proprietary.
While ABMs are often specific to a given facility, which could imply limited need for data sharing, many of the parameters used in ABMs are, however, applicable and needed across different ABMs. Improved data sharing could substantially improve the available parameter estimates (e.g., for transfer coefficients) and hence reduce the entry barrier to developing food safety related ABMs. Through statistical learning, the model parameters can be optimized to improve the accuracy of model predictions. In addition, while ABMs typically are facility-specific and designed to be run independently of each other, the data they produce may be used to establish a larger dataset for further analysis, allowing for the detection of common patterns or determination of overall effectiveness of specific strategies. Enhanced data sharing could also help with development of more generic ABMs (such as a “generic produce packing plant”) that can be used for plant design that minimize possible pathways for pathogen transmission and to develop plant specific ABMs more rapidly.
Public health models
Another promising area of digitalization is foodborne disease monitoring and investigation; specific ML applications in this area have been extensively reviewed by (Deng, Cao, and Horn Citation2021), and their functions typically include surveillance and source tracking and attribution of foodborne outbreaks. Traditionally, these models often utilize microbial data sources such as WGS data from clinical isolates and food samples, in addition to associated metadata such as the product type and geographical location. Novel data streams such as consumer data (e.g., social media posts) are also getting more utilization in outbreak investigation and detection as shown by a number of publications (Effland et al. Citation2018; Harrison et al. 2014; Du and Guo Citation2022; Sadilek et al. Citation2017; Sadilek et al. Citation2018; Kuehn Citation2014).
Improved data sharing in genomic data is already occurring, over at least the past decade, with the appearance of databases such as Pathogen Detection database hosted by National Center for Biotechnology Information (NCBI). Data sharing in this area should be focused on more standardized and comprehensive metadata, which provide background data for isolates that can substantially improve data utility, e.g., for modeling and source tracking. Moreover, continuous sharing the WGS data can also provide more training data that can potentially increase the accuracy of source attribution models for foodborne pathogens.
While most consumer data are publicly available, some still remain under protection by different social platforms and might be open to sharing if privacy can be guaranteed by technical solutions. Improving sharing in this data space might need to focus on 1) more data varieties (e.g., e-commerce trade data), 2) spatial and temporal resolution/dimension, and 3) less bias in data collection. Collaborations with various service providers can be one approach to broaden data varieties. For example, with increasing popularity of e-commerce, consumer purchasing history through platforms such as Instacart or Amazon Fresh could be valuable to provide consumption histories of case patients and to identify possible outbreak sources. Also, while the consumer data are generated every day, the speed of data collection and utilization might be limited. With higher spatial and temporal resolution, consumer data could help identify unusual patterns, such as increased risks associated with extreme weather conditions or holiday seasons. More extended dimensions of consumer data, for example collecting data at national level, can help reveal spatial patterns that might link to multi-state distribution network of contaminated food products. Lastly, despite the potential utility of consumer data, there have been a debate about inherent bias of social media data toward populations that more frequently use digital devices (Santos and Matos Citation2013; Culotta Citation2010; Achrekar et al. Citation2012), a drawback that if true could implicitly foster demographic and socioeconomic inequality in outbreak surveillance. This is particularly relevant as elderly population is more susceptible to foodborne illness. While there is no clear consensus on this contention, providing demographic composition for consumer data might be needed during data sharing to provide the context of data.
Technical approaches for preserving data privacy
Privacy-Preserving data processing
Differential privacy
Recent years have witnessed tremendous progress in digital technologies and AI tools, including notable ML applications in computer vision, recommendation systems, speech, and language technologies, among others. Successful applications of these technologies are typically built on large amounts of data that often have been collected from users (e.g., medical data from individuals). Naturally, this has raised questions of privacy, as the data collected from users inevitably contain sensitive information. Consequently, over the decades several approaches have been proposed for providing privacy guarantees to individuals. One natural approach is data anonymization, where personal information is deleted from the data before releasing. However, anonymization does not guarantee privacy as was evident in several publicized events. Sweeney (Citation2002) did re-identification attacks on the publicly released medical data of patients in Massachusetts and was able to successfully identify the medical record of Governor William Weld. In another instance, Narayanan and Shmatikov (Citation2008) were able to identify individual users from anonymized Netflix ratings data by cross-referencing them with IMDB profiles. Since simple anonymization of data does not guarantee privacy, stronger privacy notions are needed. Differential privacy, proposed by (Dwork et al. Citation2006) is now considered as the gold-standard of privacy and has been adopted across industry and governmental agencies, such as the US Census Bureau. Differential privacy provides a framework for guaranteeing privacy. In differential privacy, noise is added to the data or the output of the algorithms to obfuscate the true data. The first instance of differential privacy was from Warner (Citation1965) for surveys. The high-level idea of a differentially private algorithm is that the algorithm’s output should not allow one to decipher a particular user’s input. As a hypothetical example, if one would want to obtain data from a survey about drug usage among high schoolers, instead of getting and releasing true data, differential privacy would flip the answer of each individual with some probability before releasing the aggregate data. Naturally, the more noise that is added, the better is the privacy guarantee. But at the same time, the data are less useful. We posit that application of these concepts and tools to food safety can substantially enhance data sharing by reducing privacy concerns that are often cited by the food industry as a barrier to data sharing. For example, industry may be more willing to share pathogen data if they know that appropriate technologies are used to assure that pathogen prevalence in their facility (or location of specific pathogen positive sites) cannot be deduced by regulatory agencies or others that may use a model where model development included the shared data. Differential privacy grants the data providers with the plausible deniability in the face of potential accusations as the data observer cannot guarantee that the data is real instead of synthetic (e.g., with added noise for numeric data and flipped for binary data) (Bindschaedler, Shokri, and Gunter Citation2016).
The following sections will discuss commonly adopted notions of differential privacy, their strengths, limitations, as well as their possible applications to food safety.
Central differential privacy
This is the classical notion of differential privacy. In this setting, all the data collected are stored at a central trusted server. The server can only run algorithms on data that are differentially private (i.e., the output of the algorithms does not reveal much information about the true user data). Formally, let D be a dataset consisting of data from n users (e.g., 1,000 farms). Let D be any dataset that can be obtained from D by adding, removing, or modifying exactly one user’s data (e.g., adding noise to one farm’s temperature data). A randomized algorithm A (ε, δ) is called differentially private if for any set of the possible outputs of
.
Here,
and
are the parameters that control the level of privacy: the smaller these parameters are, the stronger the privacy guarantee. For example, when
, the output of the algorithm should be independent of the input, thus providing perfect privacy (and no useful information)
. Another interpretation of this definition is that if all-but-one user’s raw data are leaked to some adversary, the adversary still cannot infer the data of that user from the output of the algorithm. Privacy guarantees naturally come with a price: the performance of model built with privatized data worsens if we increase the level of privacy. As a concrete example, suppose certain food safety models will need to use the average pathogen frequency and levels across products (e.g., leafy greens) harvested from farms as inputs or parameters (e.g., in a GIS model to describe the likelihood of pathogen introduction with raw materials), to ensure privacy, it suffices to add Laplace or Gaussian noise of suitable magnitude to the average pathogen frequency. While a higher noise magnitude provides a stronger privacy guarantee, it is important to note that for successful implementation of differential privacy, the changes made to the primary data to assure privacy should not affect the performance of the final model built.
Local differential privacy
While central differential privacy requires a central trusted server, local differential privacy (LDP) addresses this problem when users do not want to trust a third party with their data (Kasiviswanathan et al. Citation2011) (See ). Each user first privatizes their own data locally, and then fully releases the privatized data. In our context, consider sensitive Yes/No data (e.g., did a food processing facility have a pathogen positive sample in a given week), which a model developed wants to use to compute the ratio of facilities that did. The facilities may not want to reveal their true answer. However, they may be willing to flip their responses with probability 0.4 (or any other number strictly less than 0.5) and output this potentially wrong answer. The data collector cannot infer the true data of any of the facilities from their responses. However, we can still learn the ratio of Yes, except with lower accuracy compared to the non-private case where we do not flip the answers. If we increase the flip probability, we can guarantee stronger privacy since it becomes harder to guess the true response. In other words, there is a natural tradeoff between the level of privacy and accurate inference we can make from the data. Formally, let X denote the true user data and Y be the released data. A data release mechanism is ε-locally differentially private if for any pair of inputs ,
, the probability of sending any message
should be close. This idea of randomized response was proposed by Warner (Citation1965) as a possible way to collect responses in surveys on sensitive questions.
Local differential privacy provides a stronger privacy guarantee than central differential privacy
, but this also comes at a drop in the performance of learning algorithms (Duchi, Jordan, and Wainwright Citation2013; Acharya, Sun, and Zhang Citation2020). Therefore, successful real-world applications of local differential privacy require a huge amount of data (for example, data from billions of users, which are available to large companies like Apple and Google). Practices in large scale deployment of local differential privacy were illustrated in a survey by Cormode et al. (Citation2018) While application of local differential privacy to food safety may currently be limited, one can imagine that enhanced food safety data acquisition (e.g., with real time sensors) and increased utilization of consumer data (e.g., social media comments) could lead to datasets where local differential privacy would be appropriate for ensuring data privacy.
Other differential privacy models
Apart from central differential privacy and local differential privacy, there are different notions of differential privacy. Examples include the shuffle model (Cheu et al. Citation2019) and the pan-private model (Dwork et al. Citation2010). In some sense, these models fall in between central and local differential privacy in terms of the level of trust for the data collector and algorithm performance. For example, with the shuffle model, an intermediate shuffler collects the data from multiple farms and process the data via permutation before sending them out to a centralized database (e.g., governmental agency) for model development. Thus, the privacy of each individual farm can be guaranteed.
Relaxations of differential privacy
While differential privacy provides a rigorous mathematical definition for privacy, the restriction can be too strong for some complicated learning tasks such as training neural networks for image classification. Therefore, some relaxations of differential privacy have been proposed, as mentioned by Ghazi et al. (Citation2021) and Huang et al. (Citation2017). These relaxation techniques can potentially allow users to adjust the level of noise depending on the confidentiality of data categories (e.g., pathogen data has more privacy concerns than indicator microorganism data) and the trust level of whom they send data to (e.g., research organizations who could publish the data vs. third-party companies who keep data internal).
Label privacy
In certain cases, only part of the data may contain sensitive information (Ghazi et al. Citation2021). For example, in an image classification task where each user has an image and a label (e.g., the presence of an animal in a produce field) associated with the image, label privacy considers the case when only the label is sensitive and should be protected. The model can be significantly more accurate than the traditional setup where both the image and label are considered private. These types of privacy models are expected to become increasingly important as image and video data are used in food safety (such as video surveillance of sanitation tasks to verify that sanitation was properly executed). For current use of ML models in food safety, label privacy can be potentially applied to farm-level prediction of pathogen presence. In this case, the label (i.e., pathogen presence in a specific geographical location) should be privatized while the data such as sample collection date, soil property, temperature are publicly available and thus not confidential.
Augmentation with non-private dataset
As discussed before, privacy protection of data from users or facilities usually leads to loss in model performance. For some tasks, it may be possible to (partially) compensate for this by obtaining and using datasets that do not contain sensitive information (for example, national data repositories with publicly available dataset). Learning with these non-private datasets in addition to private data from facilities may significantly improve model performance. This can have substantial applications in food safety, where government agencies (e.g., USDA-FSIS, US FDA, etc.) may have substantial datasets on pathogen prevalence that can be augmented with even larger data sets collected by industry for the same commodities.
Data sharing without sharing the data: Federated learning
The federated learning framework
Federated learning is a ML framework where stakeholders learn collectively (e.g., through a ML model) by leveraging scattered and privately-owned datasets without sharing the raw data (Brendan McMahan et al. Citation2017). The defining feature of federated learning is that each client performs local learning using its own dataset and shares with the central learner only the information for model updates. Consider the example of learning a GIS model for pathogen detection by leveraging data from multiple farms. A central server facilitates the collective learning in an iterative process (see ). In each iteration of the training process, the central server broadcasts the current set of model parameters to the farms. Each farm updates the parameters locally with its own data and sends the updated parameters back to the central server. The locally held data never leaves the farm, and only information relevant for model updates is sent to the central server. The central server aggregates the updates from the farms, updates the global model, and proceeds to the next iteration.
Figure 3. An illustration of the privatized federated Learning framework. Each client maintains its own local data. The clients use the local data to perform local updates which are then sent to the central server in a privatized/encrypted manner. The central server aggregates the local updates from the clients to obtain a new global model which is shared with the clients for the next iteration.
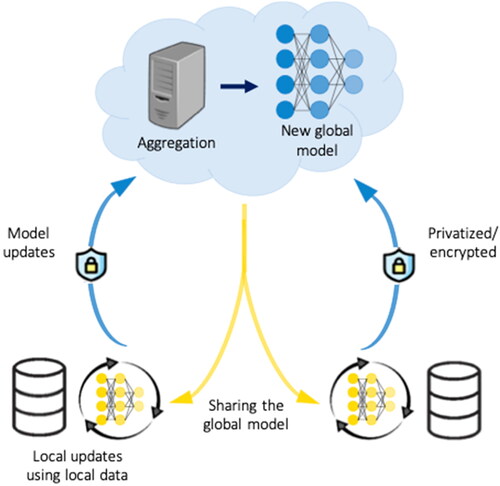
Privatized federated learning
Federated learning preserves a certain level of data privacy and security at each stakeholder by avoiding direct sharing of the raw data. It is, however, possible that through reverse engineering, certain statistics of the data can be revealed from the shared model update information. An enhanced level of privacy guarantee can be achieved by privatizing the shared model update information using differential privacy techniques. For example, the farms and the central server can share local updates and model parameters, respectively, in a differentially private manner (Wei et al. Citation2020).
Open challenges in federated learning in food safety systems
One key technical challenge in federated learning is how to handle statistically heterogeneous clients. This challenge is particularly relevant to food safety systems. In the example of learning a GIS model for pathogen detection, the participating farms in the federated learning framework are likely to have different underlying probabilistic models for their microbial, physicochemical, and environmental attributes. To train a global model that offers better performance over locally learned models for all clients, one approach is to incorporate context information of each participating client in the aggregation at the central server for training the global model. Another approach is through local fine tuning of the global model to arrive at a personalized model for each client.
Potential solutions for privacy-preserving data sharing
This section outlines potential solutions and approaches for privacy-preserving data sharing in food safety. For illustration, consider a scenario where we wish to collect pathogen data in fields and irrigation water from 2000 farms to build a GIS model that predicts times and locations of increased pathogen risk. We briefly describe how and when the strategies outlined in the previous section can be used to build a model with good predictive accuracy while simultaneously ensuring data privacy for participating parties.
Building a model with good predictive accuracy may help farms to take preventive measures against potential pathogen risks and collecting data from more farms can help us build a more accurate model. However, pathogen data are sensitive, and they may damage the farm’s reputation if such data are leaked and may put the farm at a disadvantage compared to a farm that may in reality have the same or higher risk of pathogen contamination but that does not participate in data sharing or does not even collect the pathogen data. Federated learning provides the right framework to address the tradeoff between learning and privacy in this scenario. It allows one to build a model with good predictive accuracy by encouraging and facilitating contributions from all the farms while simultaneously allowing each farm to keep pathogen data private. By using this in conjugation with central differential privacy, we can further ensure privacy for the farms. Such a model, even when made public, would make inferring exact information about any individual farms or their participation in data sharing and model training impossible. Each farm may have many pathogen data and may wish that little information is leaked for any of them. To address this concern, we can apply central differential privacy. In addition, GIS coordinates of farms could be obscured by shifting or other spatial distortion to protect the privacy of participating farms (see for illustrations).
Figure 4. An illustration of various data modification strategies for pathogen data, location data, and land use data collected on multiple farms, depending on the data categories and privacy sensitivity. In this example, the presence of pathogen is flipped with a certain probability to grant the data provider plausible deniability. The GPS locational data can be privatized by adding with a random noise (using local or central differential privacy approaches). The land use data is public, and thus needs no privatization.
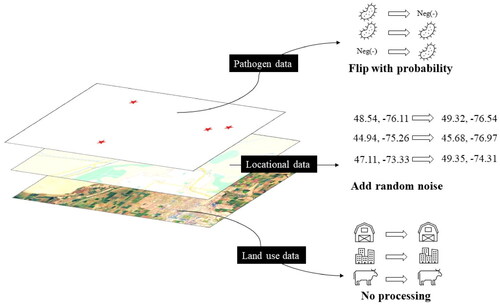
We may also want to collect and use data for indicators for pathogen contamination risk (e.g., coliform detection) to help build our GIS model. These data are not as sensitive as raw pathogen data. For these kinds of data, we may not need to use federated learning and simply let each farm send the original data. We may still want to apply central differential privacy as the data still contain some sensitive information about the farms.
For GIS soil data, the data can be acquired through public data repositories (e.g., USGS), but it may be sensitive if the soil data are linked to pathogen data through GIS coordinates. Using a combination of federated learning and central differential privacy for the soil data as in the case of pathogen data would allow us to prevent any misuse of data in such a scenario. In addition, we can use publicly available data (which is naturally non-private) to help us build a much better model.
We may also want to learn from high-dimensional data such as video surveillance data with labels and annotations. While it is always possible to apply differential privacy, the complexity of the learning problem can be prohibitive to achieve a good learning performance under differential privacy. In this case, we may consider label differential privacy, where only the labels or annotations are considered private.
Next, we discuss some examples for food safety applications at the processor, retail, and system level. Here, ABMs can be used to simulate safety risks in certain areas. To build these models, we need to collect data from facilities to learn the necessary parameters such as transmission rate. We can apply central differential privacy when learning these parameters. In addition, ML models such as support-vector machine (SVM), linear regression, and neural networks can also be used as learning algorithms. There is abundant literature (Chaudhuri, Monteleoni, and Sarwate Citation2011; Abadi et al. Citation2016) in the ML community on how to privatize these ML models.
For all the scenarios in this section, we can replace the differential privacy solutions with local differential privacy to provide the most stringent privacy guarantee. However, this would come at the cost of significant loss in model accuracy. To compensate for this, models would need large sets of training data. For example, to use local differential privacy while maintaining acceptable accuracy, we would need to obtain data from a large number of farms or facilities (typically a total of > 100,000 observations is needed), which may be unrealistic in many cases where data are only available from 100 s of farms and where such a large number of processing facilities do not exist. However, for some parts of the food system (e.g., retail establishments, dairy farms) appropriable large numbers of facilities may be available (e.g., in 2020 there were about 31,000 dairy farms in the US (Nepveux Citation2021)).
In summary, above we provide a discussion of potential privacy solutions for food safety applications, focusing on farm level examples, but also providing some illustrations relevant to processors and retail as well as system levels; more examples for how privacy could be assured for different food safety relevant data can be found in . We emphasize that our discussion is by no means conclusive, and the most suitable choice for an actual real-world problem can be different from our proposed solutions. To determine the privacy-preserving technology that should be used, one needs to make a comprehensive assessment of the amount of available data, the desired learning performance, complexity of the learning problem, and the desired level of privacy protection, and find a solution that best balances these concerns.
Table 3. Examples of food safety data available for various compartments of a simplified food system, including possible data uses and privacy concerns.
Discussion and conclusion
The objective of this review is to describe data needs for digital food safety and discuss how existing differential data privacy algorithms could enable them. The fact that these algorithms already exist and have been used in other industries is reassuring. However, a number of challenges still exist that need to be addressed to enable “Smarter Food Safety”. Here we will briefly discuss four such challenges.
An important challenge is fragmentation of the food supply chain in terms of limited scope of the existing digital tools to a single segment of the food supply chain (such as pre-harvest produce production or food processing). A reason for this fragmentation is the structural complexity of the food production system with many entities and stakeholders involved in the production, distribution, and consumption of food. Addressing this challenge requires vertical integration of digital food safety tools across the supply chain, so that tools communicate to each other in an effort to enhance the utility of any individual tool.
The current fragmentation of the existing digital tools is further complicated by the different data needs and related to the different privacy guarantees required for data sharing along the supply chain, e.g., due to fears of data abuse, bad publicity, liability, and the need to keep certain data (e.g., human illness data) confidential. Addressing this challenge will require identification of 1) the category of data that needs to be shared, i.e., what is most cost effective strategy for the end goal of reduced food safety risk at the food consumption; 2) at what level of resolution and privacy guarantee that data needs to be shared; and 3) data privacy and utility tradeoffs within the privatized federated learning framework, such as the tradeoff between accuracy of predicting food safety risk and the privacy guarantee in each step of the supply chain.
While effective food safety requires close coordination among all actors in the supply chain, neither the costs nor the reputational and legal consequences of food safety incidents are borne equally by all supply chain actors. Therefore, despite the seemingly obvious public health improvements afforded by data sharing in food safety, these differences in the data resolution and privacy concerns hinder both the development of Smarter Food Safety systems and learning from the privacy preserving/federated algorithms. Thus, there is a need for research on how to incentivize data sharing and how to manage tradeoffs between data privacy and utility across multiple actors in the supply chain.
Modern food systems across the supply chain will require development of new and improved 1) domain knowledge about components and processes relevant to the whole food supply chain and 2) skills to work with data, models, analytics and systems that permeate this industry. Thus, a concerted effort is needed to develop educational opportunities that address both of those needs for audiences at different stages of education and professional development, from K-12, undergraduate and graduate programs, continuing education, and outreach for members of the food industry)
Addressing these challenges requires interdisciplinary collaborations to bring together experts in food safety, data science, law, governmental regulations and economics.
Disclosure statement
The authors report there are no competing interests to declare.
Additional information
Funding
References
- Abadi, M., H. B. McMahan, A. Chu, I. Mironov, L. Zhang, I. Goodfellow, and K. Talwar. 2016. Deep learning with differential privacy. In Proceedings of the ACM Conference on Computer and Communications Security, 24–8. Association for Computing Machinery.
- Acharya, J., Z. Sun, and H. Zhang. 2020. Hadamard response: Estimating distributions privately, efficiently, and with little communication. In AISTATS 2019 - 22nd International Conference on Artificial Intelligence and Statistics, 1120–9.
- Achrekar, H., A. Gandhe, R. Lazarus, S. H. Yu, and B. Liu. 2012. Twitter improves seasonal influenza prediction. HEALTHINF 2012 - Proceedings of the International Conference on Health Informatics: 61–70. https://www.scitepress.org/Papers/2012/37806/37806.pdf.
- Alvarez-Romero, C., A. Martínez-García, A. A. Sinaci, M. Gencturk, E. Méndez, T. Hernández-Pérez, R. Liperoti, C. Angioletti, M. Löbe, N. Ganapathy, et al. 2022. FAIR4Health: Findable, accessible, interoperable and reusable data to foster health research. Open Research Europe 2:34. doi: 10.12688/openreseurope.14349.2.
- Barnett-Neefs, C., G. Sullivan, C. Zoellner, M. Wiedmann, and R. Ivanek. 2022. Using agent-based modeling to compare corrective actions for listeria contamination in produce packinghouses. Ed. Míriam R. García. PLoS ONE 17 (3):e0265251. doi: 10.1371/journal.pone.0265251.
- Bartram, J., R. Baum, P. A. Coclanis, D. M. Gute, D. Kay, S. McFadyen, K. Pond, W. Robertson, and M. J. Rouse. 2015. Routledge handbook of water and health. Abingdon, UK: Routledge.
- Benjamens, S., P. Dhunnoo, and B. Meskó. 2020. The state of artificial intelligence-based FDA-approved medical devices and algorithms: An online database. Npj Digital Medicine 3 (1):1–8. https://www.nature.com/articles/s41746-020-00324-0. doi: 10.1038/s41746-020-00324-0.
- Bindschaedler, V., R. Shokri, and C. A. Gunter. 2016. Plausible deniability for privacy-preserving data synthesis. Proceedings of the VLDB Endowment 10(5): 481–92.
- Brendan McMahan, H., E. Moore, D. Ramage, S. Hampson, and B. Agüera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, AISTATS 2017, 1273–84.
- Budig, T., S. Herrmann, and A. Dietz. 2021. Trade-offs between privacy-preserving and explainable machine learning in healthcare. Cii Student Papers 59. https://tobias-budig.com/docs/AIFB_Seminararbeit-10.pdf.
- CDC. 2019. Standards to facilitate data sharing and use of surveillance data for public health action. https://www.cdc.gov/nchhstp/programintegration/sc-standards.htm%0Ahttps://www.cdc.gov/nchhstp/programintegration/sc-standards.htm#DATA.
- Chaudhuri, K., C. Monteleoni, and A. D. Sarwate. 2011. Differentially private empirical risk minimization. Journal of Machine Learning Research: JMLR 12 (3):1069–109.
- Chen, R., R. H. Orsi, V. Guariglia-Oropeza, and M. Wiedmann. 2022. Manuscript type: Research paper development of a modeling tool to assess and reduce regulatory and recall risks for cold-smoked salmon due to listeria monocytogenes contamination. Journal of Food Protection https://pubmed.ncbi.nlm.nih.gov/35723598/. Advance online publication. doi: 10.4315/JFP-22-025.
- Cheu, A., A. Smith, J. Ullman, D. Zeber, and M. Zhilyaev. 2019. Distributed differential privacy via shuffling. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 375–403. Cham, Switzerland: Springer.
- Cormode, G., S. Jha, T. Kulkarni, N. Li, D. Srivastava, and T. Wang. 2018. Privacy at scale: Local differential privacy in practice. In Proceedings of the ACM SIGMOD International Conference on Management of Data, 1655–8. ACM. doi: 10.1145/3183713.3197390.
- Culotta, A. 2010. Towards detecting influenza epidemics by analyzing Twitter messages. SOMA 2010 - Proceedings of the 1st Workshop on Social Media Analytics, 115–22. http://mallet.cs.umass.edu. doi: 10.1145/1964858.1964874.
- Delignette-Muller, M. L., M. Cornu, R. Pouillot, and J. B. Denis. 2006. Use of Bayesian modelling in risk assessment: Application to growth of listeria monocytogenes and food flora in cold-smoked salmon. International Journal of Food Microbiology 106 (2):195–208.
- Deng, X., S. Cao, and A. L. Horn. 2021. Emerging applications of machine learning in food safety. Annual Review of Food Science and Technology 12:513–38. doi: 10.1146/annurev-food-071720-024112.
- Du, Y, and Y. Guo. 2022. Machine learning techniques and research framework in foodborne disease surveillance system. Food Control. 131:108448. https://www.sciencedirect.com/science/article/pii/S0956713521005867?casa_token=kh3mUpuGOvsAAAAA:LO9ea6IfQVXvbZ-oelnxqlkg-ZaF28b1E-3p9_nUMdodlFETqAgsFQig4DP6t4inp8JwbOKO. doi: 10.1016/j.foodcont.2021.108448.
- Duchi, J. C., M. I. Jordan, and M. J. Wainwright. 2013. Local privacy and statistical minimax rates. Proceedings - Annual IEEE Symposium on Foundations of Computer Science, FOCS, 429–38.
- Dwork, C., F. McSherry, K. Nissim, and A. Smith. 2006. Calibrating noise to sensitivity in private data analysis. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 265–84. Cham, Switzerland: Springer.
- Dwork, C., M. Naor, T. Pitassi, G. N. Rothblum, and S. Yekhanin. 2010. Pan-private streaming algorithms. In Proceedings of the First Symposium on Innovations in Computer Science (ICS 2010), 1–32. http://research.microsoft.com/apps/pubs/default.aspx?id=118234.
- Dyda, A., M. Purcell, S. Curtis, E. Field, P. Pillai, K. Ricardo, H. Weng, J. C. Moore, M. Hewett, G. Williams, et al. 2021. Differential privacy for public health data: An Innovative tool to optimize information sharing while protecting data confidentiality. Patterns (New York, N.Y.) 2 (12):100366. doi: 10.1016/j.patter.2021.100366.
- Effland, T., A. Lawson, S. Balter, K. Devinney, V. Reddy, H. Waechter, L. Gravano, and D. Hsu. 2018. Discovering foodborne illness in online restaurant reviews. Journal of the American Medical Informatics Association: JAMIA 25 (12):1586–92. https://academic.oup.com/jamia/article-abstract/25/12/1586/4725036.
- FDA. 2020. Outbreak investigation of E. Coli - Leafy greens. https://www.fda.gov/food/outbreaks-foodborne-illness/outbreak-investigation-e-coli-leafy-greens-december-2020.
- FDA. 2021a. Outbreak investigation of E. Coli O157:H7 - Spinach. https://www.fda.gov/food/outbreaks-foodborne-illness/outbreak-investigation-e-coli-o157h7-spinach-november-2021.
- FDA. 2021b. Outbreak investigation of listeria monocytogenes: Fresh express packaged salad. https://www.fda.gov/food/outbreaks-foodborne-illness/outbreak-investigation-listeria-monocytogenes-fresh-express-packaged-salad-december-2021.
- Food and Drug Administration, (FDA). 2018. New era of smarter. https://www.fda.gov/food/new-era-smarter-food-safety.
- Gallagher, D., R. Pouillot, S. Dennis, and J. Kause. 2013. Draft - Interagency listeria monocytogenes in retail delicatessens risk assessment. https://www.fda.gov/media/87042/download.
- Gardy, J. L., J. C. Johnston, S. J. Ho Sui, V. J. Cook, L. Shah, E. Brodkin, S. Rempel, R. Moore, Y. Zhao, R. Holt, et al. 2011. Whole-genome sequencing and social-network analysis of a tuberculosis outbreak. The New England Journal of Medicine 364 (8):730–9. https://pubmed.ncbi.nlm.nih.gov/21345102/. doi: 10.1056/NEJMoa1003176.
- Ghazi, B., N. Golowich, R. Kumar, P. Manurangsi, and C. Zhang. 2021. Deep learning with label differential privacy. Advances in neural information processing systems 34. http://arxiv.org/abs/2102.06062.
- Gilbert, J. 2021. CDC to award contract for privacy-preserving record linkage (PPRL) of patient-level real world healthcare data to advance COVID-19 response and other CDC Priorities - FedHealthIT. https://www.fedhealthit.com/2021/07/cdc-to-award-contract-for-privacy-preserving-record-linkage-pprl-of-patient-level-real-world-healthcare-data-to-advance-covid-19-response-and-other-cdc-priorities/.
- Harrison, C., M. Jorder, H. Stern, F. Stavinsky, V. Reddy, H. Hanson, H. Waechter, L. Lowe, L. Gravano, S. Balter, Centers for Disease Control and Prevention (CDC), et al. 2014. Using online reviews by restaurant patrons to identify unreported cases of foodborne illness - New York City, 2012-2013. MMWR. Morbidity and Mortality Weekly Report 63 (20):441–5. http://www.ncbi.nlm.nih.gov/pubmed/24848215%0Ahttp://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=PMC4584915.
- Healthy People. 2020. Healthy people 2020 objectives and topics: Food safety. https://www.healthypeople.gov/2020/topics-objectives/topic/food-safety/objectives.
- Hoelzer, K., R. Pouillot, D. Gallagher, M. B. Silverman, J. Kause, and S. Dennis. 2012. Estimation of listeria monocytogenes transfer coefficients and efficacy of bacterial removal through cleaning and sanitation. International Journal of Food Microbiology 157 (2):267–77.
- Hoffman, S. 2015. Quantifying the impacts of foodborne illnesses. USDA economic research service. http://ageconsearch.umn.edu/bitstream/209414/2/. 10.22004/ag.econ.209414.
- Huang, C., P. Kairouz, X. Chen, L. Sankar, and R. Rajagopal. 2017. Context-aware generative adversarial privacy. Entropy 19 (12):656. https://keep.lib.asu.edu/items/127939. doi: 10.3390/e19120656.
- Humerick, M. 2018. Taking AI personally: How the E.U. must learn to balance the interests of personal data privacy & artificial intelligence. Santa Clara Computer and High-Technology Law Journal 34 (4):393. https://heinonline.org/hol-cgi-bin/get_pdf.cgi?handle=hein.journals/sccj34§ion=19&casa_token=FAmQb_XWcnkAAAAA:Lg3iMgt-9HbHHFJ5owF5eM3C9htaVL_WVjAVZk_zl-Kz5qjilVjzoBpqHyr-Rh8CNTwKnMw.
- IBM. 2022a. What is blockchain security. Accessed June 24. https://www.ibm.com/topics/blockchain-security.
- IBM. 2022b. Data security services. Accessed June 24. https://www.ibm.com/security/services/data-security.
- ISO. 2021. ISO/IEC TR 24028:2020 information technology - Artificial intelligence - Overview of trustworthiness in artificial intelligence. Nuevos Sistemas de Comunicación e Información. https://www.iso.org/standard/77608.html.
- Jaffee, S., S. Henson, L. Unnevehr, D. Grace, and E. Cassou. 2019. The safe food imperative: accelerating progress in low- and middle-income countries. Washington, D.C.: World Bank Publications.
- Jayasena, D. D., H. J. Kim, H. I. Yong, S. Park, K. Kim, W. Choe, and C. Jo. 2015. Flexible thin-layer dielectric barrier discharge plasma treatment of pork butt and beef loin: Effects on pathogen inactivation and meat-quality attributes. Food Microbiology 46:51–7. www.who.int. doi: 10.1016/j.fm.2014.07.009.
- Kasiviswanathan, S. P., O. K. Lee, K. Nissim, S. Raskhodnikova, and A. Smith. 2011. What can we learn privately? SIAM Journal on Computing 40 (3):793–826. doi: 10.1137/090756090.
- Kaur, D., S. Uslu, K. J. Rittichier, and A. Durresi. 2022. Trustworthy artificial intelligence: A review. ACM Computing Surveys 55 (2): 1–38.
- Kovac, J., H. den Bakker, L. M. Carroll, and M. Wiedmann. 2017. Precision food safety: A systems approach to food safety facilitated by genomics tools. TrAC Trends in Analytical Chemistry 96:52–61. doi: 10.1016/j.trac.2017.06.001.
- Kuehn, B. M. 2014. Agencies use social media to track foodborne illness. Jama 312 (2):117–8. https://jamanetwork.com/journals/jama/article-abstract/1885471?casa_token=OcqtWxLWWQ0AAAAA:Ts0nat3RRMkmcEjD2atWCoBO9aSDThyskUmNIo-weSuqpVcQkeVn3P3pmNqtEHfYRbM5Nzr5.
- Lammerding, A. M. 1997. An overview of microbial food safety risk assessment. Journal of Food Protection 60 (11):1420–5.
- Liu, C., V. Manstretta, V. Rossi, and H. J. Van Der Fels-Klerx. 2018. Comparison of three modelling approaches for predicting deoxynivalenol contamination in winter wheat. Toxins 10 (7):267. https://www.mdpi.com/2072-6651/10/7/267/htm. doi: 10.3390/toxins10070267.
- Marvin, H. J. P., Y. Bouzembrak, E. M. Janssen, H. J. van der Fels- Klerx, E. D. van Asselt, and G. A. Kleter. 2016. A holistic approach to food safety risks: Food fraud as an example. Food Research International (Ottawa, Ont.) 89 (Pt 1):463–70. doi: 10.1016/j.foodres.2016.08.028.
- Mcnab, W. B. 1998. A general framework illustrating an approach to quantitative microbial food safety risk assessment. Journal of Food Protection 61 (9):1216–28.
- Mirel, L. 2021. Privacy preserving techniques: Case studies from the data linkage program. https://stacks.cdc.gov/view/cdc/114623/cdc_114623_DS1.pdf.
- Møller, F. T., K. Mølbak, and S. Ethelberg. 2018. Analysis of consumer food purchase data used for outbreak investigations, a review. Eurosurveillance 23 (24):1700503. https://pubmed.ncbi.nlm.nih.gov/29921346/. doi: 10.2807/1560-7917.ES.2018.23.24.1700503.
- Narayanan, A, and V. Shmatikov. 2008. Robust de-anonymization of large sparse datasets. Proceedings - IEEE Symposium on Security and Privacy, 111–25. https://ieeexplore.ieee.org/abstract/document/4531148/?casa_token=RFcnjy7sGGcAAAAA:19goZYUkddBuN UdLyBa3HkFupbn4KveTLO-T_aSeyPHAT10_zD_DbBJ93oW20ovLnHUjPPI.
- Nasirahmadi, A, and O. Hensel. 2022. Toward the next generation of digitalization in agriculture based on digital twin paradigm. Sensors 22 (2):498. https://www.mdpi.com/1424-8220/22/2/498/htm. doi: 10.3390/s22020498.
- Nepveux, M. 2021. USDA report: U.S. dairy farm numbers continue to decline. https://www.fb.org/market-intel/usda-report-u.s.-dairy-farm-numbers-continue-to-decline.
- Norström, M., A. B. Kristoffersen, F. S. Görlach, K. Nygård, and P. Hopp. 2015. An adjusted likelihood ratio approach analysing distribution of food products to assist the investigation of foodborne outbreaks. Plos One 10 (8):e0134344. doi: 10.1371/journal.pone.0134344.
- Noyes, K. 2016. 5 Things you need to know about data exhaust. Cio (13284045). http://search.ebscohost.com/login.aspx?direct=true&db=bth&AN=115348398&lang=pt-br&site=ehost-live.
- Oldroyd, R. A., M. A. Morris, and M. Birkin. 2018. Identifying methods for monitoring foodborne illness: review of existing public health surveillance techniques. JMIR Public Health and Surveillance 4 (2):e8218. https://publichealth.jmir.org/2018/2/e57.
- Polat, H., Z. Topalcengiz, and M. D. Danyluk. 2020. Prediction of Salmonella presence and absence in agricultural surface waters by artificial intelligence approaches. Journal of Food Safety 40 (1):e12733. doi: 10.1111/jfs.12733.
- Reiser, L., L. Harper, M. Freeling, B. Han, and S. Luan. 2018. FAIR: A call to make published data more findable, accessible, interoperable, and reusable. Molecular Plant 11 (9):1105–8. doi: 10.1016/j.molp.2018.07.005.
- Resnick, D. M., C. S. Cox, and L. B. Mirel. 2021. Using synthetic data to replace linkage derived elements: A case study. Health Services & Outcomes Research Methodology 21 (3):389–406. doi: 10.1007/s10742-021-00241-z.
- Rieke, N., J. Hancox, W. Li, F. Milletarì, H. R. Roth, S. Albarqouni, S. Bakas, M. N. Galtier, B. A. Landman, K. Maier-Hein, et al. 2020. The future of digital health with federated learning. Npj Digital Medicine 3 (1):1–7 doi: 10.1038/s41746-020-00323-1.
- Robbins, R. 2021. JBS Paid $11 Million ransom to hackers. The New York Times. https://www.nytimes.com/2021/06/09/business/jbs-cyberattack-ransom.html.
- Sadilek, A., S. Caty, L. DiPrete, R. Mansour, T. Schenk, M. Bergtholdt, A. Jha, P. Ramaswami, and E. Gabrilovich. 2018. Machine-learned epidemiology: Real-time detection of foodborne illness at scale. Npj Digital Medicine 2018 1:1(1):1–7. https://www.nature.com/articles/s41746-018-0045-1.
- Sadilek, A., H. Kautz, L. Di Prete, B. Labus, E. Portman, J. Teitel, and V. Silenzio. 2017. Deploying nemesis: Preventing foodborne illness by data mining social media. AI Magazine 38 (1):37–48. https://www.aaai.org/ocs/index.php/IAAI/IAAI16/paper/viewFile/11823/12317. doi: 10.1609/aimag.v38i1.2711.
- Santos, J, and S. Matos. 2013. Predicting flu incidence from Portuguese Tweets. Proceedings of IWBBIO, 18–20. http://iwbbio.ugr.es/papers/iwbbio_002.pdf.
- Sullivan, G., C. Zoellner, M. Wiedmann, and R. Ivanek. 2021. In silico models for design and optimization of science-based listeria environmental monitoring programs in fresh-cut produce facilities, ed. Edward G. Dudley. Applied and Environmental Microbiology 87 (21):e007992110.1128/AEM.00799-21.
- Sweeney, L. 2002. K-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10 (05):557–70. doi: 10.1142/S0218488502001648.
- Tack, D. M., L. Ray, P. M. Griffin, P. R. Cieslak, J. Dunn, T. Rissman, R. Jervis, S. Lathrop, A. Muse, M. Duwell, et al. 2020. Preliminary incidence and trends of infections with pathogens transmitted commonly through food — Foodborne diseases active surveillance network, 10 U.S. Sites, 2016–2019. MMWR. Morbidity and Mortality Weekly Report 69 (17):509–14.
- Tebaldi, L., G. Vignali, and E. Bottani. 2021. Digital twin in the agri-food supply chain: A Literature review. IFIP Advances in Information and Communication Technology. 633 IFIP: 276–283. 10.1007/978-3-030-85910-7_29.
- Waithira, N., B. Mutinda, and P. Y. Cheah. 2019. Data management and sharing policy: The first step towards promoting data sharing. BMC Medicine 17 (1):1–5. doi: 10.1186/s12916-019-1315-8.
- Wang, X., Y. Bouzembrak, A. Lansink, and H. J. van der Fels-Klerx. 2022. Application of machine learning to the monitoring and prediction of food safety: A review. Comprehensive Reviews in Food Science and Food Safety 21 (1):416–34. doi: 10.1111/1541-4337.12868.
- Warner, S. L. 1965. Randomized response: A survey technique for eliminating evasive answer bias. Journal of the American Statistical Association 60 (309):63–9.
- Wei, K., J. Li, M. Ding, C. Ma, H. H. Yang, F. Farokhi, S. Jin, T. Q. S. Quek, and H. Vincent Poor. 2020. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Transactions on Information Forensics and Security 15:3454–69. doi: 10.1109/TIFS.2020.2988575.
- Weller, D., A. Belias, H. Green, S. Roof, and M. Wiedmann. 2020a. Landscape, water quality, and weather factors associated with an increased likelihood of foodborne pathogen contamination of New York streams used to source water for produce production. Frontiers in Sustainable Food Systems 3:124. doi: 10.3389/fsufs.2019.00124.
- Weller, D. L., T. M. T. Love, A. Belias, and M. Wiedmann. 2020b. Predictive models may complement or provide an alternative to existing strategies for assessing the enteric pathogen contamination status of northeastern streams used to provide water for produce production. Frontiers in Sustainable Food Systems 4:151. doi: 10.3389/fsufs.2020.561517.
- Wilensky, U, and Rand, W. 2015. An introduction to agent-based modeling: modeling natural, social, and engineered complex systems with NetLogo. Cambridge, Massachusetts: Mit Press,.
- Zoellner, C., R. Jennings, M. Wiedmann, and R. Ivanek. 2019. EnABLe: An agent-based model to understand listeria dynamics in food processing facilities. Scientific Reports 9 (1):495. doi: 10.1038/s41598-018-36654-z.